CUDA 011 - Scan
Scan (also known as prefix sum) is a fundamental parallel algorithm that computes the prefix sums of a sequence of numbers. At the first glance, it may seem unable to parallelize since each output element depends on the previous elements. However, with clever techniques, we can achieve efficient parallel scan operations. In this post, I will explain the basic idea behind parallel scan and provide a simple CUDA implementation.
What is Scan?
Given an input array A of size n, the scan operation produces an output array B such that:
B[i] = OP(A[0], A[1], ..., A[i])Here, OP is a binary associative operation, such as addition, multiplication, or finding the maximum. For example, if OP is addition, the scan operation computes the prefix sums of the array.
There are two types of scan operations:
- Inclusive Scan: The output at index
iincludes the element at indexi. - Exclusive Scan: The output at index
idoes not include the element at indexi.
The inclusive means the prefix sum includes the current element, while exclusive means it does not. The inclusive scan and exclusive scan can be converted to each other with minor adjustments. In this post, we will focus on the inclusive scan.
We can implement scan in serial easily with a simple loop:
void sequential_scan(int* A, int* B, unsigned int n) {
B[0] = A[0];
for (int i = 1; i < n; i++) {
B[i] = B[i - 1] + A[i];
}
}However, this approach is inherently sequential and does not take advantage of parallelism.
Kogge-Stone algorithm
This algorithm is originally designed for fast addition in hardware, but it can be adapted for parallel scan operations. The Kogge-Stone algorithm works in log(n) steps, where n is the number of elements in the input array. In each step, it performs a series of parallel additions to compute the prefix sums.
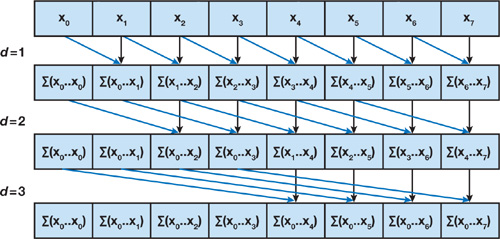
Here is an example to show how the Kogge-Stone algorithm works for an array of size 8:

The input array is [1, 2, 3, 4, 5, 6, 7, 8]. In the first step, we compute the prefix sums for two consecutive elements.
[1, 2, 3, 4, 5, 6, 7, 8] -> [1, 3, 5, 7, 9, 11, 13, 15]Every element at index i is prefix sum of A[i] and A[i-1]. In the second step, we add the prefix sums A[i-2] to A[i] to get the prefix sums for every four consecutive elements:
[1, 3, 5, 7, 9, 11, 13, 15] -> [1, 3, 6, 10, 14, 18, 22, 26]Then we can add the prefix sums A[i-4] to A[i] to get the prefix sums for every eight consecutive elements:
[1, 3, 6, 10, 14, 18, 22, 26] -> [1, 3, 6, 10, 15, 21, 28, 36]Finally, we get the prefix sums for the entire array in just three steps (log2(8) = 3).
We can implement the Kogge-Stone scan algorithm in CUDA as follows:
template <int BLOCK_SIZE>
__global__ void kogge_stone_scan(const float *input, float *output, int N) {
int idx = threadIdx.x + blockDim.x * blockIdx.x;
__shared__ float smem[BLOCK_SIZE];
if (idx < N) {
smem[threadIdx.x] = input[idx];
} else {
smem[threadIdx.x] = 0.0f;
}
for (int stride = 1; stride < BLOCK_SIZE; stride *= 2) {
__syncthreads();
float val = 0;
if (threadIdx.x >= stride) {
val = smem[threadIdx.x] + smem[threadIdx.x - stride];
}
__syncthreads();
if (threadIdx.x >= stride) {
smem[threadIdx.x] = val;
}
}
if (idx < N) {
output[idx] = smem[threadIdx.x];
}
}In this implementation, we first load the input data into shared memory. Then, we perform the Kogge-Stone scan algorithm on the shared memory. This implementation assumes that the input size N is less than or equal to BLOCK_SIZE because we need all threads update the shared memory in each step.
