CUDA 002 - 编程模型
概述
GPU 中包含大量的并行处理单元,这使得它可以执行大规模并行计算任务。为了让开发者能够方便地利用 GPU 的并行计算能力,NVIDIA 提供了 CUDA(Compute Unified Device Architecture)平台。CUDA 对 GPU 的硬件进行了抽象,让开发者能够使用 C/C++ 语言来编写并行程序。本节主要介绍 CUDA 中的软件抽象概念,这些概念可以帮助你在编写并行程序时更清晰地进行思考。
计算单元的软件抽象
一块 GPU 中包含很多的处理单元,这些处理单元可以并行执行多个任务。为了让开发者能够方便地利用 GPU 的计算资源,CUDA 提出了 grid、block、thread 这些概念。
grid 是一个逻辑上的概念,它表示一个并行计算任务的整体。这些计算任务可以被划分为多个 block,GPU 按照 block 来调度并并行执行这些计算任务。一个 block 中包含多个 thread,每一个 thread 可以看做是一个执行流。grid、block、thread 三者的关系如下图所示:

整个计算任务被划分为多个 block,每个 block 中有多个 thread,每个 thread 表示一个执行流,thread 内部执行具体的计算
GPU 在调度任务的时候,会将 block 分配到空闲的处理器上执行。GPU 中调度执行 block 的硬件结构叫做 Streaming Multiprocessors (SM)。不同的 GPU 中包含不同数量的 SM,SM 数量越多性能也就越强。但 GPU 可以根据当前可用的硬件情况来调度 block,开发者不需要关心这里面的细节。虽然是并行计算,但我们应该能想到数据是分多个批次被处理,每个批次处理得越多,自然处理得就越快。

如上图所示,在逻辑上将整个并行任务分为 8 个 block,然后提交给 GPU 执行。第一个 GPU 只有两个 SM,那么它一次性可以执行两个 block,而第二个 GPU 可以一次性执行 4 个 block。最终所有 block 都会被执行,区别在于快慢而已。
目前一个 block 中通常最多包含 1024 个 thread,这个限制是由 GPU 架构决定的。因为 block 是 GPU 中的基本调度单位,在调度执行 block 中的线程时需要申请如寄存器、共享内存等资源,而这些资源是有限的,通常和 thread 数量有关,因此一个 block 中的 thread 数不能太多。
具体在执行时,block 中的所有 threads 会被分为多个大小为 32 的线程束(warp),调度执行时是以 warp 为单位的。

调度器每次选择一个 warp 执行,每个 warp 都有自己的指令指针。在调度执行 warp 时,warp 中所有的 thread 都执行同一条指令,这就是 SIMT(Single Instruction,Multiple Threads)指令执行模式。

当一个 warp 被耗时操作阻塞时,可以调度执行其他 warp。比如访问内存可能会比较慢,当一个 warp 执行了访存指令后,在数据传输期间,可以切换到其他 warp 上执行。当后续数据就位后,可以再切换到此 warp 上执行。这种方式可以降低时延带来的影响,让 GPU 持续工作而不用因为等待数据而停止运行。

线程索引
在使用 CUDA 编程时,一个核心的思想就是将要处理的数据映射到 thread 上。比如 add<<<2, 2>>>(...) 表示启动 2 个 block,每个 block 中包含 2 个 thread。在这 4 个 thread 中,每个 thread 都会执行核函数 add。
__global__ void add(int *x, int *y, int *z, int n) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < n) {
z[i] = x[i] + y[i];
}
}这 4 个线程被分配到了 2 个 block 中,每个 block 中包含 2 个 thread,在线程内部使用 blockIdx.x * blockDim.x + threadIdx.x 计算当前线程的索引,然后获取数据执行加法操作。

