CUDA 001 - 初识 CUDA
最近这些年,生成式 AI 在高速发展并被广泛应用,模型的训练与推理都需要 GPU 提供强大的运算能力。最早接触深度学习时,我只会调用 PyTorch 的 API 来训练并使用模型,后来逐渐了解到 PyTorch 是通过 CUDA 来使用 GPU 的,而 CUDA 是 Nvidia 提供的并行计算平台和编程模型。
如果你想要使用 GPU 来加速你的计算,一种方式是使用像 PyTorch 这样的深度学习框架,它提供了方便的 API 来使用 GPU,另外一种方式是直接使用 CUDA 来编写程序。而现在我开启了 CUDA 的学习之旅,这会是一个从入门到精通的过程。
如果你对 GPU 还不是很了解,或者不足够了解,我强烈建议你看 Branch Education 制作的 How do Graphics Cards Work? Exploring GPU Architecture 这一视频。
GPU 简史
上世纪 90 年代,图形界面开始流行,随之而来的是对图形渲染的需求。CPU 开始不足以满足图形渲染的需求,半导体制造商们发现未来需要将图形处理的能力从 CPU 中分离出去,需要有额外的图形处理单元来执行图形渲染的任务。
有很多公司尝试做图形加速器,通常是一个额外的硬件和 CPU 协同,来做一些加速图形计算的工作。比如早期 CPU 的浮点运算能力很差,或者有的 CPU 还没有浮点数运算单元。图形扩展卡(Graphics Add-In Board)可以增强计算机的图形处理能力,尤其是早期 PC 的图形性能有限时,这类扩展卡能大幅提升 2D 或 3D 图形的渲染、处理效率。
但在早期需要这种 2D 或者 3D 加速的软件还比较少,而且 CPU 的性能也还在逐渐增强,以至于图形扩展卡并没有得到广泛的应用。当然 CPU 能力的增强会让人们能开发出更复杂的软件,各类软件对图形渲染的要求越来越高,直到某个时候,图形扩展卡不再是一个可选项,而是计算机系统必备的硬件。
1999 年,NVIDIA 发布了 GeForce 256 系列显卡,它将图形变换、光照、渲染等 3D 图形处理的关键步骤集成到一个芯片中,无需依赖 CPU 分担大量计算。这是 GPU 第一次出现在大众的视野中,并且从此改变了计算机图形处理的格局。
十几年前买电脑的时候,我们以为只要有一块主板,上面插上 CPU、内存条、硬盘,然后接上显示器、鼠标、键盘等等就可以用了,很多人都不知道显卡的存在。 但现在你买电脑的时候,你大概率会关心你要使用什么型号的显卡,你往往需要花大价钱买上一块显卡。我现在使用的电脑,总价 8000 左右,而显卡就占了将近一半的价格。显卡是包含外围电子元件的计算机外设,而 GPU 则是显卡中使用的核心芯片,但后文中常常也用 GPU 指代前者,要根据上下文区分。
 NVidia RTX5070 - 显卡
NVidia RTX5070 - 显卡
什么是 CUDA
GPU 最初是为了加速图形渲染而设计的,因此它提供的接口主要是针对图形渲染的 API。但是随着技术的发展,GPU 的计算能力越来越强,已经可以胜任很多复杂的数值计算任务。比如深度学习、科学计算等领域,都需要大量的数值计算。为了满足这些需求,GPU 需要提供一种通用的编程接口来支持各种不同的应用场景。于是 NVIDIA 在 2006 年推出了 CUDA(Compute Unified Device Architecture),这是一个用于通用计算的并行计算平台和编程模型。CUDA 提供了一个类似于 C 的语言来编写程序,让开发者可以很方便地利用 GPU 进行各种计算任务。
