CUDA 006 - Reduction
This post is about how to implement and optimize reduction in CUDA. Most of the content is the note I was taken when I read Optimizing Parallel Reduction in CUDA.
what is reduction?
reduction is a common comptutation pattern that involves reducing a large set of data to a single summary result, such as sum, average, etc. In some programming languages, they has a built-in reduction function, like Python's reduce in functools module, and reduce in Javascript.
const nums = [1, 2, 3, 4];
function add(sum, current) {
return sum + current;
}
let sum = nums.reduce(add, 0);from functools import reduce
nums = [1, 2, 3, 4]
def add(x, y):
return x + y
sum = reduce(add, nums, 0)reduce function iterates over the whole sequence and call the add function with previus result and current element. You can provide a different function to do different reduction, like min or max.
In CUDA programming, reduction is a common parallel computation pattern. The reduction means processing all the elements and combining them into a single result. For example, summing all the elements in an array, finding the maximum value in an array, etc.
The next sections will discuss how to implement efficient parallel reduction in CUDA.
simple and naive reduction
The simplest way to implement reduction in CUDA is maintain a global variable and use it to store the result. In every threads, we can combine the global result with the element processed by the thread.
__global__ void reduce_naive(const int* input, int n, int* output) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < n) {
atomicAdd(output, input[idx]);
}
}The above code is a simple and unefficient reduction implementation. It uses atomicAdd to ensure that multiple threads can safely update the same global variable without race conditions. However, this approach has several drawbacks:
atomicAddoperations are slow and can become a bottleneck when many threads try to update the same variable simultaneously.- The global memory access is slow, and using it for every thread can lead to poor performance.
- This implementation does not take advantage of shared memory, which is much faster than global memory.
shared memory reduction
To improve the performance of reduction, we can use shared memory to store intermediate results. Each block of threads can compute a partial reduction using shared memory, and then the final result can be computed by combining the partial results from all blocks.
__global__ void reduce_with_shared_memory(const int* input, int n, int* output) {
__shared__ int sdata[1];
if (threadIdx.x == 0) {
sdata[0] = 0;
}
__syncthreads();
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < n) {
atomicAdd(&sdata[0], input[idx]);
}
__syncthreads();
if (threadIdx.x == 0) {
atomicAdd(output, sdata[0]);
}
}The above code uses shared memory to the reduction result for each block. After all threads in the block have finished, the first thread in the block adds the partial result from shared memory to the global output variable. This approach is much faster than the naive reduction because it reduces the number of global memory accesses and uses shared memory. But it still uses atomicAdd, which can be a bottleneck.
Tree-based reduction
A more efficient way to implement reduction is to use a tree-based approach. In this approach, each thread processes two elements at a time and combines them. This process continues until only one element remains, which is the final result.
Here is a picture to illustrate the tree-based reduction:
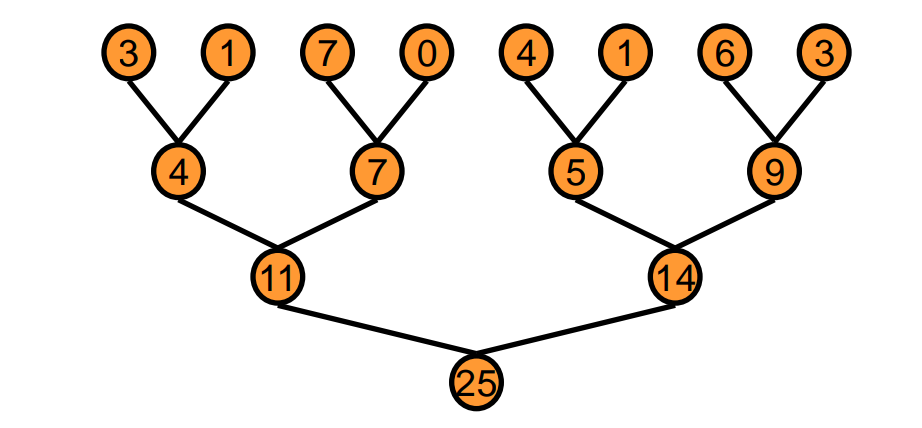
In every iteration, two elements are combined by a thread. After log2(n) iterations, only one element remains, which is the final result. In code implementation, we can use shared memory to store intermediate results and avoid global memory access.
