CUDA 003 - GPU 硬件基础
背景
在硬件实现层面,CPU 追求以少量的核心高效地运行,CPU 通常只包含几十个核心,为了让这些核心高速运行,CPU 加入多级缓存,在指令执行层面,使用指令流水线、分支预测、乱序执行、超线程等技术来提高执行速度。而 GPU 则包含成千上万个核心,每个核心和 CPU 的核心比起来,功能要简单不少,GPU 更多是加载大量的数据,然后使用大量的核心执行批量处理。虽然 GPU 的时钟频率比 CPU 低,但是因为同时处理的数据量更大,所以 GPU 有更大的吞吐量。
下面的图中对比了 CPU 和 GPU 的架构差异。
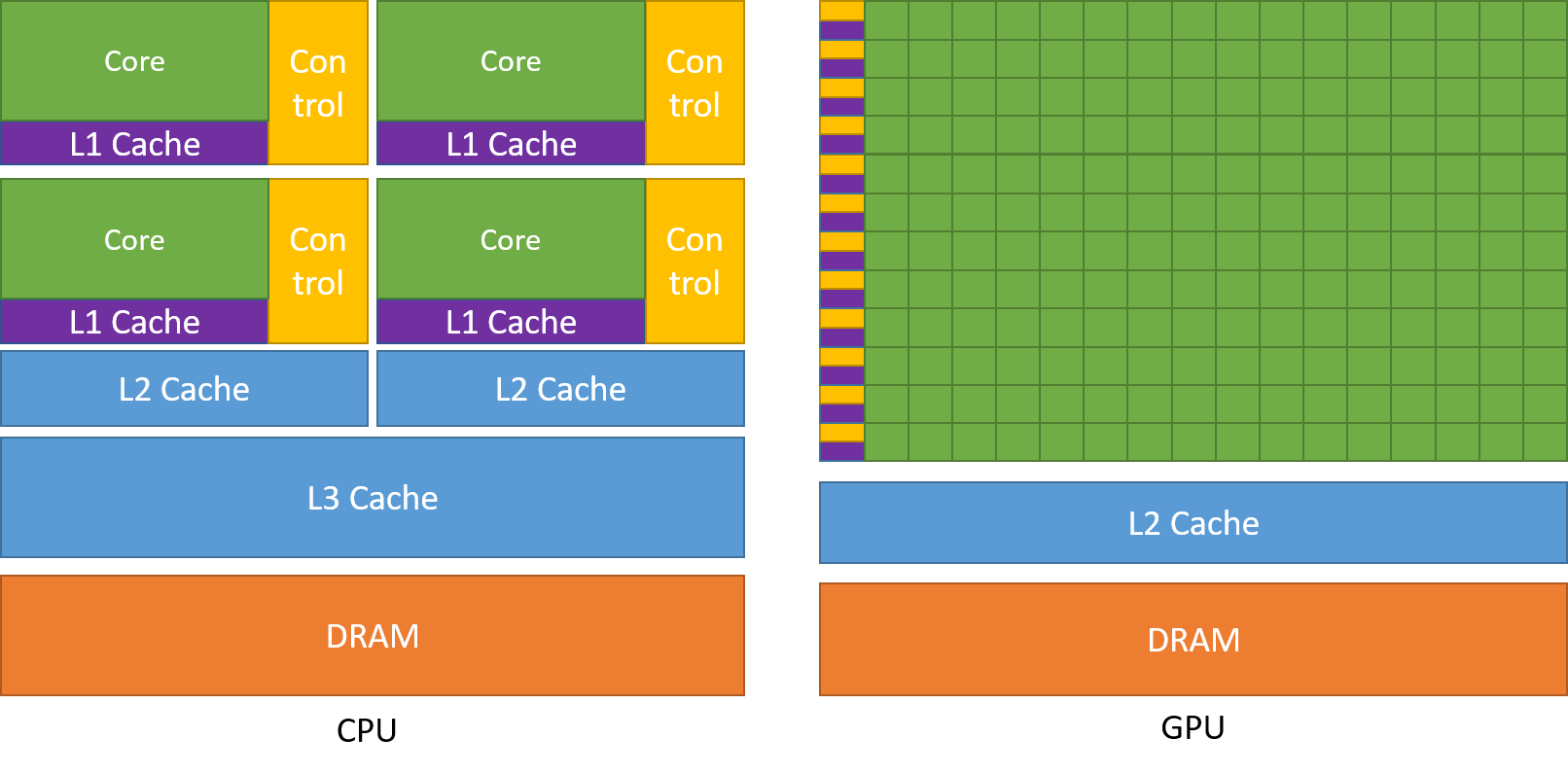
GPU 和 CPU 的主要区别如下表:
| CPU | GPU | |
|---|---|---|
| 核心数量 | 几十个 | 成千上万个 |
| 时钟频率 | 高 | 低 |
| 指令延迟 | 低 | 高 |
| 并行 | 指令级别 | 线程级别 |
| 寄存器数量 | 少 | 多 |
| 执行顺序 | 乱序执行 | 顺序执行 |
| 执行控制 | 复杂 | 简单 |
| 内存一致性 | 硬件控制 | 软件控制 |
CPU 主要负责处理控制流和数据依赖,CPU 的时钟频率更高,CPU 优化的方向是让指令执行得更快。而 GPU 时钟频率相对 CPU 更低,但 GPU 核心数量更多,它可以同时处理更多的数据,GPU 的吞吐量则更大。
GPU 就像是装载集装箱的远洋货轮,它行驶的速度虽然不快,但是它能装载更多的货物,它追求的是更大的吞吐量。而 CPU 就像是飞机,它快速灵活,但装载量有限,它追求的是更快的处理速度。如果你有大量的数据需要处理,那么 GPU 会更加适合,就像你需要运输大量的货物时,你会选择货轮来运输,而不是使用飞机跑很多趟。但如果你只有少量的数据需要计算,那么 CPU 则更加适合。
计算模式
线程在软件开发的视角中,它是一个执行流,它可能代表一个正在执行的程序。每个线程都有自己的指令指针(PC/IP),线程可以被 CPU 调度执行,它是 CPU 调度执行的最小单位。在 GPU 视角里,线程的概念有点不同,在 GPU 中没有应用程序的概念,有的只是大量的计算任务,这些任务就是提交到 GPU 执行的 GPU 计算指令。而线程就是最小的执行单元,用户可以将任务划分为很多份,而线程就代表最基本的执行单元。
考虑将两个数相加的例子,如果使用 CPU,那么可以创建一个线程来执行这个任务,在该线程中,可以逐个遍历数组中的元素,并执行相加。如果你想要加速,你可以创建多个线程,每个线程处理数组的一部分。但因为核心有限,你能创建的线程数量也是有限的,如果线程过多还会带来负面的影响。而如果使用 GPU,可以为每个元素创建一个线程,每个线程执行对应位置元素的加法操作,将结果写回去,这样整个任务就完成了。这就是 GPU 和 CPU 在计算模式上的区别。
后文中将从硬件实现的视角来介绍 GPU 的架构设计,帮助理解 GPU 是如何实现大量线程的并行执行的。
GPU 与 CPU 连接方式
以我自己的机器为例,我用的 CPU 是 Intel i5-14600KF,用的是 MSI 的 MAG B760M MORTAR WIFI II 主板,GPU 是 NVIDIA RTX 5070。