CUDA 核函数的启动语法如下:
kernel<<<dim3 gridDim, dim3 blockDim>>>(args);这里 gridDim 和 blockDim 是 dim3 类型的变量,dim3 的定义如下:
struct dim3 {
unsigned int x, y, z;
dim3(unsigned int vx = 1, unsigned int vy = 1, unsigned int vz = 1) : x(vx), y(vy), z(vz) {}
};在 CUDA 中,grid 和 block 可以被组织为 3 维的结构,这可以帮助用户在编写 CUDA 程序时简化思考。
一维索引
在处理一维数据时,我们可以将 grid 和 block 均组织为 1 维的结构。比如,如果要处理 4096 个元素的数据,我们可以这样启动核函数:
float *data = /* 指向设备内存的指针 */;
int N = 4096;
dim3 threads(256);
dim3 blocks((N + threads.x - 1) / threads.x);
kernel<<<blocks, threads>>>(a, N);从代码维度来看,我们的数据被分成了很多组,每一组包含 256 个数据,最终将这些数据映射到 thread 上并行处理。

在 thread 内部,对应的索引可以通过 blockIdx.x * blockDim.x + threadIdx.x 计算得到。
二维索引
如果要处理逻辑上为二维的数据,比如矩阵,可以使用二维结构,这样相当于把矩阵分成了很多个小块,每个小块为一个 block,小块中则包含多个元素,每个元素由一个 thread 处理。下面是一个例子:
dim3 blocks(3, 2);
dim3 threads(3, 2);
kernel<<<blocks, threads>>>(...);
每一个 thread 中可以计算出一个 x 和 y 索引,这个索引可用来访问矩阵中的元素。
x = blockIdx.x * blockDim.x + threadIdx.x;
y = blockIdx.y * blockDim.y + threadIdx.y;三维索引
如果要处理三维数据,可以使用三维的 grid 和 block。比如:
dim3 blocks(3, 3, 3);
dim3 threads(3, 3, 3);
kernel<<<blocks, threads>>>(...);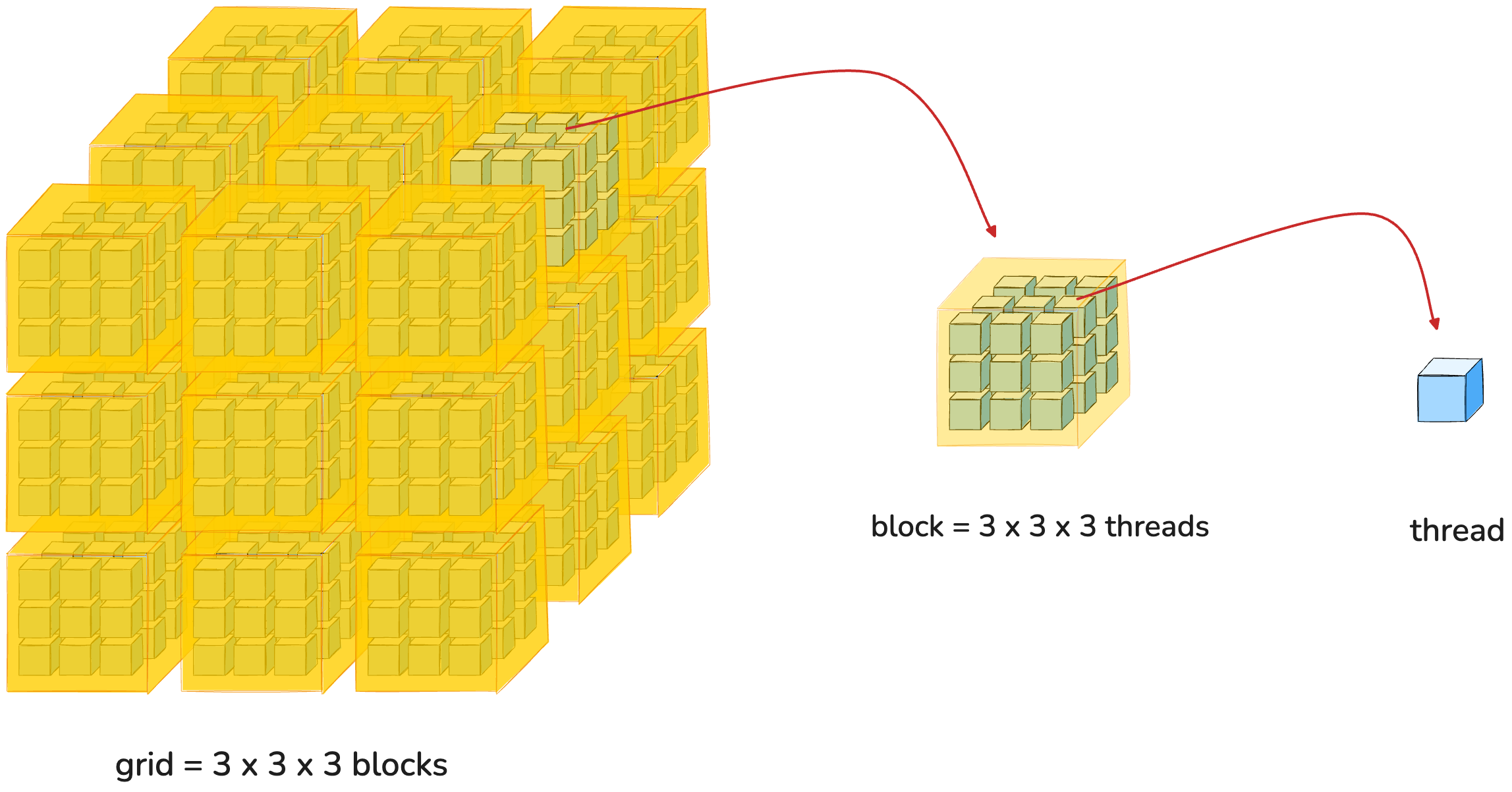
x = blockIdx.x * blockDim.x + threadIdx.x;
