CUDA 013 - Swizzle 的工作原理
本文介绍 CUDA 编程中 swizzle 技术的原理,并对 CuTe 库中实现的通用 swizzle 映射规则做详细解析。为便于理解,我实现了一个可视化工具(见下文“可视化工具”部分),读者可以通过调整参数动态观察映射效果。
直达可视化工具:swizzle-visualization
什么是 memory bank
共享内存(Shared Memory)是线程块内部用于快速数据交换的高速存储。在硬件层面,内存通常被划分为多个可并行访问的存储单元,这些单元在 DRAM 或 GPU 共享内存语境下通常称为 memory bank。
下图为 memory bank 的示意:
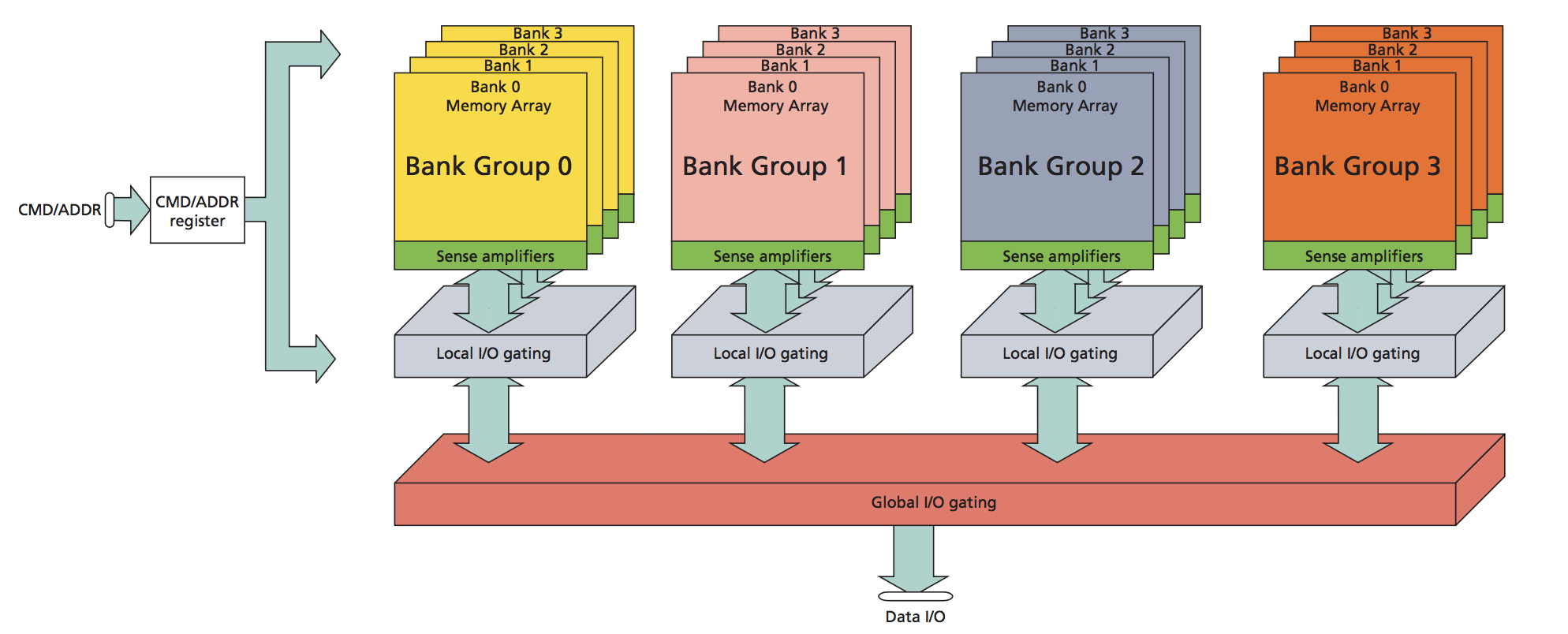
不同 memory bank 的访问可以并行执行,从而提高内存带宽利用率。为了让数据均匀分布到各个 bank,地址通常由低位决定所属 bank。例如,若有 32 个 bank、每个 bank 宽度为 4 字节,则地址到 bank 的映射如下:
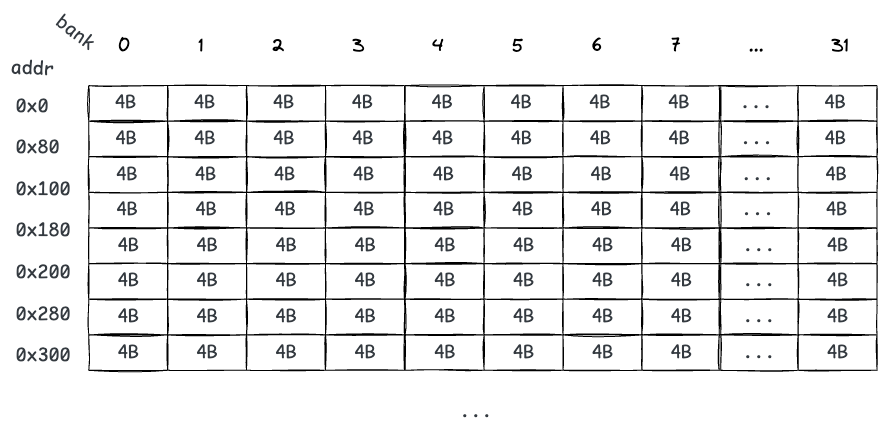
字节 0–3 映射到 bank 0,字节 4–7 映射到 bank 1,依此类推。对齐到 128 (0x80) 字节的一段连续数据会被分布到 32 个 bank 上。
什么是 Bank Conflict
在 NVIDIA GPU 中,共享内存通常被划分为 32 个 memory bank,每个 bank 的宽度常为 4 字节。如果 warp 内的 32 个线程访问落在不同的 bank,那么这些访问可以并行处理:

但若多个线程访问同一个 bank,访问将被串行化。这种现象称为 Bank Conflict;若 N 个线程同时访问同一 bank,则该 bank 的请求会被分为 N 次序列化访问(N-way Bank Conflict)。

如何避免 Bank Conflict
在共享内存中,数据通常以二维数组(行优先,row-major)布局存放。以 32x32、每个元素 4 字节的矩阵为例,其内存布局如下:
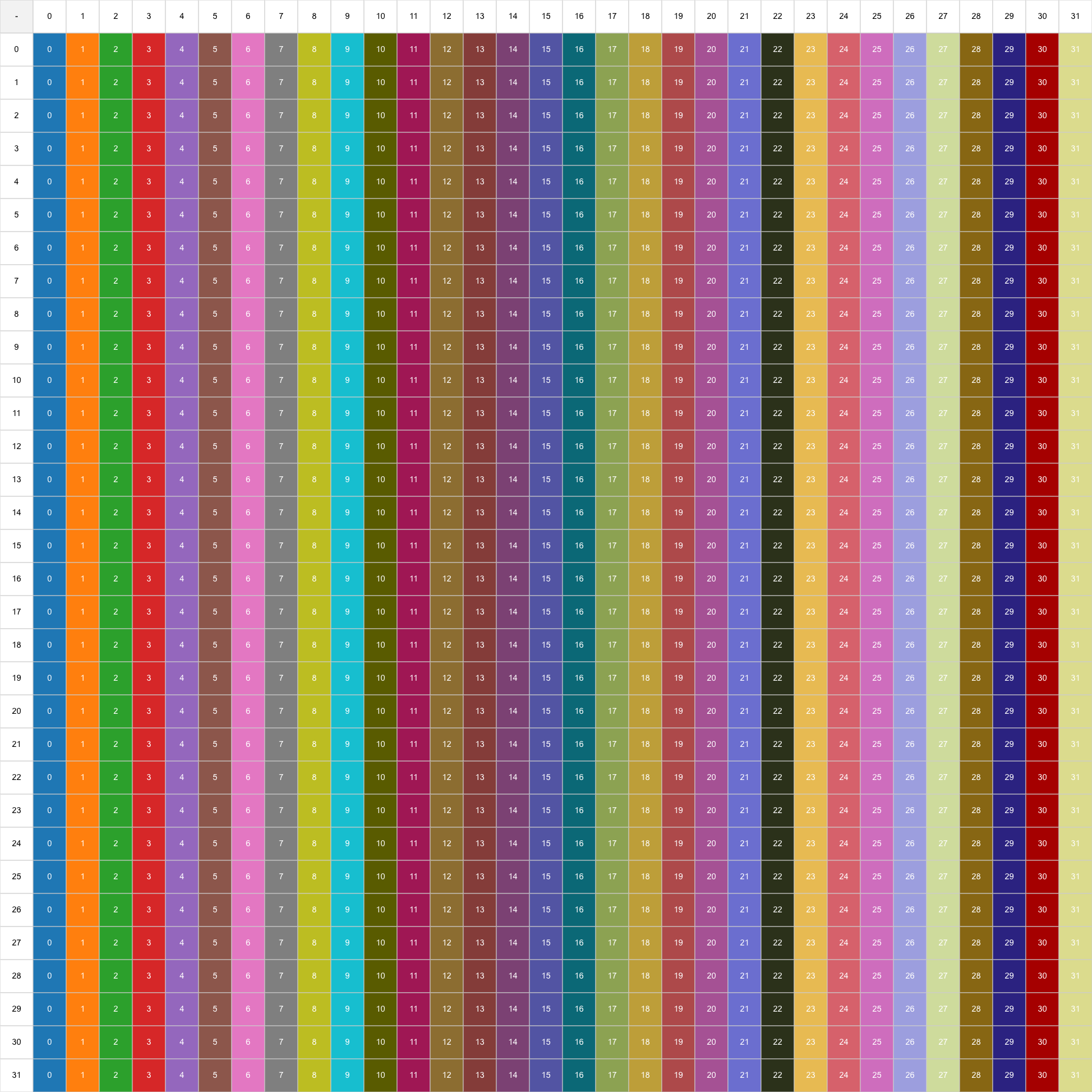
图中同色块表示映射到相同的 memory bank。每行的 32 个元素分布到 32 个 bank,而每列则会映射到同一个 bank。因此,当 warp 的 32 个线程同时访问同一列时,就会发生 Bank Conflict。
一种常见的解决办法是改变每行的宽度,例如将行宽从 32 改为 33:
__shared__ float array[32][33];二维数组在共享内存中的布局如下图所示:

这样每一行多出的一个元素会使后续行的 bank 映射发生位移,从而打破列到单一 bank 的映射关系。不过,这会浪费一些共享内存。另一种更节省空间的方法就是本文的主角——Swizzle 技术。
Swizzle 技术
在 CUDA 中,swizzle 用来改变二维数组在共享内存中的映射规则,从而避免 Bank Conflict,同时不额外占用共享内存。
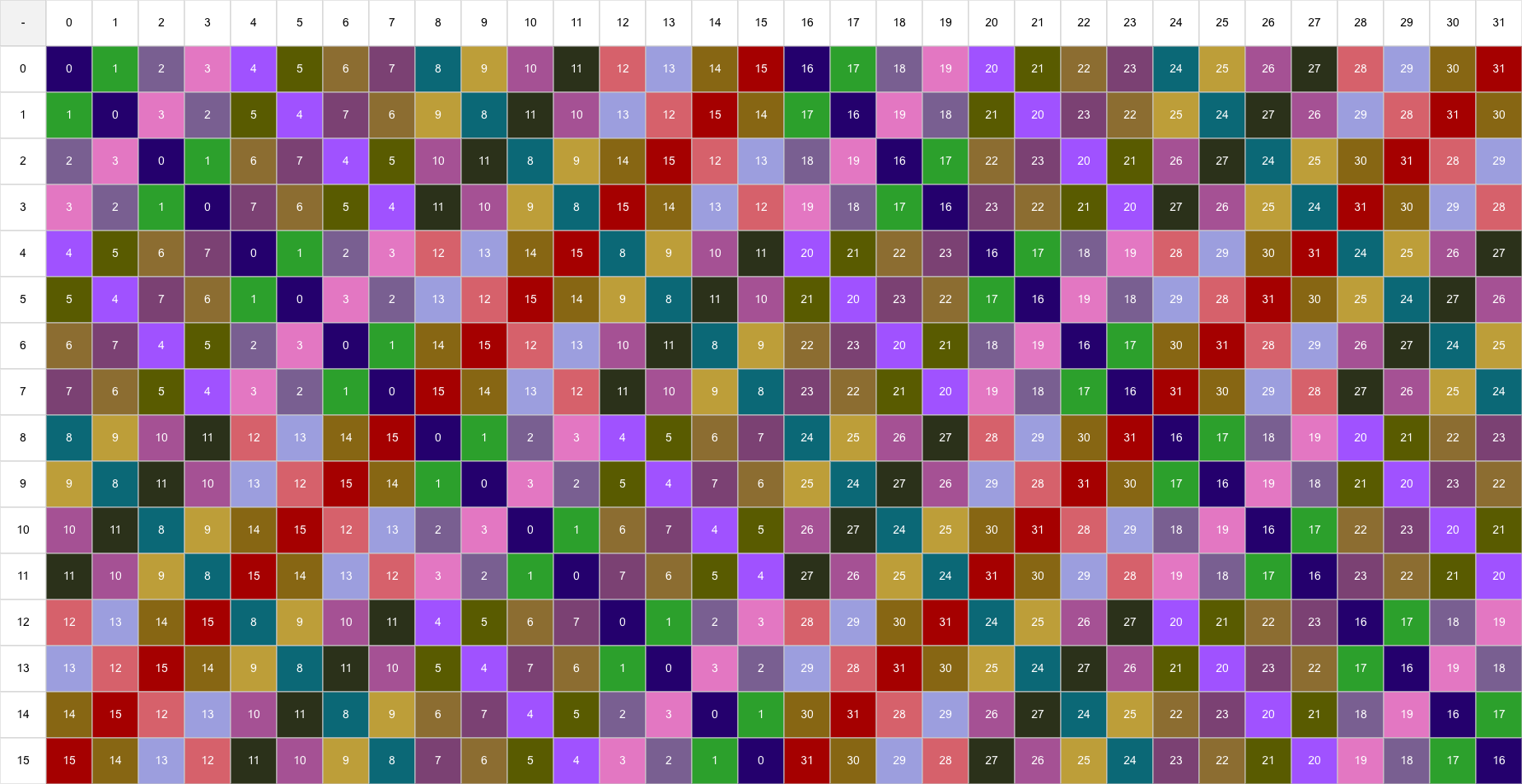
以前面的 32x32 矩阵为例,按常规布局第一列全部映射到同一 bank。如果我们把原先在同一列的元素重新映射到不同列(即不同 bank),就能避免冲突。下图展示了将第一列重排到不同列的示意:

映射实质上是把逻辑坐标 (row_l, col_l) 转换为物理坐标 (row_p, col_p)。映射应当一一对应(无多对一),因此不改变数据量。Swizzle 的优点是不需要额外共享内存,但读写时需进行索引变换,会带来少量计算开销。
一种常见且高效的映射策略是使用按位异或(XOR):
def mapping(y, x):
return y, x ^ y上述函数将逻辑坐标 (y, x) 映射为物理坐标 (y, x ^ y),即用行号的某些位与列号异或,打乱列的顺序,使得原来同列的数据分散到不同列,从而减少冲突:

异或操作本质上交换了某些位。例如 0 ^ 4 = 4,4 ^ 4 = 0:在第 4 行,会交换第 0 列和第 4 列的元素,从而打乱原有顺序。映射后每列上的索引不再重复,类似于数独中每行每列无重复的约束。
swizzle 映射案例
下面我们看一些不同的二维矩阵使用 swizzle 映射的实例。
int nums[32][32]
对于标准的 32x32 矩阵,可以直接使用前面提到的 mapping(y, x) = (y, x ^ y)。
int nums[64][32]
若矩阵有 64 行,可以把矩阵按纵向分割为两个 32x32 的子矩阵,分别做 swizzle;计算时对 y 取模即可,例如:
def mapping(y, x):
COLS = 32
return y, x ^ (y % COLS)int nums[32][64]
若列数为 64,可将矩阵按横向分为两个 32x32 子矩阵,对每个子矩阵分别做 swizzle:
def mapping(y, x):
COLS = 32
x_base = x // COLS * COLS # 当前子矩阵起始列
x_offset = x % COLS