这是机器主板:

图中中上部黑色部分安装 CPU,右下角白色覆盖部分安装芯片组(chipset)。这个主板使用 Intel 700 系列芯片组。
下面是 Intel 700 系列芯片组的结构图。CPU 直接和 DDR4/DDR5 内存相连,CPU 提供了 16x PCIe 5.0 通道,通常用于和 GPU 连接。与 CPU 直接连接的都是高带宽、低时延的设备。其他的外设则连接到芯片组(chipset)上,该芯片组通过 DMI (Direct Media Interface,一种 CPU 和 chipset 通信的接口) 连接到 CPU 上。
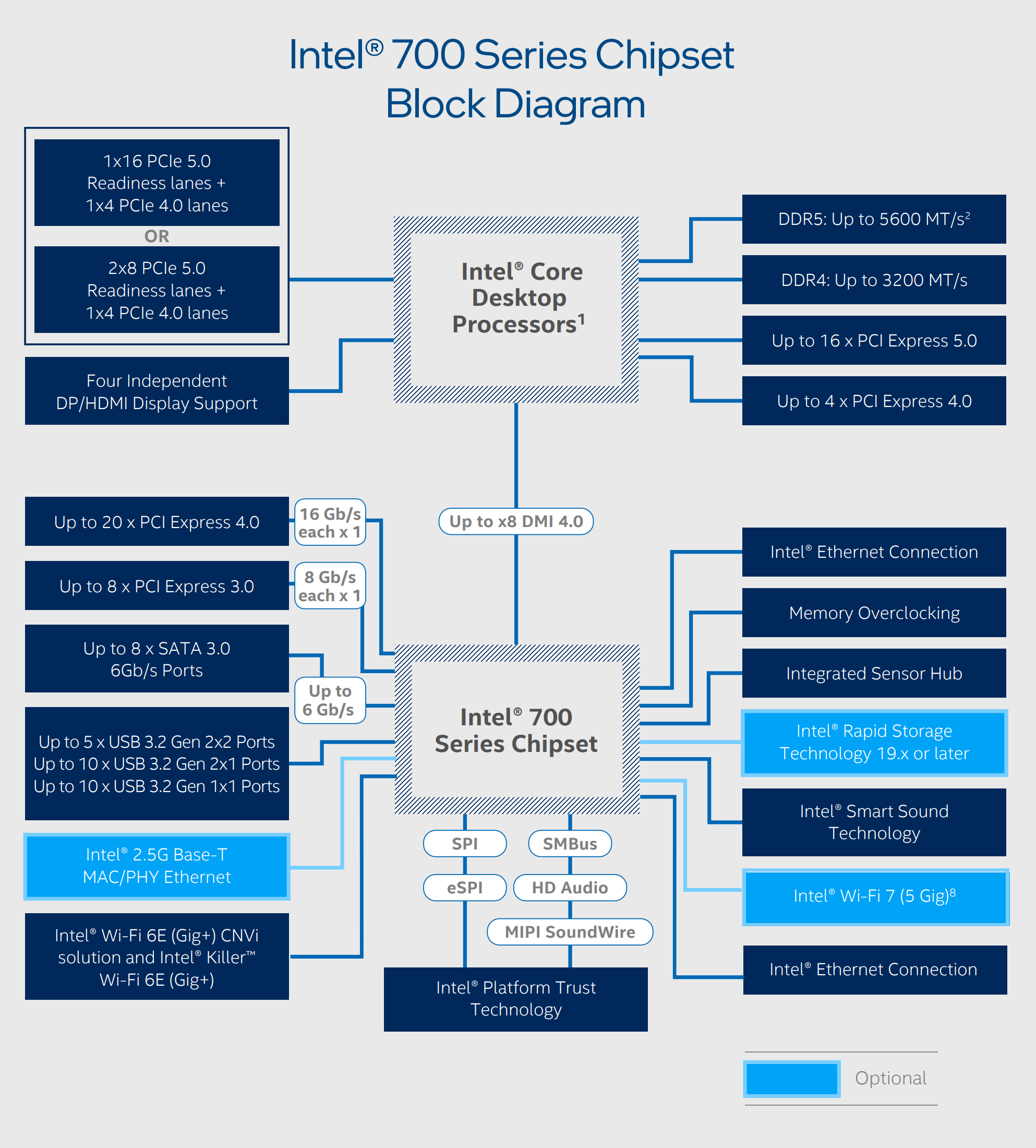 来自 Intel® 700 Series Chipset Brief
来自 Intel® 700 Series Chipset Brief
下面这张图是 MSI 的主板各设备的连接图,CPU 直接连接 DDR5 内存、M2 固态硬盘和显卡。
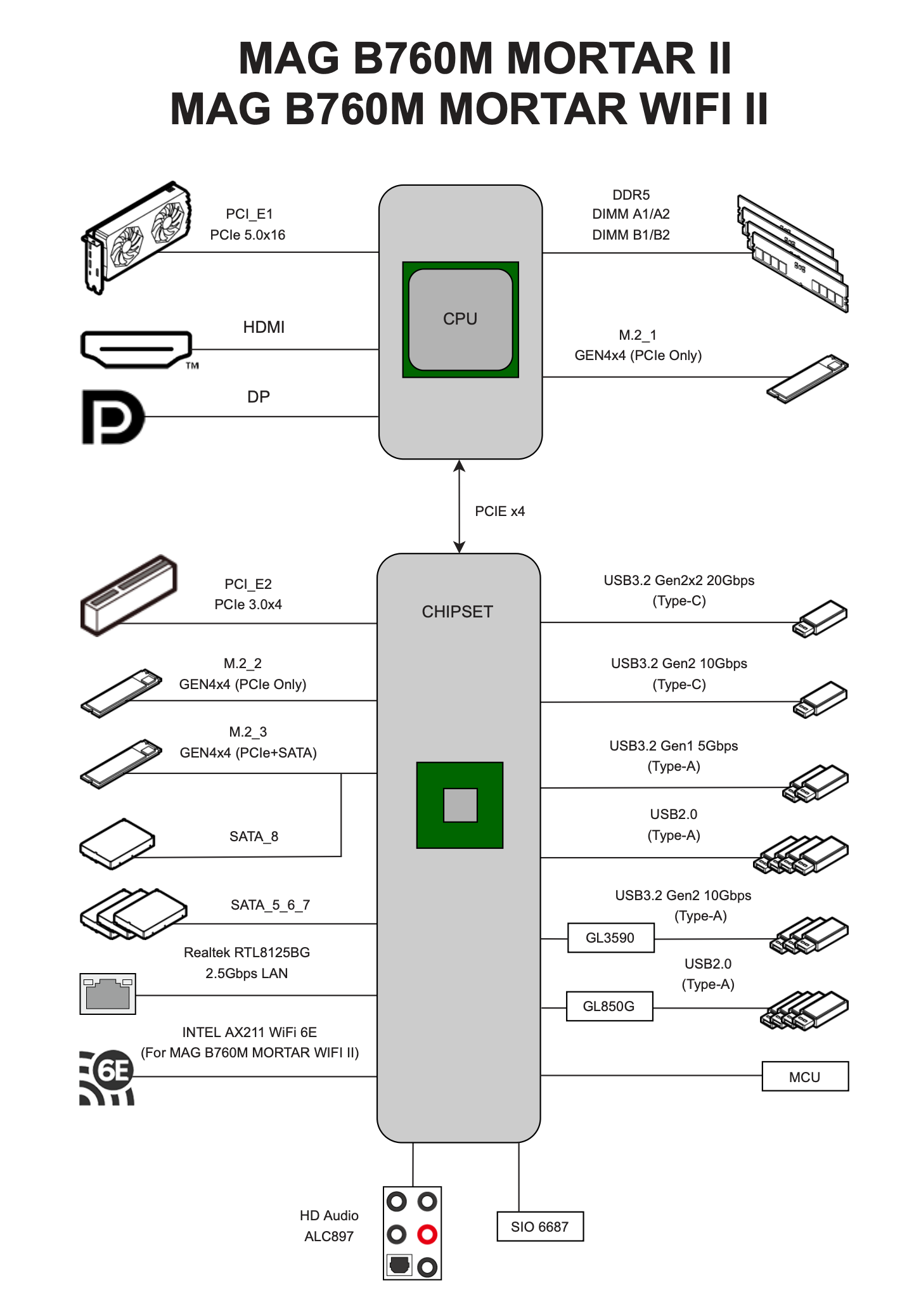 来自 MAG B760M MORTAR WIFI II User Guide
来自 MAG B760M MORTAR WIFI II User Guide
PCIe(Peripheral Component Interconnect Express) 是一种高速串行计算机扩展总线标准,用于连接计算机系统中的各种设备。最初由 Intel 和 Compaq 在 2003 年推出,PCIe 的每一个版本都将带宽翻倍。下面是 PCIe 各个版本的理论最大带宽:
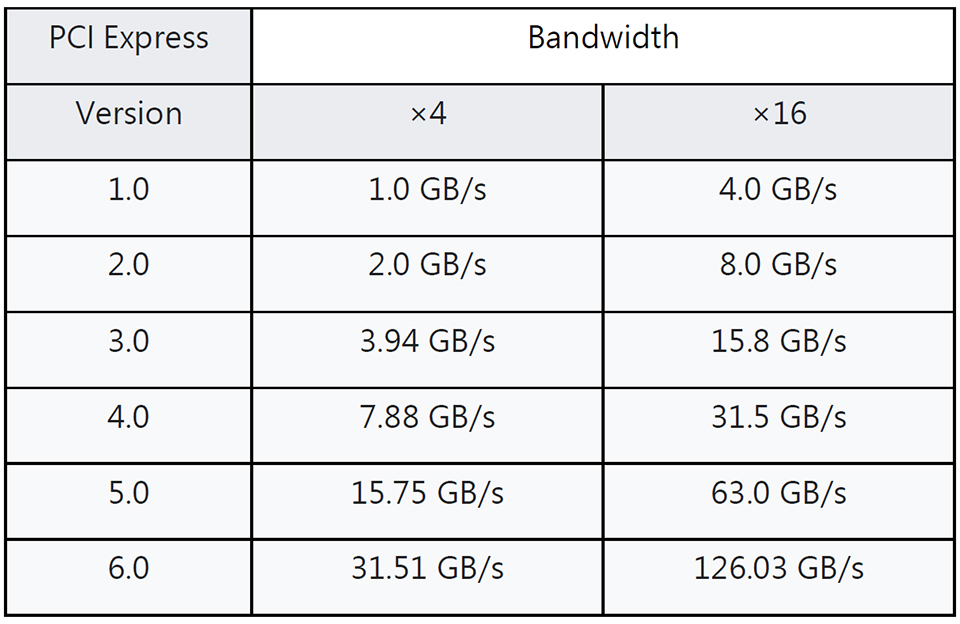 source: https://www.msi.com/blog/pcie-gen5-ssd-complete-guide
source: https://www.msi.com/blog/pcie-gen5-ssd-complete-guide
注意:PCIe 有多种通道(lane)数量,比如 1 通道、2 通道、4 通道、8 通道、16通道等。通道数越多,总的传输量也就越大。上表中列出的是 4 通道和 16 通道的带宽
我的 GPU 使用的是 16 通道的 PCIe 5.0 连接,理论带宽为 63GB/s。
显卡主板
显卡内部包含 GPU 芯片、显存、电源管理模块、散热模块等。显卡主板上有 PCIe 接口,用于和计算机主板连接。显卡主板上还有电源管理模块,用于为 GPU 和显存提供稳定的电源供应。显卡主板上还包含散热模块,用于散热 GPU 和显存,保持其在安全的温度范围内工作。

显卡内部的主板如下图所示:
 MSI GeForce RTX 5070 Gaming Trio OC Review
MSI GeForce RTX 5070 Gaming Trio OC Review
可以看到显卡的主板简单很多,中间蓝色部分就是 RTX 5070 GPU。GPU 周围是 GDDR7 内存,一共有 8 个位置,但只安装了 6 个,所以是 12 GB 内存。主板的左侧是供电电路部分,可以看到有 12 颗电源芯片。