你可以把 CUDA 理解一个方便用户使用 GPU 的一整套解决方案,它允许开发者使用类似于 C 的语言来编写程序,并通过编译器将代码编译成可以在 GPU 上执行的指令。CUDA 提供了一系列库和工具,让开发者可以很方便地利用 GPU 进行各种计算任务。CUDA 提供的接口和概念可以理解为是对 GPU 的软件抽象,让开发者可以不用关心 GPU 的硬件细节。在编写 CUDA 程序时,只需要知道 CUDA 给你提供了哪些函数,以及如何使用这些函数就可以了。

CUDA 环境的配置
首先你需要有一块支持 CUDA 的 GPU,然后你需要安装 NVIDIA 提供的驱动和 CUDA Toolkit。CUDA Toolkit 包含了编译器、库文件、调试工具等,这些都是编写和使用 CUDA 程序所必需的。
通常你的机器已经安装了 NVIDIA GPU 的驱动,你可以使用 nvidia-smi 命令来查看你的 GPU 的型号。
$ nvidia-smi
Fri Nov 14 07:00:30 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 570.195.03 Driver Version: 570.195.03 CUDA Version: 12.8 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 5070 On | 00000000:01:00.0 On | N/A |
| 0% 43C P8 9W / 250W | 1145MiB / 12227MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 2860 G /usr/lib/xorg/Xorg 495MiB |
| 0 N/A N/A 3108 G /usr/bin/gnome-shell 64MiB |
| 0 N/A N/A 3665 G ...exec/xdg-desktop-portal-gnome 132MiB |
| 0 N/A N/A 1128255 G /usr/bin/gnome-system-monitor 27MiB |
| 0 N/A N/A 2592956 G /proc/self/exe 61MiB |
| 0 N/A N/A 2605030 G ...144 --variations-seed-version 63MiB |
| 0 N/A N/A 2778841 G /usr/bin/gnome-calculator 11MiB |
| 0 N/A N/A 2952810 G /usr/bin/gnome-control-center 19MiB |
+-----------------------------------------------------------------------------------------+nvidia-smi 是 GPU 驱动里带的,这里的 CUDA Version 是 12.8,这意味着当前驱动最高支持 CUDA 12.8,你可以安装的最高版本的 CUDA Toolkit 版本是 12.8。
compute capability
NVIDIA 为每一代 GPU 设定了一个 compute capability,NVIDIA 每隔一两年就会推出新的 GPU 型号,每一代 GPU 的能力可能都会增强,相应地 compute capability 也会变大。