In Kogge-Stone algorithm, in step k, it performs N - k addition. The total number of additions is O(N log N).
Handling Larger Arrays
For larger arrays, we can break the input into blocks, perform scan on each block, and save the block sums to a separate array. Then, we can perform scan on the block sums to get the offsets for each block, and finally add the offsets to each element in the corresponding block.
Here is an illustration of this approach:
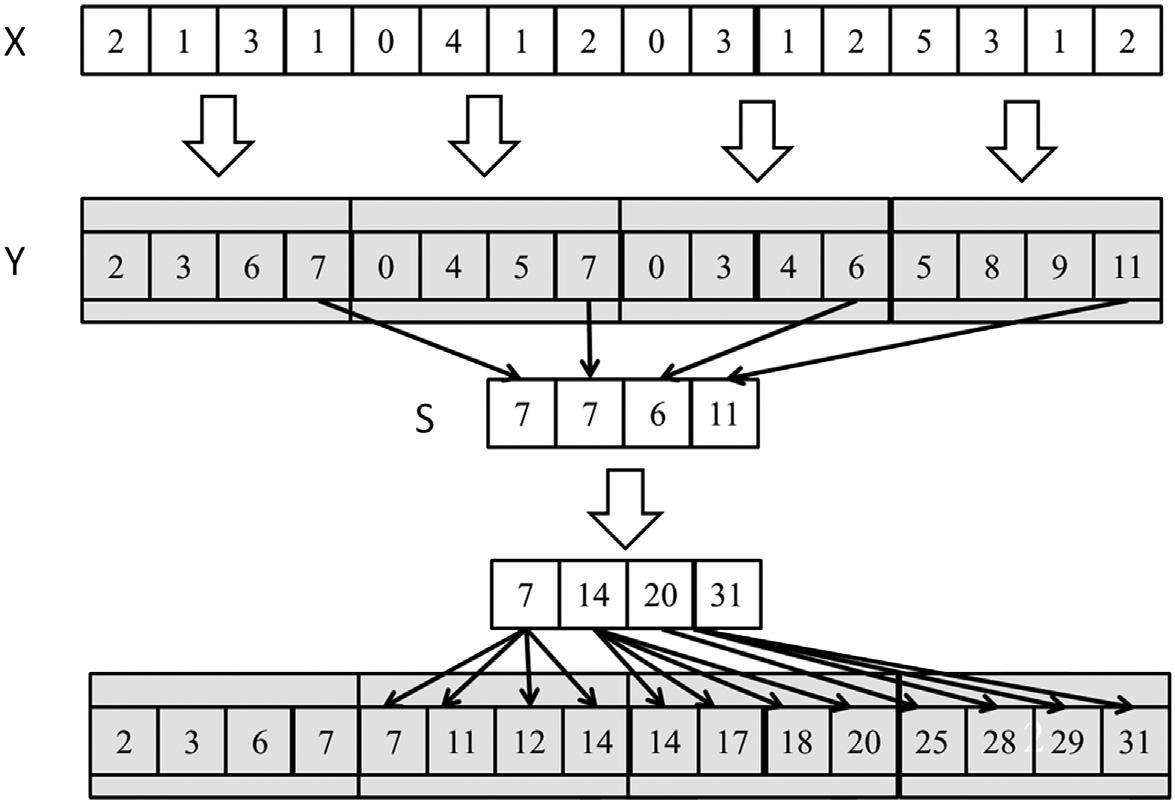 From chapter 11 of Programming Massively Parallel Processors
From chapter 11 of Programming Massively Parallel Processors
Here is the modified kernel to save block sums:
template <int BLOCK_SIZE>
__global__ void kogge_stone_scan(const float *input, float *output, int N, float *block_sums = nullptr) {
// ... (same as above)
// Save the block sum to the block_sums array
if (block_sums != nullptr && threadIdx.x == BLOCK_SIZE - 1) {
block_sums[blockIdx.x] = smem[threadIdx.x];
}
}Next, we need a kernel compute the prefix sums of the block sums and add them to the output:
void prefix_sum(const float* input, float* output, int N) {
dim3 threads = 512;
dim3 blocks = (N + threads.x - 1) / threads.x;
float *block_sums = nullptr;
if (blocks.x > 1) {
cudaMalloc(&block_sums, blocks.x * sizeof(float));
}
kogge_stone_scan<512><<<blocks, threads>>>(input, output, N, block_sums);
if (blocks.x > 1) {
float *block_sums_prefix = nullptr;
cudaMalloc(&block_sums_prefix, blocks.x * sizeof(float));
// Recursively compute the prefix sum of block sums
prefix_sum(block_sums, block_sums_prefix, blocks.x);
// Add the block sums prefix to each block
add_prefix_sum_for_blocks<<<blocks, threads>>>(output, block_sums_prefix, N);
cudaFree(block_sums_prefix);
cudaFree(block_sums);
}
cudaDeviceSynchronize();
}Here is the kernel to add the block sums prefix to each block:
__global__ void add_prefix_sum_for_blocks(float *output, const float *block_prefix_sums, int N) {
int tid = threadIdx.x + blockDim.x * blockIdx.x;
if (blockIdx.x == 0) return; // First block has no offset
float prefix_sum = block_prefix_sums[blockIdx.x - 1];
if (tid < N) {
output[tid] += prefix_sum;
}
}In this way, we can efficiently compute the scan operation for large arrays using a scan kernel only designed for elements within a block.