return y, x_base + (x_offset ^ y)
half nums[32][64] 向量化访问
当使用 half(16-bit)并希望每个线程访问连续的两个元素时,swizzle 必须保证这两个元素在映射后仍保持连续。做法是跳过 offset 的最低 1 位(即不对其进行映射):
def mapping(y, x):
x_offset = x % 2 # 组内偏移
x = x // 2 # 组号
return y, (x ^ y) * 2 + x_offset这样映射后,每组的两个元素仍然保持连续:

小结
本节介绍了 swizzle 的基本思想:通过索引映射重新分布数据,以减少 bank conflict。针对不同矩阵形状可以设计不同的映射函数,但这显得不够通用——后文介绍的基于 offset 的通用规则可以统一处理多种情况。
更通用的映射规则
CuTe 是一个用于 CUDA 编程的 C++ 模板库,其中实现了一种更通用的 swizzle 映射规则。在 CuTe 中,映射是基于全局 offset 来进行的。假设有一个二维数组,行数为 rows,列数为 cols,那么逻辑坐标 (x, y) 对应的全局 offset 为:
offset = y * cols + x通常列数都是 2 的幂次方,因此如果将 offset 写为二进制形式,它的低位部分 XXXXX 保存了列号 x,高位部分 YYYYY 保存了行号 y。
offset = 0bYYYYXXXX比如 int nums[32][64],逻辑坐标 (10, 33) 对应的全局 offset 为 673,其二进制形式为:
0b 1010 100001
---- ------
YYYY XXXXXX得到 offset 后,可以从其中提取行号和列号,再进行 swizzle 映射。
回忆前面对 32x64 矩阵的 swizzle 映射方式,我们是将其视为两个 32x32 矩阵来处理的。因此在提取列号时,只需要提取出列号的低 5 位 XXXXX,而忽略掉高位部分。提取出行号时也只需要提取出行号的低 5 位 YYYYY。
0b 1010 100001
---- -----
YYYY XXXXX提取低位,就相当于做了取余操作。提取出行号和列号之后,swizzle 映射函数会计算出 AAAAA = XXXXX ^ YYYYY,然后将 offset 中的 XXXXX 部分替换为 AA 部分:
0b 1010 101011
---- -----
YYYY AAAAA最终得到新的 offset 为 683,对应的物理坐标为 (10, 43)。
CuTe 通用 swizzle 映射规则解析
