CUDA 014 - MMA 指令的用法详解
MMA(Matrix Multiply and Accumulate)是 NVIDIA GPU 提供的专用矩阵乘加指令,用于高效执行 D = A * B + C 运算。随着深度学习和高性能计算对矩阵运算需求的增加,GPU 针对矩阵乘加操作进行了硬件级优化,MMA 指令正是其中的关键组成部分。而且随着硬件的不断升级,MMA 指令也在不断演进,支持更多的数据类型和矩阵规格。本文将介绍一个由 Ampere 架构引入的指令,后续版本引入的新指令,在原理上存在类似之处,因此本文内容对于最新的指令的用法的学习也具有一定的参考价值。
本文主要介绍 mma.sync.aligned.m16n8k16 指令,它可以完成一个 M=16、N=8、K=16 的矩阵乘加运算,支持 fp16 和 bf16 两种输入数据类型,累加结果使用 fp32 存储,是目前应用最广泛的 MMA 指令之一。在实际的矩阵运算中,通常采用分块(tiling)技术将大矩阵分解为小矩阵块进行计算。MMA 指令正是针对这些小矩阵块的乘加运算进行了硬件级优化,可以大幅提升矩阵乘加运算的性能。本文将详细介绍如何使用 MMA 指令来加速矩阵乘加运算,最后会给出详尽的代码示例。
MMA 指令的格式
MMA 指令的格式有很多种,完整的格式说明可以参考 PTX 文档,这里只介绍最常用的几种格式:
mma.sync.aligned.m16n8k8.row.col.dtype.f16.f16.ctype d, a, b, c;
mma.sync.aligned.m16n8k16.row.col.dtype.f16.f16.ctype d, a, b, c;
mma.sync.aligned.m16n8k16.row.col.f32.bf16.bf16.f32 d, a, b, c;
.ctype = {.f16, .f32};
.dtype = {.f16, .f32};mma 指令支持多种矩阵大小和数据类型的组合。这是一个 warp 级别的指令,执行时需要 warp 内所有 32 个线程协同参与,矩阵数据分散存储在各线程的寄存器中。
让我们逐一解析指令中各个修饰符的含义:
.sync:同步指令,所有线程必须等待指令执行完成后才能继续.aligned:要求 warp 内所有线程执行相同的 mma 指令,且所有修饰符完全一致m16n8k16:矩阵形状参数,表示 M=16、N=8、K=16。在矩阵乘法D = A * B + C中,A 为 16×16(MxK),B 为 16×8(KxN),C 和 D 为 16×8(MxN)。PTX 支持多种预设的矩阵规格row.col:数据布局,表示 A 矩阵按行优先(row-major)存储,B 矩阵按列优先(column-major)存储f32.bf16.bf16.f32:数据类型,按 D、A、B、C 的顺序指定。累加矩阵 C 和结果矩阵 D 通常使用更高精度(f32)以保证计算精度d, a, b, c:寄存器操作数,分别存储 D、A、B、C 矩阵的数据
数据分布:对于 m16n8k16 指令,矩阵元素在 32 个线程间的分布如下:
- A 矩阵(16×16):256 个元素,每线程 8 个
- B 矩阵(16×8):128 个元素,每线程 4 个
- C/D 矩阵(16×8):128 个元素,每线程 4 个
下面是对 mma.sync.aligned.m16n8k16.row.col.f32.f16.f16.f32 指令封装后的函数:
__device__ void
fma(float & d0, float & d1, float & d2, float & d3,
uint32_t const& a0, uint32_t const& a1, uint32_t const& a2, uint32_t const& a3,
uint32_t const& b0, uint32_t const& b1,