Threads in a block can load data from global memory to shared memory, then perform the tree-based reduction in shared memory. Finally, the first thread in the block writes the partial result to global memory. The global result memory can be an array of size num_blocks to store the partial results from all blocks. Then we can use another kernel to combine these partial results into a final result using tree-based reduction again.
we can call the kernel like this:
void reduce(const int *input, int n, int *output) {
int threads = 256;
int blocks = (n + threads - 1) / threads;
int *partial_results;
cudaMalloc(&partial_results, blocks * sizeof(int));
reduce_kernel<<<blocks, threads, blocks * sizeof(int)>>>(input, n, partial_results);
if (blocks == 1) {
cudaMemcpy(output, partial_results, sizeof(int), cudaMemcpyDeviceToDevice);
} else {
reduce(partial_results, blocks, output);
}
cudaFree(partial_results);
}The above code first launches a kernel to compute partial results for each block. If there is only one block, it copies the result to the output. Otherwise, it recursively calls the reduce function to combine the partial results until only one result remains. Now, we can focus on the kernel implementation.
Tree-based reduction - 0. first version
__global__ void reduce_0(const int* input, int n, int* output) {
extern __shared__ int sdata[];
int idx = blockIdx.x * blockDim.x + threadIdx.x;
int tid = threadIdx.x;
// Load data into shared memory
sdata[tid] = idx < n ? input[idx] : 0;
__syncthreads();
// Tree-based reduction in shared memory
for (unsigned int s = 1; s < blockDim.x; s *= 2) {
if (tid % (2 * s) == 0) {
sdata[tid] += sdata[tid + s];