你可以在 https://developer.nvidia.com/cuda-gpus 查看你的 GPU 的 compute capability。
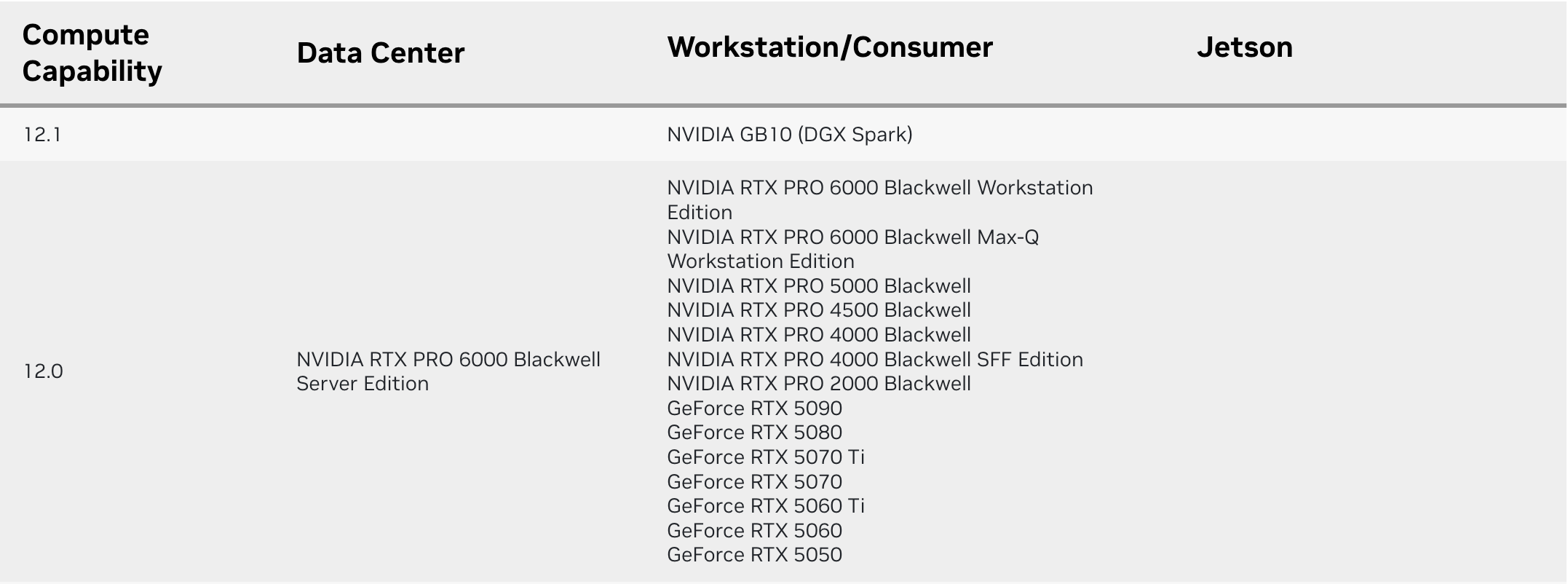
如果 CUDA Toolkit 版本过低,自然就不能编译出支持最新 CUDA 功能的程序,因此你需要安装支持你的 GPU 对应的 compute capability 的 CUDA Toolkit 版本。
你可以在 https://en.wikipedia.org/wiki/CUDA 查看不同的 CUDA Toolkit 版本支持的 compute capability 范围,下面是截图:
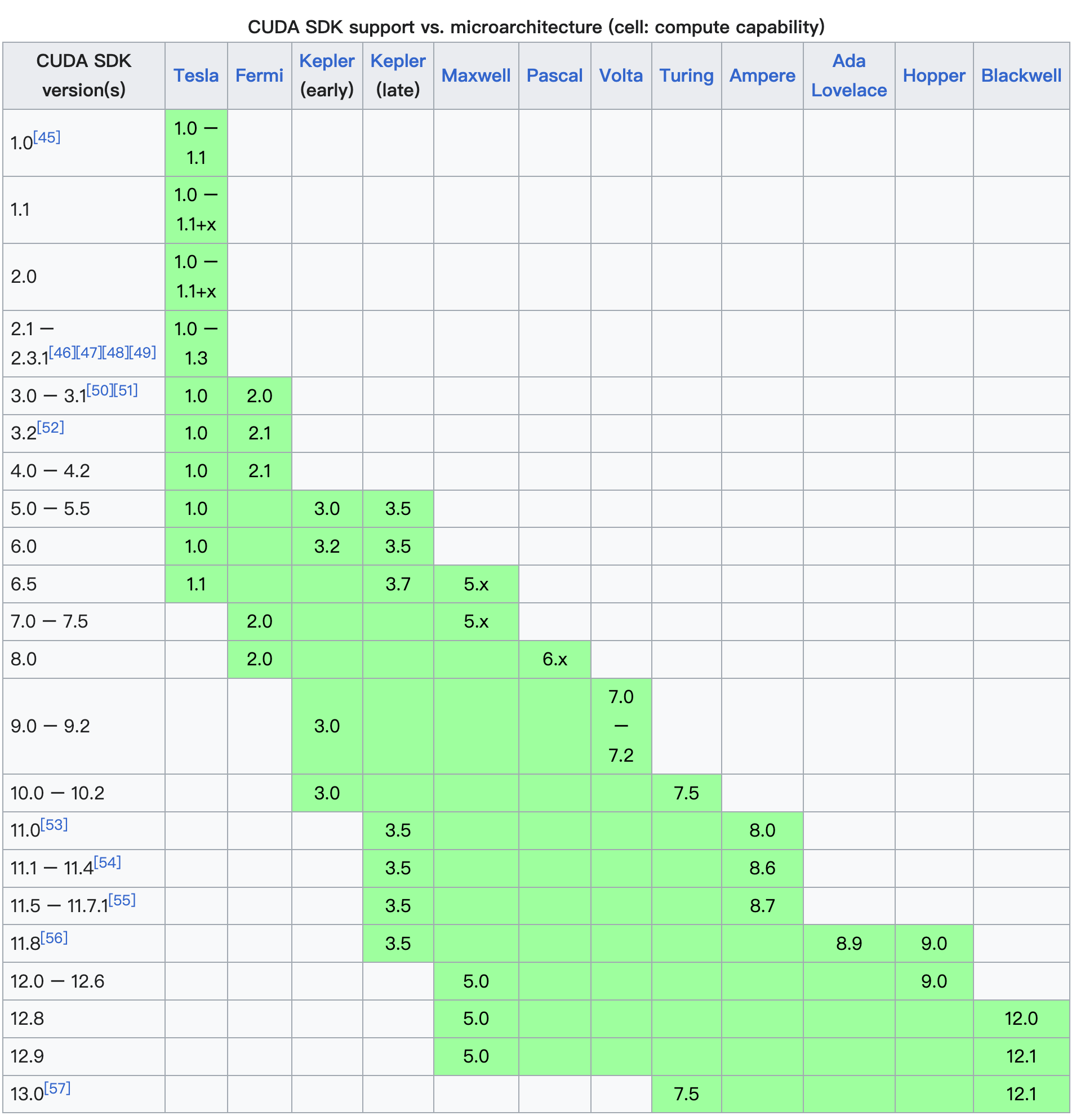
比如我的 GPU 是 NVIDIA RTX5070,对应的 compute capability 是 12.0,从上图可以看出我需要安装 CUDA Toolkit 12.8 或者更新的版本才能编译出支持我的 GPU 所有功能的程序。
在 https://developer.nvidia.com/cuda-toolkit-archive 你可以找到不同版本的 CUDA Toolkit 的下载地址,并提供了详细的安装步骤,你可以根据你的 GPU 的 compute capability 选择合适的版本。
当你按照步骤安装好 CUDA Toolkit 后,你可以通过 nvcc --version 命令来检查你的 CUDA 环境是否配置成功。
$ nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2025 NVIDIA Corporation
Built on Fri_Feb_21_20:23:50_PST_2025
Cuda compilation tools, release 12.8, V12.8.93
Build cuda_12.8.r12.8/compiler.35583870_0第一个例子
接下来我们来写一个简单的 CUDA 程序,借助这个程序来了解 CUDA 程序的基本结构和编译执行方式。代码内容如下:
#include <stdio.h>
__global__ void hello() {
printf("Hello, I am from block %d thread %d\n", blockIdx.x, threadIdx.x);
}
int main() {
hello<<<2, 2>>>();
cudaDeviceSynchronize();
return 0;
}可以使用 nvcc hello.cu 命令来编译这个程序,它会生成一个可执行文件 a.out。
运行 ./a.out 可以看到如下输出:
$ ./a.out
Hello, I am from block 0 thread 0
Hello, I am from block 0 thread 1
Hello, I am from block 1 thread 0
Hello, I am from block 1 thread 1如果你真的是第一次接触 CUDA,你可能会有很多疑问。hello<<<2, 2>>> 是什么,它也不是 C++ 中的模版呀,__global__ 又是什么,为什么要在最后调用 cudaDeviceSynchronize() 呢?