GDDR7(Graphics Double Data Rate 7 Synchronous Dynamic Random-Access Memory,即 GDDR7 SDRAM)内存是专门为 GPU 设计的内存。和 CPU 使用的内存相比,GDDR SDRAM 的带宽更大,时延则相对更高。CPU 内存追求的是低时延,因为执行 CPU 指令需要更快地访问内存。而 GPU 追求的是更高的带宽,因为 GPU 核心数量多,需要更大的吞吐量。
GPU 硬件架构
下面我们深入到 GPU 内部,了解 GPU 的硬件架构。目前最新的 GPU 架构代号是 Blackwell,它是 NVIDIA 的第 12 代 GPU 架构。这里的内容主要来自 NVIDIA RTX BLACKWELL GPU ARCHITECTURE。
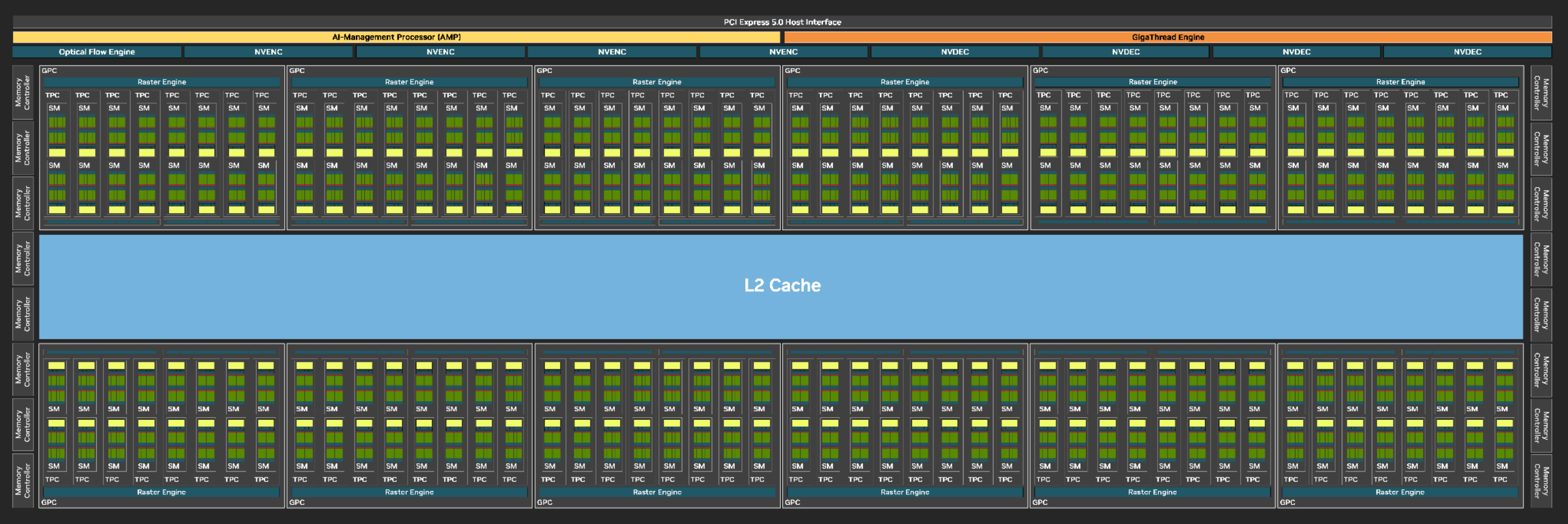
上面是 Blackwell GB202 GPU 的架构图。GB202 GPU 包含 12 Graphics Processing Clusters (GPCs),每个 GPC 包含 8 Texture Processing Clusters (TPCs)。每个 TPC 包含 两个 Streaming Multiprocessors(SM)。GPU中还包含内存控制器、视频编解码引擎等其他硬件模块。
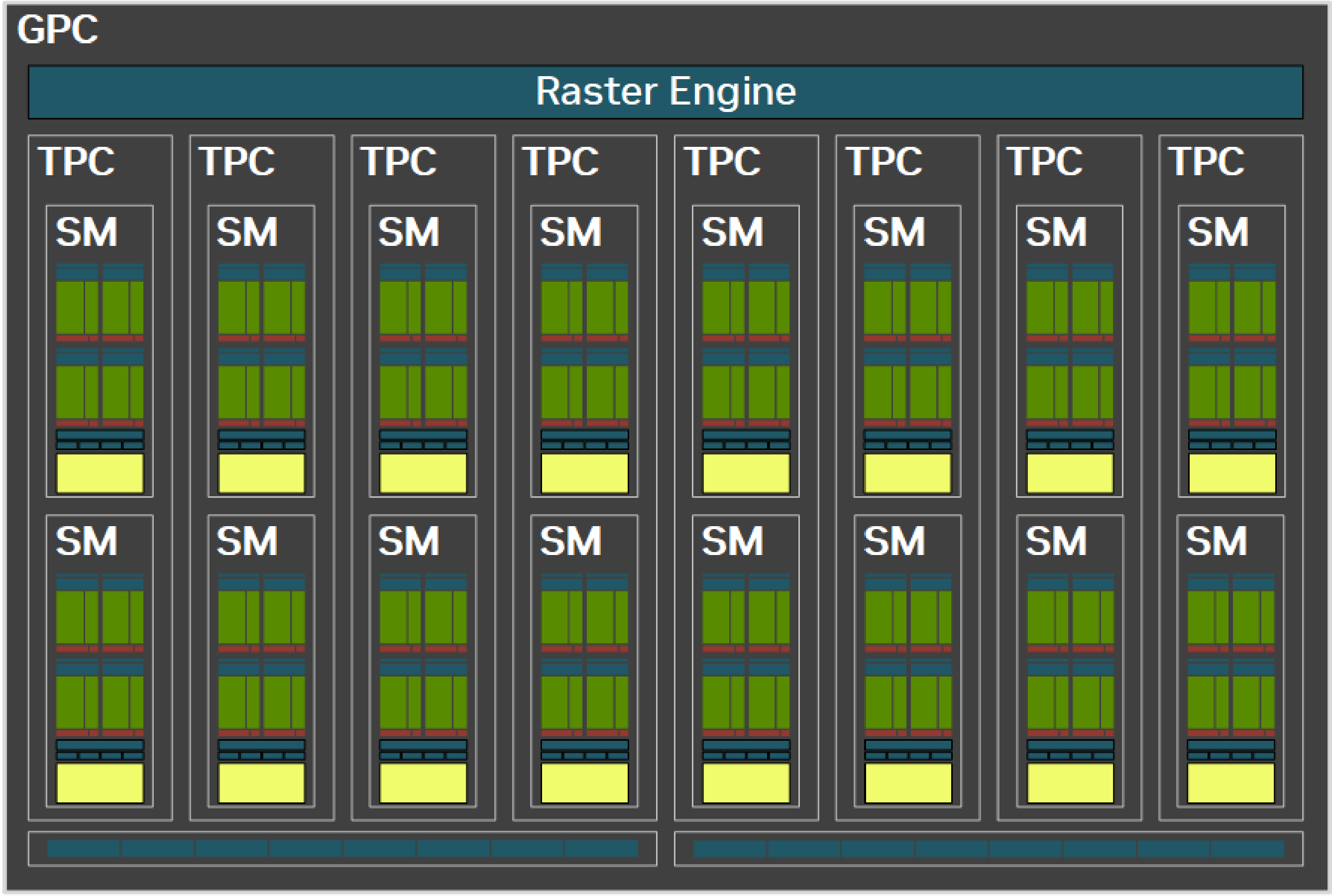
不同型号的 GPU 里面包含不同数量的 GPC。每个 GPC 包含 8 TPC,每个 TPC 包含 2 SM。GPU 最初是为图形渲染设计的,现在虽然支持通用计算,但它里面依然包含用于图形渲染的功能。比如上图中的 Raster Engine,它就是用来进行图形渲染的。而 TPCs 和 GPCs 也是为图形渲染设计的。这里我们主要关注 GPU 中的计算单元 SM,它是 GPU 中执行计算任务的核心。
Streaming Multiprocessors
如下图所示,每个 SM 被划分为 4 个处理单元(通常被称为 processing block 或者 partition),在 Kepler 架构中,SM 并不包含多个 processing block,而要想增强单个 SM 的计算能力,就只能在 SM 中增加更多的计算单元,但这增加了指令调度执行的复杂度。因此从 Maxwell 架构开始,每个 SM 中包含多个 processing block,将 SM 中的计算资源划分为多个 processing block,可以提升 SM 的计算能力,同时降低指令调度的复杂度。

从宏观上来看,SM 就像是一个多核处理器,它包含多个处理单元,每个处理单元都包含一些 ALU/FPU 计算单元、数据读写单元、特殊功能单元(SFUs, Special Function Units)、Tensor core 等一套完整的计算资源,可以独立地调度执行线程。
CUDA Cores
CUDA Core 能够执行整数或浮点运算,它的内部有用于执行浮点运算的浮点单元(FPU, Floating Point Unit),以及用于执行整数运算的整数单元(ALU, Arithmetic Logic Unit)。
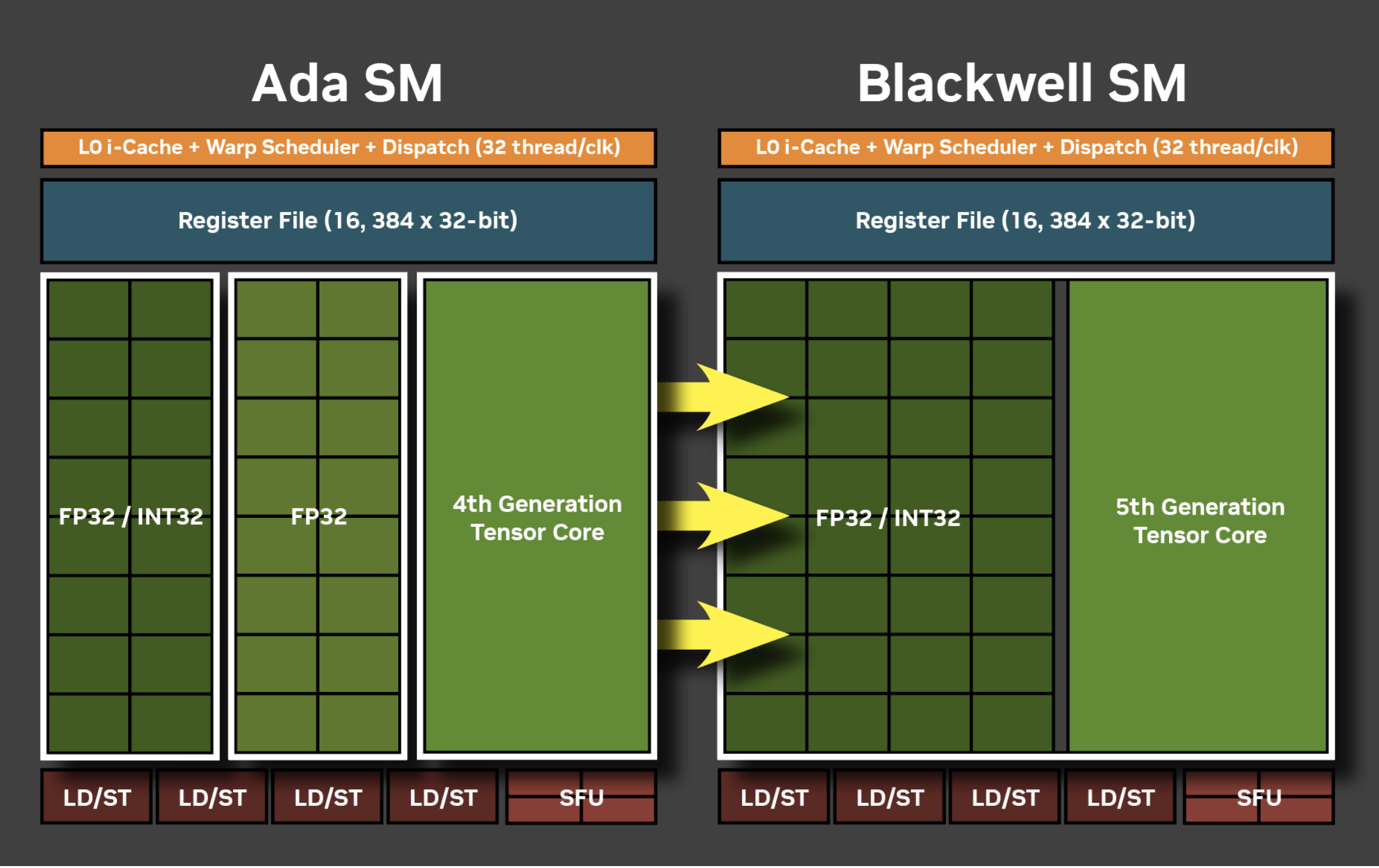