}
__syncthreads();
}
// Write the result for this block to global memory
if (tid == 0) {
output[blockIdx.x] = sdata[0];
}
}The above kernel first loads data from global memory to shared memory. Then it performs a loop, combining two elements at each iteration. In the first iteration, thread 0 combines element 0 and 1, thread 2 combines element 2 and 3, and so on. After log2(blockDim.x) iterations, the partial result of each block is stored in sdata[0].
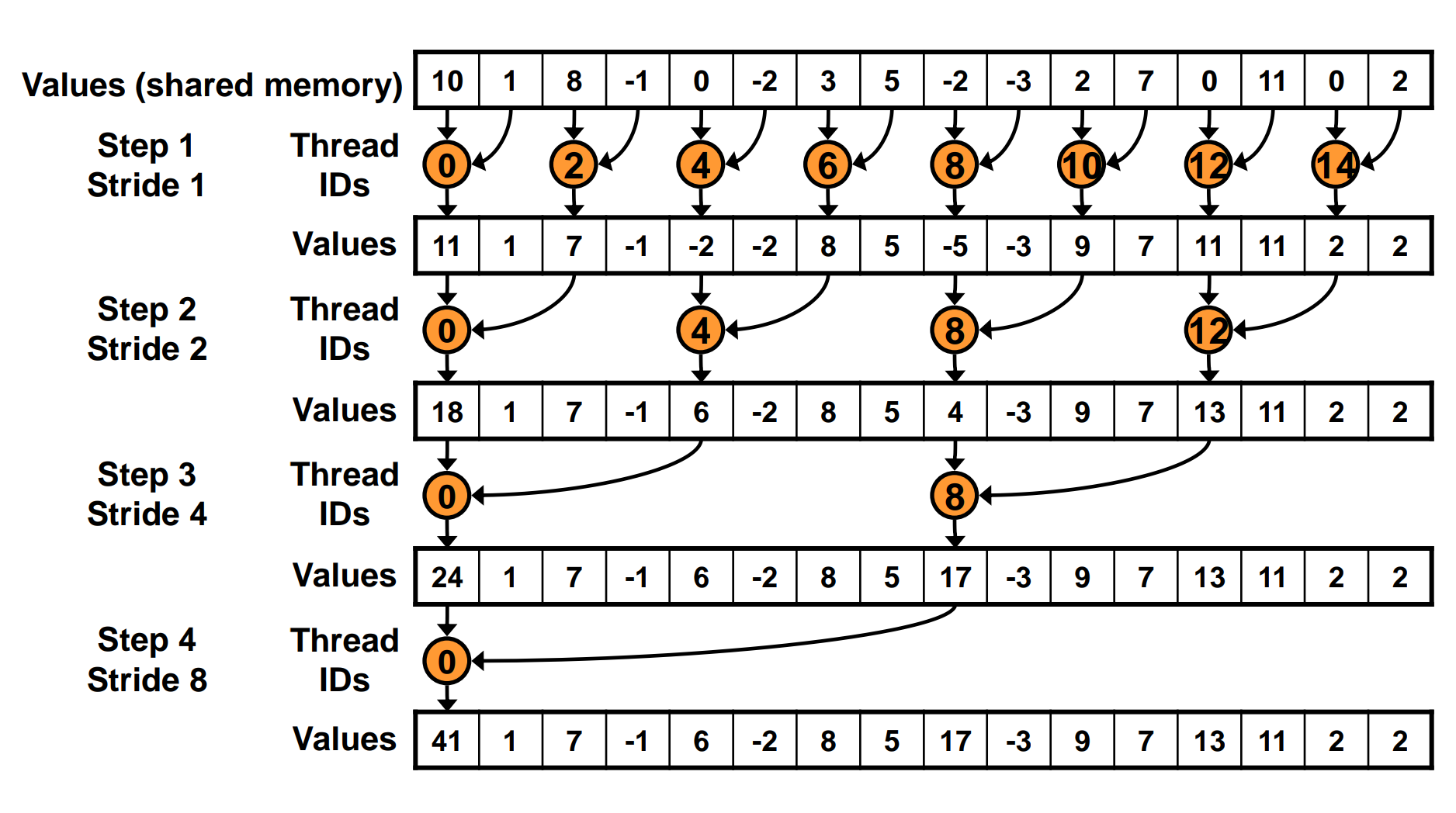
There are two problems with the above implementation:
- the
%operator is very inefficient in CUDA. - after each iteration, half of the threads are idle, but not all threads in a warp are idle. This can lead to warp divergence, which can hurt performance.
Tree-based reduction - 1. avoid warp divergence
We can replace the for loop with the code below:
for (unsigned int s = 1; s < blockDim.x; s *= 2) {
int index = 2 * s * tid;
if (index < blockDim.x) {
sdata[index] += sdata[index + s];
}
__syncthreads();
}After each iteration, only first half of the threads are active, and the other half are idle. This can reduce warp divergence and improve performance.
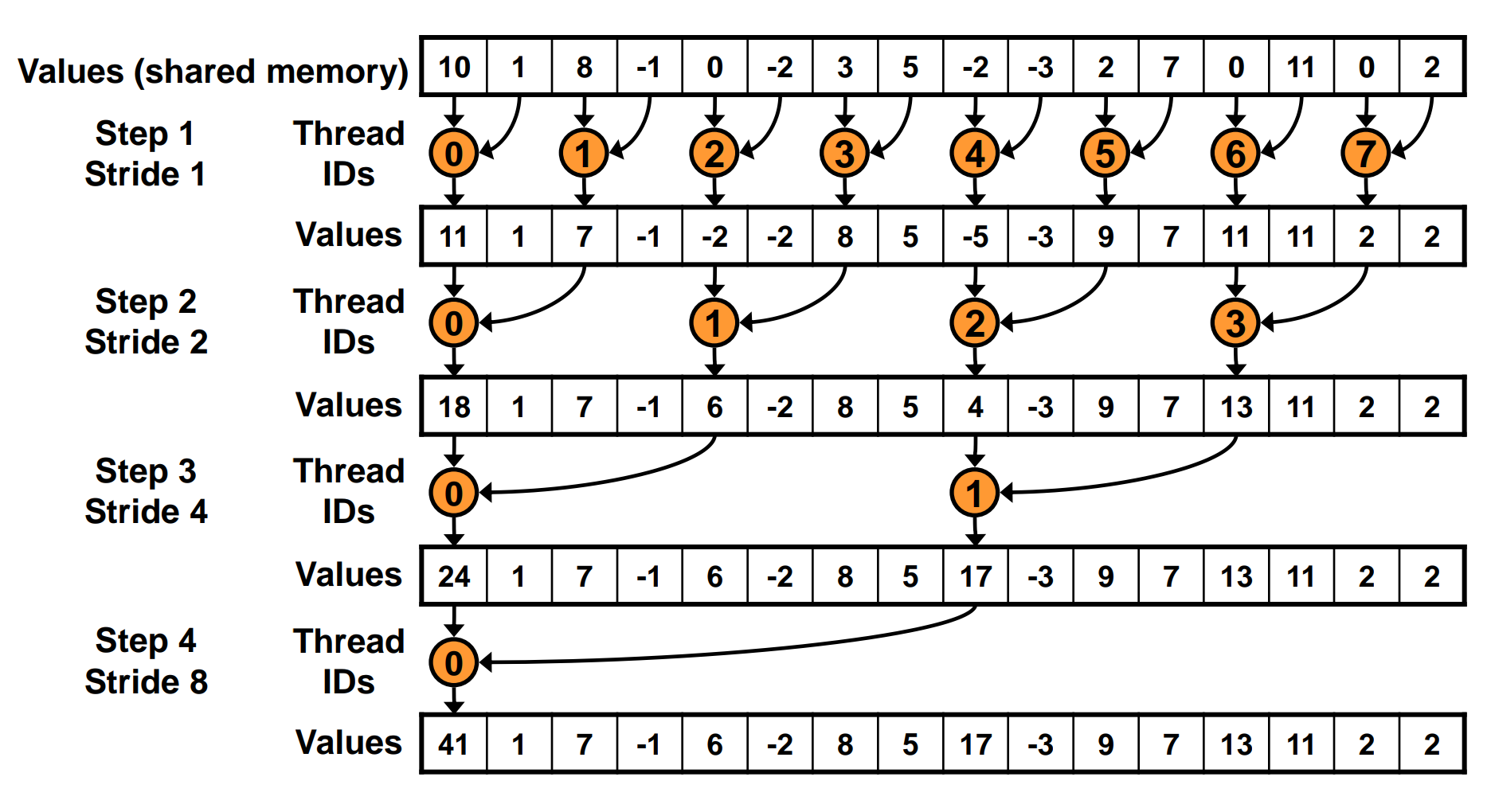
This code solves the warp divergence problem, but it leads to bank conflicts in shared memory access.
bank conflict
In CUDA, shared memory is divided into banks, and accessing different banks can be done in parallel. However, if multiple threads access the same bank, it leads to bank conflicts, which can serialize the accesses and hurt performance. The bank width is usually 32 bytes, if two threads access the addresses which differ by multiple of 32 bytes, they will access the same bank, and the requests will be serialized.