CUDA 代码中包含了两种类型的函数:主机函数和核函数。主机函数是在 CPU 上执行的函数,它通过 GPU 提供的接口将核函数传达给 GPU 让 GPU 执行。在 GPU 内部,有大量的计算单元,这些计算单元被称抽象为 block 和 thread 等概念。一个 block 中可以包含多个 thread,所有的 thread 都会执行相同的核函数。
举个例子,假如你是一个工程的老板,你的工厂里有很多个车间(block),每个车间里有很多个工人(thread),每个工人做的事情是一样的。而你就是 CPU 用来分配任务的,你告诉每个车间里的工人做什么事情。
这就是 GPU 能并行计算的原因,每个 thread 都可以独立地执行核函数中的代码,而不需要等待其他 thread 完成。核函数中的代码可以被并行地执行,而且每个 thread 都有根据自己的编号获取自己负责的数据并完成计算。
hello<<<2, 2>>>() 是 CUDA 中的一个调用核函数的语法,它的意思是启动 2 个 block,每个 block 有 2 个 thread 来执行 hello 这个核函数。

核函数是在 GPU 上并行执行的函数,每个核函数在运行时可以访问 blockIdx, blockDim 和 threadIdx 这些常量,线程内部可以使用它们来定位自己的位置,并使用该位置来获取自己负责的数据并完成计算。
__global__ 是 CUDA 中的一个关键字,它表示这个函数是一个核函数。在编译阶段,编译器会将 __global__ 函数编译成可以在 GPU 上执行的指令,hello<<<2, 2>>>() 这样的启动函数就是语法糖,底层是通过 cudaLaunchKernel 这样的 API 来启动核函数的。
CPU 启动核函数后,并不会等待核函数的执行完成就继续往下运行。因此核函数的执行是异步的,为了确保所有的输出都被打印出来,我们调用了 cudaDeviceSynchronize() 函数来等待所有 GPU 上的核函数执行完成,确保所有的输出都被打印出来。
第二个例子
有了以上背景知识,就可以写出一个有点用的程序了。下面的例子演示了如何使用 CUDA 来加速数组的加法。代码内容如下:
#include <stdio.h>
#include <assert.h>
#include <stdlib.h>
#define CHECK_CUDA_ERR(err) do { \
if (err != cudaSuccess) { \
fprintf(stderr, "CUDA Error: %s at line %d\n", cudaGetErrorString(err), __LINE__); \
exit(EXIT_FAILURE); \
} \
} while (0)
__global__ void add(float *x, float *y, float *z, int n) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < n) { // 确保线程索引不超过数组大小
z[i] = x[i] + y[i];
}
}
int main() {
int N = 1024 * 1024 * 100;
int SIZE = N * sizeof(float);
// 分配主机内存
float *h_x = (float*)malloc(SIZE);
float *h_y = (float*)malloc(SIZE);