在 CuTe 库中,为了支持更加通用的映射规则,swizzle 映射函数从 offset 中提取行号和列号时,并不是直接提取所有的位,而是提取出列号的一部分 ZZ 和行号的一部分 YY,如下所示:
0bxxxxxxxxxxxxxxxxYYxxxxxxxxxZZxxx其中 ZZ 表示列号的一部分,它之所以不是 offset 的最低位部分,是因为有时候需要去掉 offset 的低位部分,从而实现保证一组连续元素的顺序不被改变。YY 表示行号的一部分。ZZ 和 YY 是列号和行号的低位部分,相当于做了取余操作。而 YY 和 ZZ 之间的位数由矩阵的列宽决定。
提取出 YY 和 ZZ 之后,swizzle 映射函数会计算出 AA = ZZ ^ YY,然后将 offset 中的 ZZ 部分替换为 AA 部分,最终得到新的 offset:
0bxxxxxxxxxxxxxxxxYYxxxxxxxxxAAxxx从 offset 中提取 YY 和 ZZ 时需要注意几点:
1. 保持一组元素的连续性
如果希望在重新映射后,一组元素(两个、4个、8个等)保持连续且不被打乱,在提取 ZZ 部分时,需要跳过 offset 的最低位部分。
0bxxxxxxxxxxxxxxxxYYxxxxxxxxxZZxxx
^^^
最低位假设希望每 4 个元素作为一组保持连续不变,那么就可以跳过最低的 2 位不进行 swizzle 映射。这样在提取 ZZ 部分时,就需要从 offset 的第 2 位开始提取。
最低位保持不变的位数,就相当于将多个元素打包为一个元素,因此后续处理中行号和列号实际上是基于打包后的矩阵来计算的。比如 char nums[64][128],每个元素占用 1 字节,如果希望每 4 个元素作为一组保持连续不变,那么就相当于将矩阵视为 int nums[64][32] 来处理,此时列宽为 32。
2. 行列位数
因为一共有 32 个 memory bank,每个 bank 宽度为 4 字节。元素的大小的不同,导致参与 swizzle 的列宽度会有所不同。如果元素为 8 字节,那么每 16 个元素就能占据 32 个 bank,因此在做 swizzle 映射时,是以 16x16 矩阵为单元进行映射的。此时列号 ZZ 只需要提取 4 位即可。
这里 YY 和 ZZ 的位数是由元素大小决定的。如果是 4 字节,那就以 32x32 矩阵为单元做 swizzle,此时 YY 和 ZZ 都需要提取 5 位。如果元素为 8 字节,就以 16x16 矩阵为单元做 swizzle,此时 YY 和 ZZ 都需要提取 4 位。
0bxxxxxxxxxxxxxxxxYYxxxxxxxxxZZxxx