CUDA Cores 中包含 32 个 FP32/INT32 计算单元,用于执行数学运算。这 32 个计算单元可以支持 32 个线程同时执行 FP32/INT32 的运算。上图表示 Blackwell 架构中,原来只能执行 FP32 的计算单元现在可以做 INT32 计算,因此现在包含了 32 个可以执行 FP32/INT32 的计算单元。
CUDA core 的结构远比 CPU core 简单,但是相比之下它的数量很多。在 RTX 5070 上,一共有 6144 个 CUDA Core,而我使用 i5 14600KF 只有 20 个 core。因此,在数值计算这件事情上,GPU 可以同时启动更多的线程,即便 CUDA core 的能力稍逊,但因为数量足够多,单位时间内可以执行更多的计算任务。
Tensor Cores
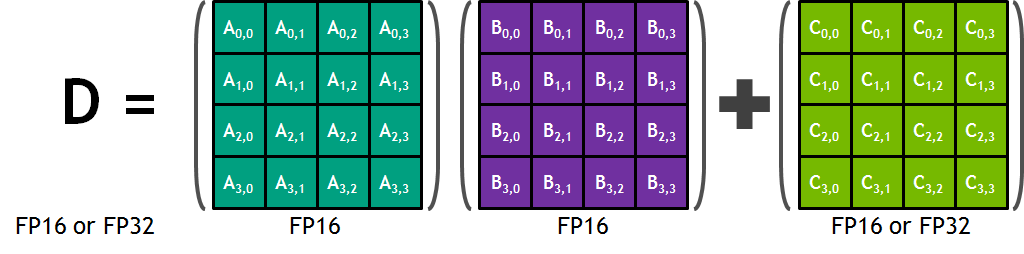
矩阵乘法是 GPU 中大量执行的一类计算任务,但矩阵乘法运算需要大量计算,两个 4x4 矩阵相乘需要 64 次乘加操作。为了提升矩阵计算效率,GPU 引入了 Tensor core。Tensor core 使用硬件实现了矩阵乘加操作。虽然只能处理小块的矩阵,但在软件实现矩阵乘加操作时,会用分块运算的方式,把大矩阵分成小矩阵完成计算,因此 Tensor core 可以高效地起到加速的作用。
SFUs (Special Function Units)
CUDA Cores 中的整型和浮点计算单元主要用来执行数值计算,做最为通用的加、减、乘、左移、右移等运算。而一些常用的数学运算,如三角函数、指数函数、开方等,虽然也可以按照对应算法使用 CUDA Cores 来执行,但是这样效率很低。SFUs 使用硬件实现了这些常用的数学函数,专门用来加速这些常用的数学运算。
数据读写单元 (LD/ST, Load and Store Unit)
执行计算总需要有数据参与,因此需要有硬件单元来执行数据加载和写入操作,这个硬件单元叫做 LD/ST Unit(Load and Store Unit)。如果多个线程都需要执行数据读写操作,且读取的数据地址是连续的,LD/ST 单元可以对来自不同的 thread 的连续内存读写操作进行合并,使用批处理的方式利用 GPU 内存高带宽的特性一次加载大量数据。
数据读写单元(LD/ST)专门用来执行内存读写操作,它的数量相对较少,这是因为 LD/ST 单元可以对来自不同的 thread 的连续内存读写操作进行合并,使用批处理的方式利用 GPU 内存高带宽的特性一次加载大量数据。即使耗时可能比较久,也可以通过让调度器切换执行其他的 warp 来隐藏延迟。
寄存器文件 (Register File)
指令执行需要有寄存器来保存数据。CPU 中有寄存器,GPU 中也有,而且 GPU 中有更多的寄存器。每个 SM 中都包含一块很大的寄存器文件。
L1 Data Cache / Shared Memory
要提升执行效率,需要引入缓存。在 SM 中包含数据缓存和指令缓存。线程执行时,有可能需要相互协作,线程之间会交换数据。在 CPU 中线程之间可以使用主存来共享数据,但这引入了缓存一致性的问题,原因是运行在多个 CPU core 上的线程之间可以共享数据。在 GPU 中,只有处于同一个 SM 内的线程之间才能共享数据。在 SM 中引入共享内存,这样可以支持线程间的数据共享,同时无需考虑缓存一致性问题。