float *h_z = (float*)malloc(SIZE);
// 初始化主机数据
for (int i = 0; i < N; i++) {
h_x[i] = 1.0f;
h_y[i] = 2.0f;
}
// 分配设备内存(添加错误检查)
float *d_x, *d_y, *d_z;
CHECK_CUDA_ERR(cudaMalloc(&d_x, SIZE));
CHECK_CUDA_ERR(cudaMalloc(&d_y, SIZE));
CHECK_CUDA_ERR(cudaMalloc(&d_z, SIZE));
// 主机→设备数据传输(添加错误检查)
CHECK_CUDA_ERR(cudaMemcpy(d_x, h_x, SIZE, cudaMemcpyHostToDevice));
CHECK_CUDA_ERR(cudaMemcpy(d_y, h_y, SIZE, cudaMemcpyHostToDevice));
// 计算 block 数:总元素数 / 每个block的线程数(向上取整)
int threads = 256;
int blocks = (N + threads - 1) / threads;
add<<<blocks, threads>>>(d_x, d_y, d_z, N);
CHECK_CUDA_ERR(cudaGetLastError());
cudaDeviceSynchronize();
// 设备→主机数据传输(添加错误检查)
CHECK_CUDA_ERR(cudaMemcpy(h_z, d_z, SIZE, cudaMemcpyDeviceToHost));
// 验证结果
for (int i = 0; i < N; i++) {
assert(h_z[i] == 3);
}
printf("All assertions passed! Result is correct.\n");
// 释放内存(避免泄漏)
free(h_x);
free(h_y);
free(h_z);
CHECK_CUDA_ERR(cudaFree(d_x));
CHECK_CUDA_ERR(cudaFree(d_y));
CHECK_CUDA_ERR(cudaFree(d_z));
// 重置CUDA设备(可选,释放设备资源)
CHECK_CUDA_ERR(cudaDeviceReset());
return 0;
}这段代码演示了如何使用 CUDA 来加速数组的加法。它首先在主机上分配内存并初始化数据,然后将这些数据复制到设备(GPU)上的内存中,接着启动核函数进行计算,最后将结果从设备内存复制回主机内存并进行验证。
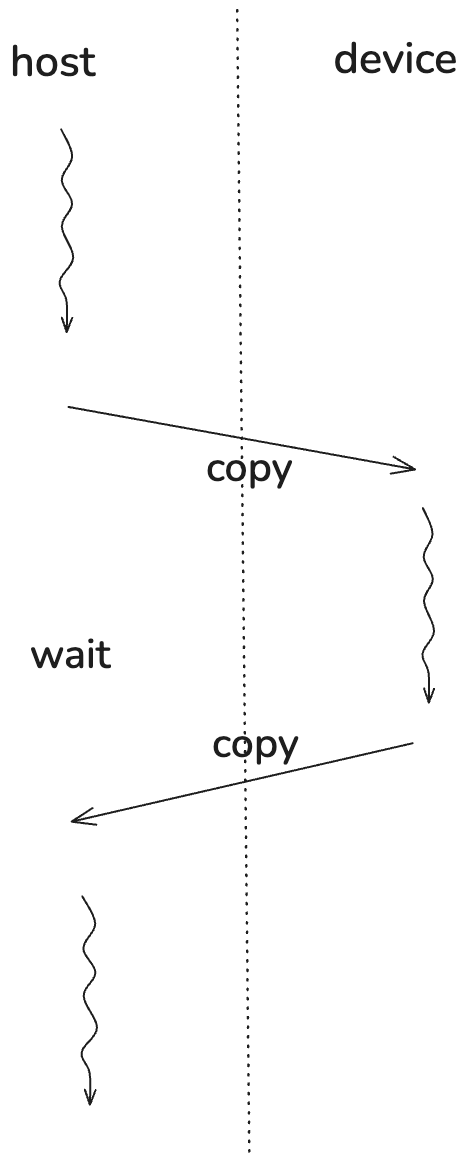
GPU 使用的内存和我们平时用到的 DRAM 是不同的。DRAM 是主板上内存条中使用的存储技术,用于存储程序运行时需要的数据和指令。而 GPU 使用的内存是显存,它集成在显卡上。GPU 直接访问的是显存中的数据。GPU 的母版通过 PCIe 接口连接到机器的主板上,并通过这种方式与主板上的 CPU 通信。

因此,使用 CUDA 进行并行计算时,需要将数据从主机内存复制到设备内存中,然后在设备上执行核函数进行计算,最后将结果复制回主机内存。