float const & c0, float const & c1, float const & c2, float const & c3) {
asm volatile(
"mma.sync.aligned.m16n8k16.row.col.f32.f16.f16.f32 "
"{%0, %1, %2, %3},"
"{%4, %5, %6, %7},"
"{%8, %9},"
"{%10, %11, %12, %13};\n"
: "=f"(d0), "=f"(d1), "=f"(d2), "=f"(d3)
: "r"(a0), "r"(a1), "r"(a2), "r"(a3),
"r"(b0), "r"(b1),
"f"(c0), "f"(c1), "f"(c2), "f"(c3));
}寄存器使用说明:因为数据类型为 f32.f16.f16.f32,A/B 矩阵的元素为 16 位(2 字节),C/D 矩阵的元素为 32 位(4 字节)。由于寄存器为 32 位宽,因此:
- A/B 矩阵:每个
uint32_t寄存器可打包 2 个 fp16 元素 - C/D 矩阵:每个
float寄存器存储 1 个 fp32 元素
后文将详细介绍如何将共享内存中的矩阵数据加载到寄存器中,并重点讲解 mma.sync.aligned.m16n8k16.row.col.f32.f16.f16.f32 指令的使用方法。
MMA 指令的数据布局
MMA 指令由 warp 内所有 32 个线程协同执行,因此需要理解矩阵数据如何分布在这些线程的寄存器中。这个分布模式是硬件预定义的,我们必须按照这个模式来组织数据,才能正确调用 MMA 指令。
下图展示了 m16n8k16 指令中,A、B、C 三个矩阵在 warp 内各线程的分布情况:
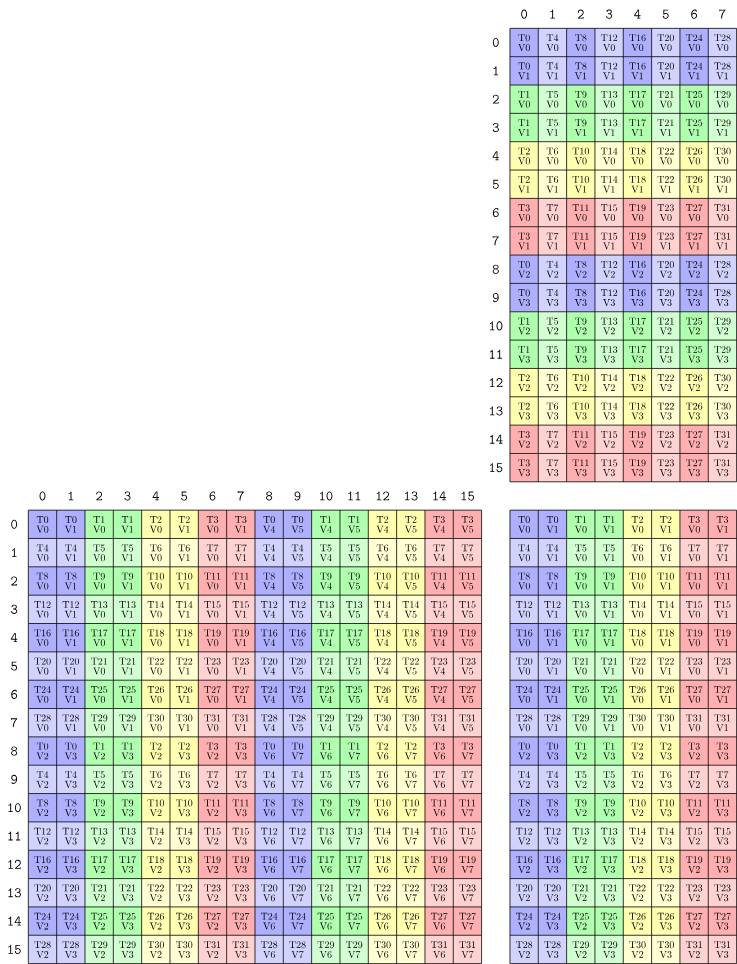
上图中左侧、上侧和右侧分别表示 A、B 和 C 矩阵,其中 A 是 16x16 矩阵,B 和 C 是 16x8 矩阵。每一个小方格表示矩阵中的一个数据元素,方格中的 T0、T1、T2 等表示该数据所在的线程编号,V0、V1、V2 表示此数据是该线程的第几个数据(指令参数传入的顺序)。
初次看到这个图可能会感到困惑,但其中有规律可循。关键点是矩阵被划分为多个 8×8 的子矩阵块。下图展示了 A 矩阵(16×16)的数据布局:

数据分布规律:
- 16×16 的 A 矩阵被划分为 4 个 8×8 的子矩阵
- 每个 8×8 子矩阵按行优先方式分布在 32 个线程中
- 每个线程负责一个子矩阵中的 2 个元素(一行中的相邻元素)
- 对于单个 8×8 子矩阵:线程 0-3 存储第 0 行,线程 4-7 存储第 1 行,以此类推
- 因为有 4 个子矩阵,每个线程总共存储 8 个元素(4 个子矩阵 × 每个 2 个元素)
重要:只要按照这个分布模式将数据加载到寄存器中,MMA 指令就能正确识别和处理数据。
我们可以按照上述分布规律,将共享内存中的矩阵数据加载到 warp 内各线程的寄存器中。例如,加载 A 矩阵的代码如下:
__shared__ half smem_a[16][16]; // A 矩阵存储在共享内存中
// 每个线程用 4 个寄存器存储 8 个 fp16 元素(每个寄存器打包 2 个元素)
uint32_t a0, a1, a2, a3;
int lane = threadIdx.x % 32; // 线程在 warp 中的编号 (0-31)
int row = lane / 4; // 计算该线程负责的行号 (0-7)
int col = lane % 4 * 2; // 计算该线程负责的列号起始位置 (0, 2, 4, 6)
// 加载 4 个 8×8 子矩阵中的数据
a0 = *reinterpret_cast<uint32_t*>(&smem_a[row][col]); // 左上子矩阵
a1 = *reinterpret_cast<uint32_t*>(&smem_a[row + 8][col]); // 左下子矩阵