^^ ^^
提取的行和列的位数,由参与 swizzle 的行列宽决定3. 列宽度位数
想要从 offset 中提取出行号,就需要知道列宽是多少。假设矩阵有 256 列,那么列号就需要 8 位来表示。因此在提取 YY 时需要知道列宽和最低位跳过的位数。
0bxxxxxxxxxxxxxxxxYYxxxxxxxxxZZxxx
^^^^^^^^^^^
列宽度位数计算公式
我们将前述 offset 中三个重要的位数定义为 base、bits 和 shift,如下图所示:
bits bits
-- --
0bxxxxxxxxxxxxxxxxYYxxxxxxxxxZZxxx
...........---
shift base这里的 base、bits 和 shift 我采用了和 CuTe 库中相同的命名方式。
base:表示将 个元素作为 swizzle 变换的基本元素,后续 swizzle 都是针对新的基本元素进行操作。也就是跳过 offset 的最低base位不进行 swizzle 映射。bits:表示提取出列号和行号的位数,其本质是将 个基本元素作为一组参与 swizzle 映射。shift:表示列宽度的位数。假设矩阵一行有cols个基本元素,那么shift = log2(cols)。
因为 swizzle 映射的本质就是将 offset 做如下变换:
0bxxxxxxxxxxxxxxxxYYxxxxxxxxxZZxxx
变换为:
0bxxxxxxxxxxxxxxxxYYxxxxxxxxxAAxxx
其中 AA = ZZ ^ YY。基于上述总结,我们可以实现一个通用的 swizzle 映射函数:
template<int base, int bits, int shift>
int swizzle(int offset) {
unsigned int bits_mask = (1 << bits) - 1;
int zz = (offset >> base) & bits_mask;
int yy = (offset >> (base + shift)) & bits_mask;
int aa = zz ^ yy;
offset = offset & ~(bits_mask << base); // 清除 ZZ 部分
offset = offset | (aa << base); // 设置 AA 部分
return offset;
}使用示例
1. int num[32][128]
以 int 元素为基本元素,不需要跳过最低位,所以 base = 0。以 32x32 矩阵为单元参与 swizzle,因此需要提取 5 位 bits = 5。矩阵有 128 列,因此列部分有 7 位 shift = 7。