Optimize with Double Buffering
In the above Kogge-Stone implementation, every loop iteration requires two __syncthreads() calls.
for (int stride = 1; stride < BLOCK_SIZE; stride *= 2) {
__syncthreads();
float val = 0;
if (threadIdx.x >= stride) {
val = smem[threadIdx.x] + smem[threadIdx.x - stride];
}
__syncthreads();
if (threadIdx.x >= stride) {
smem[threadIdx.x] = val;
}
}The first __syncthreads() ensures that all threads have written their values to shared memory so that every thread can read the updated values. The second __syncthreads() ensures that all threads have
read data from shared memory before any thread writes new values.
We need two __syncthreads() here because we read and write to the same shared memory array. If we use double buffering, we can read from one buffer and write to another buffer. In next iteration, we swap the buffers and repeat the process. In this way, we can eliminate one __syncthreads() per iteration.
template <int BLOCK_SIZE>
__global__ void kogge_stone_scan_double_buffer(const float *input, float *output, int N, float *block_sums = nullptr) {
int idx = threadIdx.x + blockDim.x * blockIdx.x;
__shared__ float smem[BLOCK_SIZE * 2];
smem[threadIdx.x] = idx < N ? input[idx] : 0.0f;
__syncthreads();
float *src = smem + BLOCK_SIZE;
float *dst = smem;
for (int stride = 1; stride < BLOCK_SIZE; stride *= 2) {
float *temp = src;
src = dst;
dst = temp;
if (threadIdx.x >= stride) {
dst[threadIdx.x] = src[threadIdx.x] + src[threadIdx.x - stride];
} else {
dst[threadIdx.x] = src[threadIdx.x];
}
__syncthreads();
}
if (idx < N) {
output[idx] = dst[threadIdx.x];
}
if (block_sums != nullptr && threadIdx.x == BLOCK_SIZE - 1) {
block_sums[blockIdx.x] = dst[threadIdx.x];
}
}Here, I use two buffers in shared memory: smem[0..BLOCK_SIZE-1] and smem[BLOCK_SIZE..2*BLOCK_SIZE-1]. In each iteration, we swap the source and destination buffers. This way, we only need one __syncthreads() per iteration, improving the performance of the scan operation.
Brent-Kung algorithm
The concept of Kogge-Stone algorithm is simple, but it is not very efficient in terms of the number of operations performed. In this section, I will introduce another parallel scan algorithm called Brent-Kung algorithm, which reduces the number of operations performed.