a2 = *reinterpret_cast<uint32_t*>(&smem_a[row][col + 8]); // 右上子矩阵
a3 = *reinterpret_cast<uint32_t*>(&smem_a[row + 8][col + 8]);// 右下子矩阵完整的代码示例可以参考 CUDA MMA 示例代码
B 矩阵是 16x8 的矩阵,可以划分为 2 个 8x8 的子矩阵,其数据布局如下图所示:

这里 B 矩阵的 8x8 子矩阵是按列优先的方式存储在 0-31 号线程的寄存器中的,每个线程存储两个数据。两个 8x8 子矩阵的数据分别存储在每个线程的两个寄存器中。
C 矩阵数据的分布也是类似的,它由两个 8x8 的子矩阵组成,每个子矩阵按行优先的方式存储在 0-31 号线程的寄存器中,每个线程存储两个数据,因为 C 矩阵的数据类型为 f32,每个数据占用一个寄存器。两个 8x8 子矩阵的 4 个数据分别存储在每个线程的 4 个寄存器中。
虽然可以手动计算每个线程的数据地址并加载,但这种方式代码复杂且容易出错。幸运的是,PTX 提供了专门的 ldmatrix 指令,能够高效地将共享内存中的矩阵数据批量加载到寄存器中,并自动完成数据分布。下一节将详细介绍如何使用这个强大的指令。
加载矩阵到寄存器
在调用 mma 指令之前,需要先将 A、B、C 矩阵的数据从共享内存加载到寄存器中。相比手动计算地址和分布逻辑,ldmatrix 指令提供了一种简洁且高效的解决方案。
ldmatrix 指令能够一次性从共享内存中读取 8×8 的子矩阵,并自动将数据分散到 warp 内 32 个线程的寄存器中。其工作机制如下:
- Warp 内前 8 个线程(lane 0-7)各提供一个内存地址,指向矩阵的 8 行
ldmatrix从每个地址读取 8 个元素(16 字节)- 读取的 8×8=64 个元素按预定规则分布到 32 个线程的寄存器中
- 每个线程获得 2 个元素,打包存储在一个 32 位寄存器中
下图展示了 8×8 矩阵加载后在各线程中的分布:

图中数字表示这个位置的元素所在的线程编号,每个线程存储两个数据
目前你只需要知道 ldmatrix 指令可以方便地将共享内存中的 8x8 矩阵加载到寄存器中,关于加载的具体细节,后文会做详细介绍。
ldmatrix 指令格式
ldmatrix 指令完整的格式说明可以参考 PTX 文档,这里只介绍最常用的格式:
ldmatrix.sync.aligned.shape.num{.trans}{.ss}.type r, [p];
.shape = {.m8n8};
.num = {.x1, .x2, .x4};
.ss = {.shared{::cta}};
.type = {.b16, .b8};这里的 shape 表示加载的矩阵大小,.m8n8 表示加载 8x8 的矩阵。对于 16 位数据通常使用 .m8n8,如需加载 16x16,可用 .x4 组合成 4 个 8x8 分块完成加载。
.num 表示加载的矩阵个数,x2 表示加载两个矩阵,x4 表示加载四个矩阵。
.trans 表示加载的矩阵是否需要转置后再存储到寄存器中。对于 A 矩阵来说,因为它是按行优先的方式存储在共享内存中的,因此不需要转置,省略此修饰符即可。对于 B 矩阵来说,因为它是按列优先的方式存储在共享内存中的,因此需要转置后再存储到寄存器中,此时需要加上此修饰符。
.ss 表示加载的数据所在的内存空间,这里通常使用共享内存,因此使用 .shared 修饰符。
.type 表示数据类型,.b16 表示 16 bit 的数据,.b8 表示 8 bit 的数据。这里并不区分数据的具体类型是 fp16 还是 bf16,只要数据占用 16 bit 就可以使用 .b16。
r 表示存储加载数据的寄存器,可以是一个寄存器或者多个寄存器组成的列表。如果是 x1 ,则需要提供 1 个寄存器;如果是 x2,则需要提供 2 个寄存器;如果是 x4,则需要提供 4 个寄存器。