constexpr int base = 0; // 以 int 元素为基本元素,不需要跳过最低位
constexpr int bits = 5; // 以 32x32 矩阵为单元参与 swizzle,列号需要提取 5 位
constexpr int shift = 7; // 矩阵有 128 列,因此列部分有 7 位使用上述参数进行 swizzle 映射时,可以通过下面的代码实现:
for (int y = 0; y < 32; y++) {
for (int x = 0; x < 128; x++) {
int offset = y * 128 + x;
offset = swizzle<base, bits, shift>(offset);
int new_x = offset % 128;
int new_y = offset / 128;
// 访问 num[new_y][new_x]
}
}映射后,使用新的 offset 计算出新的逻辑坐标进行访问。通常我们都是在一行数据中进行 swizzle 映射,但通过 offset 来做 swizzle 映射,可以忽略掉矩阵的具体行列结构,从而实现更加通用的映射规则。
可视化如下:

2. char num[64][128]
此时希望每 4 个 char 元素作为一组保持连续不变,因此需要跳过最低的 2 位,所以设置 base = 2。因为基本元素包含 4 个字节,此时可以使用 32x32 矩阵为单元进行 swizzle 映射,因此 bits = 5。矩阵有 32 列,因此 shift = 5。
int base = 2;
int bits = 5;
int shift = 5;可视化如下:

3. float4 num[32][64]
基本元素占用 16 个字节,因此 8 个基本元素就可以占据 32 个 memory bank,因此以 8x8 矩阵为单元进行 swizzle 映射,所以 bits = 3。矩阵有 64 列,因此 shift = 6。
int base = 0;
int bits = 3;
int shift = 6;可视化如下:

4. int num[32][8]
这种场景下,矩阵的一行不足以覆盖 32 个 memory bank,但可以将连续的 4 行视为有 32 个元素的一行,然后以 32x32 矩阵为单元进行 swizzle 映射。
int base = 0;
int bits = 5;