Here is how the Brent-Kung algorithm works for an array of size 16:

It performs a reduce phase to compute the partial sums in a tree-like structure. This phase takes log2(N) steps. In the process, it can quichkly pass the prefix sums to the entire array. Based on these prefix sums located at some positions of the array, we can compute the prefix sums for the entire array in another log2(N) steps.
Basically, the Brent-Kung algorithm consists of two phases:
- Reduce tree Phase: Compute the partial sums in a tree-like structure.
- Reverse tree Phase: Use the partial sums to compute the prefix sums for the entire array.
We could implement the reduce phase of the Brent-Kung algorithm in CUDA as follows:
for (int stride = 1; stride < BLOCK_SIZE; stride *= 2) {
if ((threadIdx.x + 1) % (2 * stride) == 0) {
smem[threadIdx.x] += smem[threadIdx.x - stride];
}
}In this implementation, each thread checks if its index satisfies the condition to perform the addition. If it does, it adds the value from the position stride before it.
As stride doubles in each iteration, the number of active threads decreased by half in each step. In a warp, maybe only one thread is active in the later steps, which leads to underutilization of the GPU resources. We can optimize this by always keeping continuous threads active. Here is the optimized version of the reduce phase:
for (int stride = 1; stride < BLOCK_SIZE; stride *= 2) {
// Calculate the index to be updated
int idx = (threadIdx.x + 1) * 2 * stride - 1;
if (idx < BLOCK_SIZE) {
smem[idx] += smem[idx - stride];
}
}The reverse tree phase is more complex. The stride starts from BLOCK_SIZE / 4 and halves in each step until it reaches 1. Comparing to the reduce phase, in reverse tree phase the index needs to update is right shifted by stride. You can notice this from this diagram:

We can implement the reverse tree phase as follows:
for (int stride = BLOCK_SIZE / 4; stride >= 1; stride /= 2) {
int idx = (threadIdx.x + 1) * 2 * stride - 1;
if (idx + stride < BLOCK_SIZE) {
smem[idx + stride] += smem[idx];
}
}The complete Brent-Kung scan kernel is as follows:
template <int BLOCK_SIZE>
__global__ void brent_kung_scan(const float *input, float *output, int N, float *block_sums = nullptr) {
int tid = threadIdx.x + blockDim.x * blockIdx.x;
__shared__ float smem[BLOCK_SIZE];
smem[threadIdx.x] = tid < N ? input[tid] : 0.0f;
__syncthreads();
for (int stride = 1; stride < BLOCK_SIZE; stride *= 2) {
int idx = (threadIdx.x + 1) * 2 * stride - 1;
if (idx < BLOCK_SIZE) {
smem[idx] += smem[idx - stride];
}
__syncthreads();
}
for (int stride = BLOCK_SIZE / 4; stride >= 1; stride /= 2) {
int idx = (threadIdx.x + 1) * 2 * stride - 1;
if (idx + stride < BLOCK_SIZE) {
smem[idx + stride] += smem[idx];
}
__syncthreads();
}
if (tid < N) {
output[tid] = smem[threadIdx.x];
}
if (block_sums != nullptr && threadIdx.x == BLOCK_SIZE - 1) {
block_sums[blockIdx.x] = smem[threadIdx.x];
}
}Performance Comparison
The Kogge-Stone algorithm performs O(N log N) additions, while the Brent-Kung algorithm reduces this to O(N) additions. But the Brent-Kung algorithm requires 2 * log2(N) steps, which is more than the Kogge-Stone algorithm's log2(N) steps. I tested both algorithms on an array of size 10 million elements. The results are as follows:
| Algorithm | Time (ms) |
|---|---|
| Kogge-Stone | 1.424 |
| Kogge-Stone (double buffer) | 1.389 |
| Brent-Kung | 1.753 |
| Brent-Kung (one thread handle two elements) | 1.371 |
Conclusion
In this post, I introduced the scan operation and explained how to implement it in parallel using the Kogge-Stone and Brent-Kung algorithms. The final implementation can be found here: prefix-sum.