p 表示加载数据的共享内存地址,需要传入指向共享内存的指针。使用 m8n8 模式加载一个 8x8 的矩阵时,并不要求 8x8 的矩阵的所有行在内存中连续存储,只需要每一行的数据是连续存储的即可。8 行数据需要 8 个地址。这 8 个地址分别由前 8 个线程来提供(其他线程传入的地址不被使用)。然后整个 warp 的 32 个线程协同完成 8x8 矩阵的加载,并将所有数据分散到 32 个线程提供的寄存器中。
不同的 .num 参数对应的寄存器地址和线程的映射关系如下表所示:
.num | Threads 0–7 | Threads 8–15 | Threads 16–23 | Threads 24–31 |
|---|---|---|---|---|
.x1 | addr0–addr7 | – | – | – |
.x2 | addr0–addr7 | addr8–addr15 | – | – |
.x4 | addr0–addr7 | addr8–addr15 | addr16–addr23 | addr24–addr31 |
使用 ldmatrix 加载 8×8 矩阵的示例代码:
__shared__ half smem_a[8][8]; // 共享内存中的 8×8 矩阵
int lane = threadIdx.x % 32; // 当前线程在 warp 中的编号
int row = lane % 8; // 前 8 个线程(lane 0-7)各提供一行的地址
int col = 0; // 从第 0 列开始读取
uint32_t* addr = reinterpret_cast<uint32_t*>(&smem_a[row][col]);
uint32_t a0; // 存储 2 个 fp16 元素(打包在 1 个 32 位寄存器中)
asm volatile ("ldmatrix.sync.aligned.x1.m8n8.shared.b16 {%0}, [%1];\n"
: "=r"(a0) // 输出: 寄存器 a0
: "r"(addr)); // 输入: 共享内存地址执行效果:Warp 内 32 个线程协同执行,将 8×8=64 个元素加载到各自的寄存器中,每个线程获得 2 个元素,打包存储在一个 32 位寄存器中。
共享内存地址计算
ldmatrix 的一个重要特性是:不要求矩阵在内存中完全连续。唯一的要求是每一行内部的元素连续。这种灵活性使得我们可以从大矩阵中加载子矩阵,或者处理有 padding 的矩阵。
地址提供机制:
- 前 8 个线程(lane 0-7)各提供一个地址,指向要加载的 8 行
- 其他 24 个线程的地址参数被忽略(但仍需参与执行)
- 所有 32 个线程协同完成加载,数据自动分布
例如,从下面的 8×16 矩阵中加载右侧的 8×8 子矩阵时,线程 0-7 提供的地址如图所示:

图中数字表示线程编号,标记位置是该线程提供的内存地址(指向该行起始位置)
灵活性:加载的 8 行数据不一定要形成规则的矩阵块,只要每行内部连续即可。例如下图所示,可以从不同位置加载 8 行:

加载更大的矩阵:要加载 16×16 矩阵,使用 .x4 修饰符一次加载 4 个 8×8 块:
- 32 个线程全部参与地址提供
- 线程 0-7 提供第 1 个 8×8 块的 8 行地址
- 线程 8-15 提供第 2 个块的地址
- 线程 16-23 提供第 3 个块的地址
- 线程 24-31 提供第 4 个块的地址
地址分布如下图所示:

加载 16×16 矩阵的代码示例:
__shared__ half smem_a[16][16]; // 共享内存中的 16×16 矩阵
int lane = threadIdx.x % 32; // 线程编号 (0-31)
int row = lane % 16; // 行号 (0-15),循环使用
int col = (lane / 16) * 8; // 列偏移 (0 或 8)
uint32_t* addr = reinterpret_cast<uint32_t*>(&smem_a[row][col]);