y = blockIdx.y * blockDim.y + threadIdx.y;
z = blockIdx.z * blockDim.z + threadIdx.z;实例:矩阵置零
这里使用一个实例来演示如何使用 CUDA 来处理二维数据。这个例子中要做是将一个矩阵中所有元素置零。
首先看核函数的实现:
__global__ void matrixZeroKernel(float *matrix, const int width, const int height) {
const auto x = blockIdx.x * blockDim.x + threadIdx.x;
const auto y = blockIdx.y * blockDim.y + threadIdx.y;
if (x < width && y < height) {
matrix[y * width + x] = 0;
}
}在核函数中,我们分别计算 x 和 y 轴的 index,因为矩阵是按照行优先存储在线性内存中的,所以 matrix[y * width + x] 就是第 y 行第 x 列的元素。
const int width = 1024;
const int height = 512;
float *d_matrix;
cudaMalloc(reinterpret_cast<void **>(&d_matrix), width * height * sizeof(float));
dim3 threads = {16, 16};
dim3 blocks = {(width + threads.x - 1) / threads.x, (height + threads.y - 1) / threads.y};
matrixZeroKernel<<<blocks, threads>>>(d_matrix, width, height);
cudaDeviceSynchronize();启动核函数时,需要先设定 block 的大小,也就是确定一个 block 中有多少个 thread。然后根据 block 的 dim 计算出需要多少个 block。由于输入的元素个数不一定能被 block 大小整除,因此需要使用 (width + threads.x - 1) / threads.x 来向上取整。
总结
本文介绍了 CUDA 中线程索引的概念,包括一维、二维和三维索引。同时,通过一个实例演示了如何使用 CUDA 来处理二维数据。CUDA 提供这一层抽象,使得并行编程更加直观和简单。用户可以按照自己数据的结构来组织 grid 和 block,进而很方便地将数据映射到 thread 上,在 thread 中可以很直观地想到该 thread 负责处理哪些数据。