TMA (Tensor Memory Accelerator)
TMA 是一种专门用来加速 Tensor core 读写数据的硬件单元。Tensor core 在执行矩阵乘加操作时,需要频繁地读写数据,如果使用普通的 LD/ST 单元来读写数据,效率会比较低。TMA 可以加速 Tensor core 读写数据的效率,从而提升矩阵计算的性能。
调度器
NVIDIA 的 GPU 中,开发者在写 CUDA 程序时,会将线程组织成一个线程块,然后 SM 调度执行这些线程块。在 SM 内部线程块再被分为多组,每一组叫做一个 warp,每个 warp 有 32 个线程。每个 warp 中的 32 个线程会以 SIMT (Single Instruction, Multiple Threads) 的方式执行。在 SIMT 模型下,多个线程会执行相同的指令,但每个线程会处理不同的数据。

线程被分为多个 warp,每个 warp 内的线程并行执行。不同的 warp 执行的进度可能是不一样的,每个 warp 都有自己的指令指针。调度器会根据当前硬件资源的使用情况,以及各个 warp 当前是否就绪来确定在一个给定时间点,需要执行哪一个 warp。

当一个 warp 被耗时操作阻塞时,可以调度执行其他 warp。比如访问内存可能会比较慢,当一个 warp 执行了访存指令后,在数据传输期间,可以切换到其他 warp 上执行。当后续数据就位后,可以再切换到此 warp 上执行。这种方式可以降低时延带来的影响,让 GPU 持续工作而不用因为等待数据而停止运行。
在 CUDA cores 中有足够多的硬件资源来完成对 32 个线程的并行计算,但如果所有线程都需要使用到 LD/ST Unit 或者 SFUs,那么一个 warp 中的线程就需要分几批执行。但是在 warp 的维度来看,可以认为 warp 中的线程会并行执行。
SM 结构总结
上面的内容基本覆盖了 NVIDIA GPU 中 Streaming Multiprocessor 的主要结构,总结来看,SM 的主要结构如下图所示:

每个 SM 中包含多个 processing block,每个 block 都包含一套完整的硬件资源,可以独立地调度执行线程。SM 中还包含一个 RT(Ray Tracing) core,用于执行光线追踪,因为我也不是很懂,而且和通用计算关系不大,这里就不再说了。关于光线追踪的简单介绍可以看看这个视频。
以 H100 GPU 为例,它包含 144 个 SM,每个 SM 可以调度执行 2048 个线程,这些线程被划分为 64 个 warp,所有 warp 在 SM 内共享硬件资源交替调度执行。因此整个 GPU 则可以同时调度执行 144 x 2048 = 294,912 个线程。这就是为什么 GPU 能够处理大量并行计算任务的原因。
CPU 中通常只有几十个核心,而且因为线程切换的开销较大,CPU 中同时运行的线程数量也比较有限。而 GPU 中包含成千上万个核心,而且线程切换的开销较小,因此 GPU 可以同时调度执行大量的线程,从而提升计算吞吐量。
内存
GPU 的内存模型远比 CPU 的内存模型要简单。每个 SM 中包含 L1 cache,整个 GPU 共享一个 L2 cache。