uint32_t a0, a1, a2, a3; // 4 个寄存器,对应 4 个 8×8 块
asm volatile ("ldmatrix.sync.aligned.x4.m8n8.shared.b16 {%0, %1, %2, %3}, [%4];\n"
: "=r"(a0), "=r"(a1), "=r"(a2), "=r"(a3) // 输出: 4 个寄存器
: "r"(addr)); // 输入: 地址数据分布:执行完成后,例如 lane 0 的线程中:
a0-a3分别存储 4 个 8×8 子矩阵第 0 行的前 2 个元素- 其他线程以类似模式分别存储各自负责的行和列
加载时转置
回顾 MMA 指令中 A 和 B 矩阵的数据布局差异:

图中小数字表示线程编号,大数字表示 8×8 子矩阵编号
关键区别:
- A 矩阵:8×8 子矩阵按行优先方式映射到线程寄存器(左图)
- B 矩阵:8×8 子矩阵按列优先方式映射到线程寄存器(右图)
为了适应这种布局差异,ldmatrix 提供了 .trans 修饰符,允许在加载时进行转置。下图对比了转置与非转置加载 8×8 矩阵时的数据分布:

图中深色部分为线程 0-7 提供的地址,数字表示该元素所在的线程编号
代码示例 - 转置 vs 非转置加载:
__shared__ half smem[8][8]; // 共享内存中的 8×8 矩阵
int lane = threadIdx.x % 32;
int row = lane; // 前 8 个线程(0-7)各提供一行的地址
int col = 0; // 从第 0 列开始
uint32_t* addr = reinterpret_cast<uint32_t*>(&smem[row][col]);
uint32_t a0, b0;
// 非转置加载 - 适用于行优先存储的 A 矩阵
asm volatile ("ldmatrix.sync.aligned.x1.m8n8.shared.b16 {%0}, [%1];\n"
: "=r"(a0) : "r"(addr));
// 转置加载 - 适用于列优先存储的 B 矩阵
asm volatile ("ldmatrix.sync.aligned.x1.trans.m8n8.shared.b16 {%0}, [%1];\n"
: "=r"(b0) : "r"(addr));MMA 指令中 A/B 矩阵的加载
场景设定:假设共享内存中
- A 矩阵:M×K 大小
- B 矩阵:K×N 大小
MMA 指令要求的数据分布方式如下图:

图中深色标记为线程提供的地址位置
加载策略:
- A 矩阵:不转置加载
- B 矩阵:转置加载
A 矩阵加载代码
加载 16×16 的 A 矩阵(MxK):
__shared__ half smem_a[16][16]; // MxK 矩阵
int lane = threadIdx.x % 32;
int row_a = lane % 16; // 行号 (0-15)
int col_a = lane / 16 * 8; // 列偏移 (0 或 8)
uint32_t* addr_a = reinterpret_cast<uint32_t*>(&smem_a[row_a][col_a]);
uint32_t a0, a1, a2, a3;
// 非转置加载,一次加载 4 个 8×8 块
asm volatile ("ldmatrix.sync.aligned.x4.m8n8.shared.b16 {%0, %1, %2, %3}, [%4];\n"
: "=r"(a0), "=r"(a1), "=r"(a2), "=r"(a3)
: "r"(addr_a));地址计算:
row_a = lane % 16:线程 0-15 和 16-31 分别提供 16 行的地址col_a = lane / 16 * 8:线程 0-15 负责前 8 列,线程 16-31 负责后 8 列
B 矩阵加载代码