int shift = 5;因为是以 4 行作为一组进行 swizzle 映射,因此元素会在每 4 行之间进行交换。原来在同一行的数据,映射之后会分布到不同的行中。通常我们习惯在一行内进行 swizzle 映射,这种场景较少见,可通过调整矩阵行列或访问方式来避免。
你可以使用后文提到的可视化工具,动态调整参数,观察映射结果。
小结
使用一维的 offset 来执行 swizzle 映射,可以忽略掉矩阵的具体行列结构,从而实现更加通用的映射规则。通过配置 base、bits 和 shift 三个参数,可以适应不同矩阵大小和元素大小的需求。通过在 offset 中提取出行号和列号特定部分,CuTe 库中的 swizzle 映射函数可以灵活地实现各种映射规则。
CuTe 库中实现的 swizzle 映射函数,正是基于上述原理来实现的。我这里只是换了一种写法。感兴趣的可以去CuTe 源码中查看具体实现。
可视化工具
为了更直观地理解 swizzle 映射的效果,我实现了一个可视化工具,读者可以通过调整参数,动态观察 swizzle 映射的结果。
CUDA Shared Memory Swizzling Visualization
Element size:
Base: 0
Bits: 5
Shift: 5
Enable swizzle:
显示模式:
Rows: 32
Cols: 32
- 方块的颜色表示不同的 memory bank。相同颜色表示数据被映射到相同的 memory bank。
- 如果一个元素跨多个 bank,则显示为第一个 bank 的颜色。
- 方块中的数字表示该元素在该行的逻辑列地址。如坐标 (2,3) 中数字为 0,表示在做 swizzle 前,该元素的逻辑地址坐标为 (2,0)。
点击某个 bank 来切换其可见性:
总结
swizzle 技术通过索引映射的方式,重新分布数据在不同的 memory bank 中,从而有效地避免了 Bank Conflict 问题。通过合理设计映射函数,可以适应不同矩阵大小和元素大小的需求。CuTe 库中提供的通用 swizzle 映射函数,使得用户可以灵活配置映射规则,提升共享内存的访问性能。借助 CuTe 实现的 swizzle 类中的思想,我们可以轻松地实现各种 swizzle 映射规则,从而优化 CUDA 程序的性能。
在初学映射规则时,我觉得非常难理解,尤其是 CuTe 中实现的通用映射规则,但当我一步步推导每个例子时,逐渐理解了其中的原理。如果你刚开始接触 swizzle,建议可以从简单例子开始,自己分析每个映射逻辑。然后就会发现 CuTe 中实现的通用映射规则很符合直觉。你也可以使用上面的可视化组件,动态调整参数,观察映射结果,从而加深理解。