其中 L1/L2 cache 集成在 CPU 内部,速度相对较快,GPU 的主存常常是外部的 GDDR 内存,速度较慢。最近这些年,为了加速 AI 的计算,高端的、用于数据中心的 GPU 比如 H100,为了降低 GPU 内存访问时延以及增大带宽,使用 HBM(High-Bandwidth Memory) 技术将内存集成到 GPU 芯片上,见下图:

在 GPU 核心旁边,将多块内存芯片垂直堆叠在一起。使用 TSVs(through-silicon vias) 技术,在 die 上打孔实现 GPU 芯片和 HBM 的互联。HBM 的总线比 GDDR 更宽,而且距离 GPU 更近,它可以提供高带宽和低延迟的内存访问。
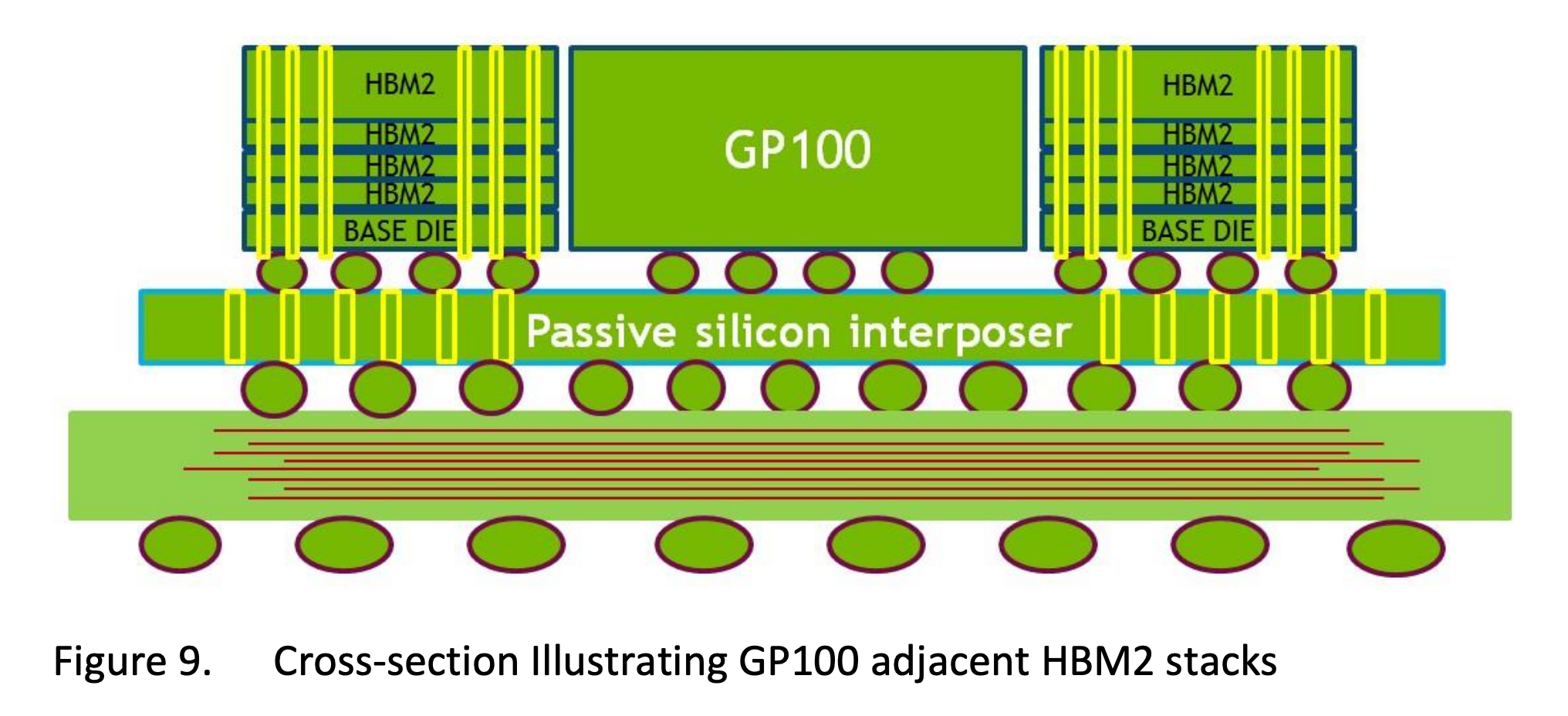
HBM 堆叠结构示意图
上层的 memory die 非常厚。在组装时,顶层 die 和 GPU 被磨平到相同的高度,以提供一个共面的表面用于散热器。每一个 memory die 的总线宽度为 512-bit。上图中每个 HBM 堆叠(stack)包含 4 个 memory die,GP100 GPU 连接了 2 个 HBM 堆叠,总的内存总线宽度为 4096-bit,内存读写频率为 700 MHz,理论带宽为 716.8 GB/s。
用于数据中心高性能计算的高端 GPU,比如 P100/V100/A100/H100,这类 GPU 都使用 HBM 内存,用于提供高带宽和低延迟的内存访问,而消费级显卡,比如 RTX 系列 GPU 都使用 GDDR 内存。
总结
本文简要介绍了 GPU 的硬件结构,但 GPU 的实现自然远远比这里描述的要复杂很多个数量级。本文只是站在软件开发的视角来从宏观上认识 GPU 的结构。这里推荐 Branch Education 制作的视频 How do Graphics Cards Work? Exploring GPU Architecture,它能让你更加生动地了解 GPU 的结构。另外就是阅读 NVIDIA 每一代架构的手册,这样可以了解它是如何逐步演进的到现在的架构的。
GPU 性能参数
下面是一些消费级显卡的参数,可以看一看,有个定量的认识:
| Graphics Card | RTX 3070 | RTX 4070 | RTX 5070 |
|---|---|---|---|
| GPU Codename | GA104 | AD104 | GB205 |
| GPU Architecture | NVIDIA Ampere | NVIDIA Ada Lovelace | NVIDIA Blackwell |
| GPCs | 6 | 5 | 5 |
| TPCs | 23 | 23 | 24 |
| SMs | 46 | 46 | 48 |
| CUDA Cores / SM | 128 | 128 | 128 |
| CUDA Cores / GPU | 5888 | 5888 | 6144 |
| Tensor Cores / SM | 4 (3rd Gen) | 4 (4th Gen) | 4 (5th Gen) |
| Tensor Cores / GPU | 184 (3rd Gen) | 184 (4th Gen) | 192 (5th Gen) |
| RT Cores | 46 (2nd Gen) | 46 (3rd Gen) | 48 (4th Gen) |