Tree-based reduction - 2. avoid bank conflict
To solve the bank conflict problem, we can change the way we access shared memory. Here is the modified code:
for (unsigned int s = blockDim.x / 2; s > 0; s >>= 1) {
if (tid < s) {
sdata[tid] += sdata[tid + s];
}
__syncthreads();
}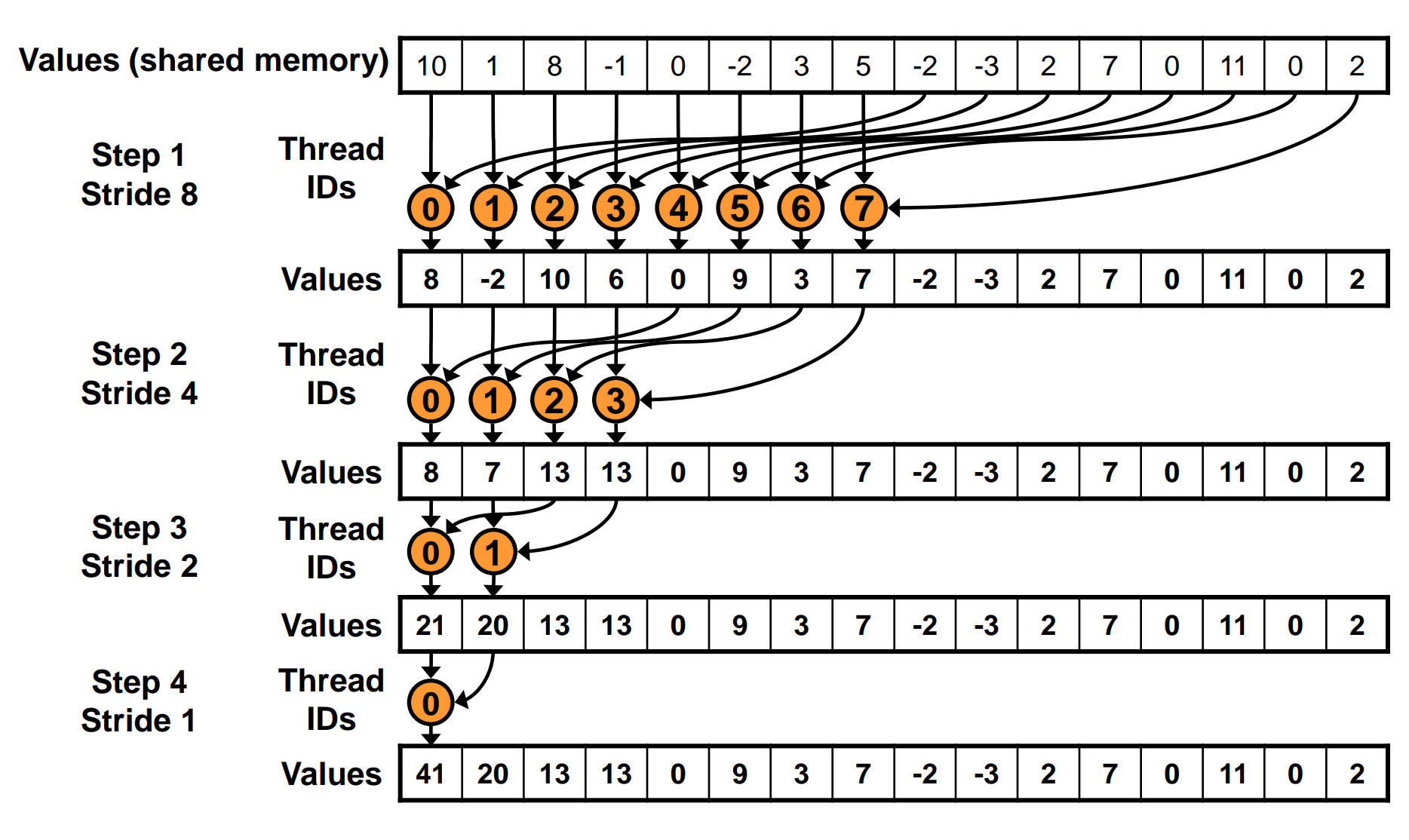
In this code, every iteration, we split the sdata into two halves, and the first half threads combine the elements from the second half. This way, all threads within a warp access sequential addresses in shared memory, and bank conflicts can be avoided.
This implementation is more efficient than the previous ones, as it avoids both warp divergence and bank conflicts. But it still has some room for improvement. After the first iteration, only first half of the threads are active, if we can read the second half of data at the beginning, we can launch fewer threads.
Tree-based reduction - 3. avoid idle threads
In the previous implementation, every thread loads one element from global memory to shared memory. After the first iteration, only half of the threads are active, and the other half are idle. To avoid idle threads, we can have each thread load two elements from global memory and combine them at the beginning.
__global__ void reduce_3(const int* input, int n, int* output) {
extern __shared__ int sdata[];
int idx = blockIdx.x * blockDim.x + threadIdx.x;
int tid = threadIdx.x;
// Load data into shared memory
if (idx < n) {
sdata[tid] = input[idx];
}
if (idx + blockDim.x * gridDim.x < n) {
sdata[tid] += input[idx + blockDim.x * gridDim.x];
}