加载 16×8 的 B 矩阵(K×N):
__shared__ half smem_b[16][8]; // KxN 矩阵
int row_b = lane; // 线程 0-15 分别提供 16 行的地址
int col_b = 0; // 从第 0 列开始
uint32_t* addr_b = reinterpret_cast<uint32_t*>(&smem_b[row_b][col_b]);
uint32_t b0, b1;
// 转置加载,一次加载 2 个 8×8 块
asm volatile ("ldmatrix.sync.aligned.x2.trans.m8n8.shared.b16 {%0, %1}, [%2];\n"
: "=r"(b0), "=r"(b1)
: "r"(addr_b));地址计算:
row_b = lane:线程 0-15 和 16-31 分别提供两组 16 行的地址col_b = 0:从第 0 列开始读取- 加上
.trans修饰符,实现转置加载
B 矩阵的替代存储布局
如果 B 矩阵在共享内存中以 N×K 格式存储,则可以直接使用非转置加载。下图展示了这种情况下的线程地址分布:

加载 N×K 布局的 B 矩阵代码:
__shared__ half smem_b[8][16]; // N×K 矩阵
int lane = threadIdx.x % 32;
int row = lane % 8; // 行号 (0-7),线程 0-7 和 8-15 分别提供 8 行
int col = lane / 8 * 8; // 列偏移, 0 或 8
uint32_t* addr = reinterpret_cast<uint32_t*>(&smem_b[row][col]);
uint32_t b0, b1;
// 非转置加载(因为已是行优先存储)
asm volatile ("ldmatrix.sync.aligned.x2.m8n8.shared.b16 {%0, %1}, [%2];\n"
: "=r"(b0), "=r"(b1)
: "r"(addr));关键点:当 B 矩阵以 N×K 存储时,已经是转置形式,无需再加 .trans 修饰符。
A/B 矩阵加载总结
在使用 MMA 指令前,需要根据矩阵在共享内存中的存储格式,合理选择 ldmatrix 的转置与否。一种简单的思维方式是考虑矩阵乘法的数学定义。对于 C = A × B,其中 C[0,0] 的计算涉及 A 的第 0 行和 B 的第 0 列。在加载完成 A 和 B 矩阵后,应该使得 A 的第 0 行数据分布在 0-3 号线程的寄存器中,而 B 的第 0 列数据也应该分布在 0-3 号线程的寄存器中。我猜想 MMA 这样要求数据分布的原因是为了让每个线程在计算 C 矩阵的元素时,可以直接使用自己寄存器中的数据,而不需要跨线程访问。
因此,在思考如何加载 A 和 B 矩阵时,可以从 C 矩阵的计算需求出发,确保每个线程在计算 C 矩阵元素时,能够直接使用自己寄存器中的数据。这样你就可以根据 B 矩阵在共享内存中的存储模式,选择是否需要转置加载。
存储结果到共享内存
MMA 指令执行完成后,结果矩阵 D 的数据分布与 C 矩阵一致,存储在各线程的寄存器中。若需要将结果写回共享内存,可以使用 stmatrix 指令。
stmatrix 指令格式:
stmatrix.sync.aligned.shape.num{.trans}{.ss}.type [p], r;
.shape = {.m8n8, .m16n8}; // 矩阵形状
.num = {.x1, .x2, .x4}; // 存储的块数量
.ss = {.shared{::cta}}; // 目标内存空间
.type = {.b16, .b8}; // 元素位宽stmatrix 是 ldmatrix 的逆操作,将寄存器中的数据写回共享内存。其参数含义、线程地址映射关系与 ldmatrix 相同。
重要说明:
stmatrix需要 sm_90 及以上架构支持- 如果需要兼容较低 GPU 架构,需要手动编写存储代码
更多关于 ldmatrix 和 stmatrix 的使用示例,可参考 CUDA MMA 示例代码。
使用 MMA 实现通用矩阵乘加
现在我们已掌握了:
- MMA 指令的调用方式
- 矩阵数据的分布规律
- 使用
ldmatrix加载数据的方法
接下来介绍如何将这些技术组合起来,实现高效的通用矩阵乘法(GEMM)。
Tiling 策略:矩阵乘法通常采用分块(tiling)技术。对于 D = A × B + C 运算,其中 A(M×K),B(K×N),C/D(M×N),我们可以将计算分解为:

分块策略:
- 输出矩阵 C/D 划分为 Bm×Bn 大小的块,每个块由一个线程块负责
- 每个线程块沿 K 维度迭代,每次计算 Bk 大小的块
关于矩阵乘法的 tiling 技术详情,可参考我之前的文章 CUDA 矩阵乘法优化。本文重点讲解如何使用 MMA 指令计算这些小块。
MMA 块的大小匹配
MMA 指令支持的矩阵大小是固定的。本文介绍的 mma.sync.aligned.m16n8k16.row.col.f32.f16.f16.f32 支持 M=16,N=8,K=16。
简单方案:直接设置 Bm=16,Bn=8,Bk=16,但这会导致 tiling 粒度太小,无法充分利用 GPU 资源。
实用方案:设置 Bm=128,Bn=128,Bk=32(均为 MMA 尺寸的整数倍),然后在线程块内继续分块。下图展示了这种分块方式:

多层分块逻辑:就像外层将大矩阵分为 Bm×Bn 块一样,线程块内部也需要将 Bm×Bn 块继续划分为更小的 16×8 块,直到可以用 MMA 指令计算。
Warp 级并行分配
因为 MMA 是 warp 级指令,我们可以让多个 warp 并行处理不同的 16×8 块:

实现策略:线程块中启动 num_warps 个 warp,让它们并行处理 Bm×Bn 块中的多个 16×8 小块。下面是一种可能的实现:
int mma_m = Bm / 16; // M 维度上的 MMA 块数量
int mma_n = Bn / 8; // N 维度上的 MMA 块数量
int mma_k = Bk / 16; // K 维度上的迭代次数
// 多个 warp 并行处理 mma_m × mma_n 个 16×8 块
for (int idx = warp_id; idx < mma_m * mma_n; idx += num_warps) {
int m = idx / mma_n; // 当前块在 M 维度的位置
int n = idx % mma_n; // 当前块在 N 维度的位置
// 当前 warp 计算位于 (m, n) 位置的 16×8 块
}分工逻辑:每个 warp 沿着 M×N 平面以步长 num_warps 迭代,处理自己负责的 16×8 块。
Warp 内部计算
在每个 warp 内部,需要沿 K 维度迭代,从共享内存加载 A 和 B 子块,然后调用 MMA 指令计算 16×8 块的乘加:
int row = m * 16; // 当前 16×8 块的起始行
int col = n * 8; // 当前 16×8 块的起始列
float c_regs[4] = {0.0f}; // 初始化累加寄存器
// 沿 K 维度迭代
for (int k = 0; k < mma_k; ++k) {
uint32_t a_regs[4]; // A 矩阵寄存器 (16×16 的 8 个 fp16)
uint32_t b_regs[2]; // B 矩阵寄存器 (16×8 的 4 个 fp16)
// 从共享内存加载 A 矩阵子块 (16×16)
int a_row = row + (lane % 16);
int a_col = k * 16 + (lane / 16) * 8;
uint32_t* addr = reinterpret_cast<uint32_t*>(&smem_a[a_row][a_col]);