为了在 GPU 上分配内存,我们使用了 cudaMalloc 函数。这个函数的参数是一个指针,指向我们要分配的内存的地址。返回值是一个 cudaError_t 类型的枚举值,用于表示分配内存是否成功。如果分配成功,返回 cudaSuccess。如果分配失败,返回一个错误代码。我们通过 CHECK_CUDA_ERR 宏来检查 CUDA API 的返回值是否为成功,如果不是则打印出相应的错误信息并退出程序。
要在 GPU 的显存和主机内存之间进行数据传输,我们使用了 cudaMemcpy 函数。这个函数的参数包括源地址、目标地址、传输的字节数和传输方向(主机到设备或设备到主机)。
在核函数中,我们使用了 blockIdx.x * blockDim.x + threadIdx.x 来计算每个线程应该处理的数组索引。因为总的线程数可能会超过数组的大小,所以我们需要在计算索引时进行判断,确保索引不超过数组的大小。
计算速度对比
为了演示 GPU 和 CPU 在执行相同任务时的性能差异,我们可以编写一个简单的测试程序,在 CPU 上和 GPU 上计算数组加法所需的时间:
#include <chrono>
#include <iostream>
// ...
class Timer {
public:
explicit Timer(std::string name) {
name_ = std::move(name);
start_ = std::chrono::high_resolution_clock::now();
}
~Timer() {
auto end = std::chrono::high_resolution_clock::now();
std::chrono::duration<float, std::milli> elapsed = end - start_;
std::cout << name_ << " cost: " << elapsed.count() << "ms" << std::endl;
}
private:
std::string name_{};
std::chrono::high_resolution_clock::time_point start_{};
};
int main() {
//...
{
Timer timer("cpu");
for (int i = 0; i < N; i++) {
h_z[i] = h_x[i] + h_y[i];
}
}
//...
{
Timer timer("gpu");
add<<<blocks, threads>>>(d_x, d_y, d_z, N);
CHECK_CUDA_ERR(cudaGetLastError());
cudaDeviceSynchronize();
}
// ... 其他代码
}这段代码使用了 Timer 类来测量不同部分执行所需的时间。我使用 O3 优化级别编译代码,分别在 CPU 和 GPU 上计算数组加法,并打印出各自花费的时间,结果如下:
cpu cost: 98.2919ms
gpu cost: 2.18634ms可以看到,在这个简单的测试中,对 100 万个浮点数执行加法,GPU 实现了近 50 倍的加速比。当然了,上面的实现都还有很大的优化空间,但这初步向我们展现了利用 GPU 并行计算能力,可以大幅提升计算速度。
总结
本文简单介绍了 GPU 的历史,并初步介绍了 CUDA 的由来,以及开发环境配置。后面使用了两个例子演示了如何使用 CUDA 来编写并行程序,并由此介绍了 CUDA 编程中的一些基本概念。这些只是入门级别的内容,后面还有很长的路要走,但好在我们已经在路上了。