| GPU Boost Clock (MHz) | 1725 | 2475 | 2512 |
| Peak FP32 TFLOPS (nonTensor) | 20.3 | 29.1 | 30.9 |
| Memory Bandwidth | 448 GB/sec | 504 GB/sec | 672 GB/sec |
| L1 Data Cache/Shared Memory | 5888 KB | 5888 KB | 6144 KB |
| L2 Cache Size | 4096 KB | 36864 KB | 49152 KB |
| Register File Size | 11776 KB | 11776 KB | 12288 KB |
| Transistor Count | 17.4 Billion | 35.8 Billion | 31.1 Billion |
| Die Size | 392.5 mm2 | 294.5 mm2 | 263 mm2 |
| PCI Express Interface | Gen 4 | Gen 4 | Gen 5 |
| Manufacturing Process | Samsung 8 nm 8N | TSMC 4nm 4N | TSMC 4nm 4N |
数据来自: NVIDIA RTX BLACKWELL GPU ARCHITECTURE
下面是一些数据中心用于高性能计算的 GPU 的性能指标,包含了一个消费级显卡,用作对比:
| NVIDIA Tesla V100 | NVIDIA A100 40 GB (PCIe) | NVIDIA H100 NVL (PCIe) | NVIDIA RTX 4090 | |
|---|---|---|---|---|
| Length | 11 in / 267 mm | 11 in / 267 mm | 11 in / 268 mm | 13 in / 336 mm |
| Outputs | No outputs | No outputs | No outputs | 1x HDMI, 3x DisplayPort |
| Power Connectors | 2x 8-pin | 8-pin EPS | 8-pin EPS | 1x 16-pin |
| Slot width | Dual-slot | Dual-slot | Dual-slot | Triple-slot |
| TDP | 250 W | 250 W | 700 W | 450 W |
| - | ||||
| Boost Clock | 1380 MHz | 1410 MHz | 1837 MHz | 2520 MHz |
| GPU Clock | 1230 MHz | 765 MHz | 1665 MHz | 2235 MHz |
| Memory Clock | 1752 MHz | 2400 MHz | 5300 MHz | 21200 MHz |
| - | ||||
| Bus Interface | PCIe 3.0 x16 | PCIe 4.0 x16 | PCIe 5.0 x16 | PCIe 4.0 x16 |