ldmatrix_4x(addr, a_regs[0], a_regs[1], a_regs[2], a_regs[3]);
// 从共享内存加载 B 矩阵子块 (16×8)
int b_row = k * 16 + lane;
int b_col = col;
uint32_t* baddr = reinterpret_cast<uint32_t*>(&smem_b[b_row][b_col]);
ldmatrix_2x(baddr, b_regs[0], b_regs[1]);
// 调用 MMA 指令进行矩阵乘加 (D = A × B + C)
fma(
c_regs[0], c_regs[1], c_regs[2], c_regs[3], // D 和 C(输出/输入)
a_regs[0], a_regs[1], a_regs[2], a_regs[3], // A
b_regs[0], b_regs[1], // B
c_regs[0], c_regs[1], c_regs[2], c_regs[3] // C(累加)
);
}
// 此时 c_regs 中存储了该 16×8 块的最终结果计算流程:
- 初始化累加寄存器
c_regs为 0 - 沿 K 维度迭代:
- 从共享内存加载 A 和 B 的当前分块
- 调用 MMA 指令,结果累加到
c_regs
- K 维度迭代完成后,
c_regs中包含最终结果 - 将
c_regs写回共享内存或全局内存
完整的 MMA GEMM 实现可参考:CUDA MMA GEMM 示例代码,在我实现的简化版本 flash-attention 的代码中也有使用 MMA 指令的例子。
避免 bank conflict
在使用共享内存时,bank conflict 是一个常见的性能瓶颈。共享内存通常划分为 32 个 bank,如果在一个 wavefront 内多个线程同时访问同一个 bank,就会发生冲突,导致访问串行化,影响性能。ldmatrix 和 stmatrix 指令本质上也是使用基本的共享内存访问指令实现的,因此也可能受到 bank conflict 的影响。在使用 ldmatrix 和 stmatrix 时,需要考虑如何避免 bank conflict。
通用的做法就是使用 swizzle 技术对共享内存中的数据进行重新布局,让一个 ldmatrix 操作中读取的 8 行数据映射到不同的 bank 上。以本文介绍的 m8n8 指令为例,ldmatrix 可以从共享内存中加载 8x8 矩阵。如果使用 x4 模式加载 16×16 矩阵,实际上就是重复了 4 次加载 8 行数据的过程。
我们已经知道,ldmatrix 指令本质上是从 8 个地址中分别读取 8 个两字节的元素,一共加载 128 字节的数据。而 32 个 bank 每个 bank 每次可以提供 4 字节的数据,因此在理想情况下,8 行数据可以分布在不同的 bank 上,这样就不会发生 bank conflict。所以,我们只需要按照 16 字节作为一个单位,对共享内存中的数据进行重新布局,就可以避免 bank conflict。关于 swizzle 技术的详细介绍,可以参考我之前的文章 Swizzle 的工作原理。
比如,对于一个 8x64 的 fp16 矩阵,我们可以按照下面的方式进行 swizzle:

总结
本文系统介绍了 CUDA MMA 指令的使用方法,包括:
- MMA 指令基础:指令格式、参数含义、数据类型和寄存器使用
- 数据布局规则:A、B、C 矩阵在 warp 内 32 个线程中的分布模式
ldmatrix指令:高效加载共享内存数据到寄存器,支持转置加载- 地址计算:如何为不同线程计算共享内存地址,处理各种存储布局
- 实际应用:如何将 MMA 指令集成到通用矩阵乘法(GEMM)中
- 性能优化:避免共享内存 bank conflict 的技巧
掌握 MMA 指令能够显著提升矩阵计算密集型应用的性能,希望本文能帮助你更好地理解和使用这一强大的 GPU 特性。