__syncthreads();
// Tree-based reduction in shared memory
for (unsigned int s = blockDim.x / 2; s > 0; s >>= 1) {
if (tid < s) {
sdata[tid] += sdata[tid + s];
}
__syncthreads();
}
// Write the result for this block to global memory
if (tid == 0) {
output[blockIdx.x] = sdata[0];
}
}When we load data from global memory, each thread loads two elements and combines them. The above code splits data into two parts, the first part has size of blockDim.x * gridDim.x, and the second part is the rest of the data. idx + blockDim.x * gridDim.x is the index of the element in the second part.
Tree-based reduction - 4. using warp shuffle
CUDA provides warp shuffle instructions that allow threads within a warp to exchange data without using shared memory. This can further improve the performance of reduction by reducing shared memory accesses and synchronization overhead.
In the above implementation, after the first few iterations, if the active threads is within a warp, we can use __shfl_down to combine the data.
// Tree-based reduction in shared memory
for (unsigned int s = blockDim.x / 2; s >= 32; s >>= 1) {
if (tid < s) {
sdata[tid] += sdata[tid + s];
}
__syncthreads();
}
if (tid < 32) {
int sum = sdata[tid];
#pragma unroll
for (int offset = 16; offset > 0; offset /= 2) {
sum += __shfl_down_sync(0xffffffff, sum, offset);
}
// Write the result for this block to global memory
if (tid == 0) {
output[blockIdx.x] = sum;
}
}__shfl_down_sync function is used to combine data within a warp. The first argument is the mask, which should be 0xffffffff for all threads in this case. The second argument is the value to be shuffled, and the third argument is the offset to shift down.