| Generation | Tesla (Vxx) | Tesla (Axx) | Server Hopper (Hxx) | GeForce 40 |
| - | ||||
| DirectX | 12 Ultimate (12_1) | - | - | 12 Ultimate (12_2) |
| OpenCL | 1.2 | 2 | 3 | 3 |
| OpenGL | 4.6 | - | - | 4.6 |
| Shader Model | 6.4 | - | - | 6.7 |
| CUDA | 7 | 8 | 9 | 8.9 |
| - | ||||
| Architecture | Volta | Ampere | Hopper | Ada Lovelace |
| Die Size | 815 mm2 | 826 mm2 | 814 mm2 | 608 mm2 |
| GPU Name | GV100 | GA100 | GH100 | AD102-300-A1 |
| Process Size | 12 nm | 7 nm | 5 nm | 5 nm |
| Transistors | 21100 million | 54200 million | 80000 million | 76300 million |
| - | ||||
| Bandwidth | 897 GB/s | 1555 GB/s | 3360 GB/s | 1018 GB/s |
| Memory Bus | 4096 bit | 5120 bit | 5120 bit | 384 bit |
| Memory Size | 32 GB | 40 GB | 96 GB | 24 GB |
| Memory Type | HBM2 | HBM2e | HBM3 | GDDR6X |
| - | ||||
| ROPs | 128 | 160 | 24 | 192 |
| Shading Units/ CUDA Cores | 5120 | 6912 | 16896 | 16384 |
| TMUs | 320 | 432 | 528 | 512 |
| Tensor Cores | 640 | 432 | 528 | 512 |
| RT Cores | - | - | - | 128 |
| - | ||||
| FP16 (half) performance | 28.26 TFLOPS | 77.97 TFLOPS | 248.3 TFLOPS | 82.58 TFLOPS |
| FP32 (float) performance | 14.13 TFLOPS | 19.49 TFLOPS | 62.08 TFLOPS | 82.58 TFLOPS |
| FP64 (double) performance | 7066 GFLOPS | 9746 GFLOPS | 31040 GFLOPS | 1290 GFLOPS |
| Pixel Rate | 176.6 GPixel/s | 225.6 GPixel/s | 44.09 GPixel/s | 483.8 GPixel/s |
| Texture Rate | 441.6 GTexel/s | 609.1 GTexel/s | 969.9 GTexel/s | 1290 GTexel/s |