Here is a diagram to illustrate how warp shuffle works:
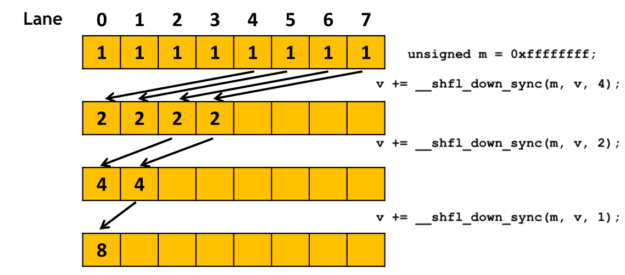
For more details on warp shuffle, you can refer to the official CUDA documentation. Here is a good blog post about warp level primitives.
With warp shuffle, we can further reduce the number of shared memory accesses and synchronization points, leading to better performance for reduction operations in CUDA.
CUDA even provides a built-in function __reduce_add_sync that can be used to perform reduction within a warp in a single line of code:
if (tid < 32) {
// use warp reduce intrinsic
sdata[tid] = __reduce_add_sync(0xffffffff, sdata[tid]);
__syncthreads();
// Write the result for this block to global memory
if (tid == 0) {
output[blockIdx.x] = sdata[0];
}
}Notice: All the threads in the warp which has been selected by the mask should call this function at the same time, otherwise the result is undefined.
Tree-based reduction - 5. multi add per thread
In the optimization 3, avoid idle threads, we perform two global memory accesses per thread. If we can perform more global memory accesses per thread, we can further reduce the number of launched threads.
__global__ void reduce_5(const int *input, int n, int *output) {
extern __shared__ int sdata[];
int idx = blockIdx.x * blockDim.x + threadIdx.x;
int tid = threadIdx.x;
// Load data into shared memory
sdata[tid] = 0;
while (idx < n) {
sdata[tid] += input[idx];
idx += blockDim.x * gridDim.x;
}
//...
}We can split all the data into blockDim.x * gridDim.x chunks, and each thread processes multiple elements by iterating over these chunks. This way, we can further reduce the number of launched threads.
But when I test this code with 4 chunks on my machine, RTX 5070, it performs worse than the previous optimization. This is because the global memory access is within a loop, multi global memory accesses can not perform simultaneously.
I try to solve this problem by passing the number of chunks as a template parameter and unrolling the loop. Here is the final code:
template <int Chunks>
__global__ void reduce_5(const int *input, int n, int *output) {
extern __shared__ int sdata[];
int idx = blockIdx.x * blockDim.x + threadIdx.x;
int tid = threadIdx.x;
// Load data into shared memory
sdata[tid] = 0;
#pragma unroll
for (int i = 0; i < Chunks && idx < n; i++) {
sdata[tid] += input[idx];
idx += blockDim.x * gridDim.x;
}
__syncthreads();
// ...
}This optimization performs better than the previous ones when using 4 chunks on my machine.
Performance comparison
Here is the performance comparison of all the reduction implementations above on my machine:
| Function Name | Duration [ms] | Compute Throughput [%] | Memory Throughput [%] |
|---|---|---|---|
| reduce_naive | 6.73 | 20.91 | 38.26 |
| reduce_shared_memory | 3.93 | 55.48 | 65.01 |
| reduce_0 | 7.15 | 89.75 | 89.75 |
| reduce_1 | 7.24 | 88.58 | 88.58 |
| reduce_2 | 7.04 | 91.14 | 91.14 |
| reduce_3 | 3.90 | 91.17 | 91.17 |
| reduce_4 | 2.86 | 65.34 | 90.23 |
| reduce_5 | 2.65 | 36.17 | 96.50 |
The performance is measured using NVIDIA Nsight Compute. The input size is 400M integers. The results are different with the data showed in Optimizing Parallel Reduction in CUDA. I think this is because of the different GPU architecture and different CUDA version.
From the above table, we can see the naive implementation, which using atomicAdd on global memory, isn't the worst one. Using shared memory improves the performance significantly. The tree-based reduction implementations which process one element per thread can not perform better than the shared memory version. The tree-based reduction implementations which process multiple elements per thread can perform better than the shared memory version. Finally, the final implementation reduce_5 achieves the best performance, with a memory throughput of 96.50%.
The code for all the reduction implementations can be found here.