CUDA 008 - Matrix Transpose
Matrix transposing is a common operation in linear algebra. For a matrix of size , the transpose matrix is a matrix of size . The element at row and column in the original matrix is equal to the element at row and column in the transpose matrix.

In this post, I will demostrate how to transpose a matrix using CUDA. I will start with a simple version and then optimize it with shared memory.
Naïve Transpose
In the following post, I will use a matrix of size (m rows, n columns) stored in a single-dimensional array and assume that the matrix is stored in row-major order.
![]()
The naive approach launches a thread grid with threads, where each thread is responsible for copying a single element from the original matrix to its corresponding position in the transpose matrix.
__global__ void transpose_naive(const T* in, T* out, int m, int n) {
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
if (y < m && x < n) {
out[x * m + y] = in[y * n + x];
}
}We can launch the kernel with a 32x32 block size and a grid size of rows by columns.
constexpr int WIDTH = 4096;
constexpr int HEIGHT = 8192;
dim3 block(32, 32);
dim3 grid((WIDTH + block.x - 1) / block.x, (HEIGHT + block.y - 1) / block.y);
transpose_naive<<<grid, block>>>(d_in, d_out, HEIGHT, WIDTH);Threads in a 2D block are mapped to matrix in, threads in a warp will read from the same row of in and write to the same column in out. When read from in, the addresses are consequtive, all read operations can be coalesced. However, when writing to out, the addresses are not consequtive and all write operations cannot be coalesced.
![]()
A thread block has 32x32 threads, which are 32 warps. Each warp reads from the same row of in and writes to the same column in out. The addresses are consequtive for read operations but not for write operations.
When read from in, the performance is very good, read 32 elements per cycle. However, when writing to out, the performance is poor because each thread writes discontiguous memory.
GPU perform write operations in memory transactions of minimum size of 32 bytes, and this means that even if you only write a four-byte value, the GPU will flush 32-bytes of data from the L1 cache to L2 cache.
From the memory workload analysis of Nsight compute we can see that the kernel read 134.22 MB data from L2 Cache, but write 1.07 GB data to L2 Cache. A 4096x8192 matrix has 128 MB data, this means only 1/8 of data is useful. This is what we expected, because each 4-byte write operation will cause a 32-byte memory transaction.
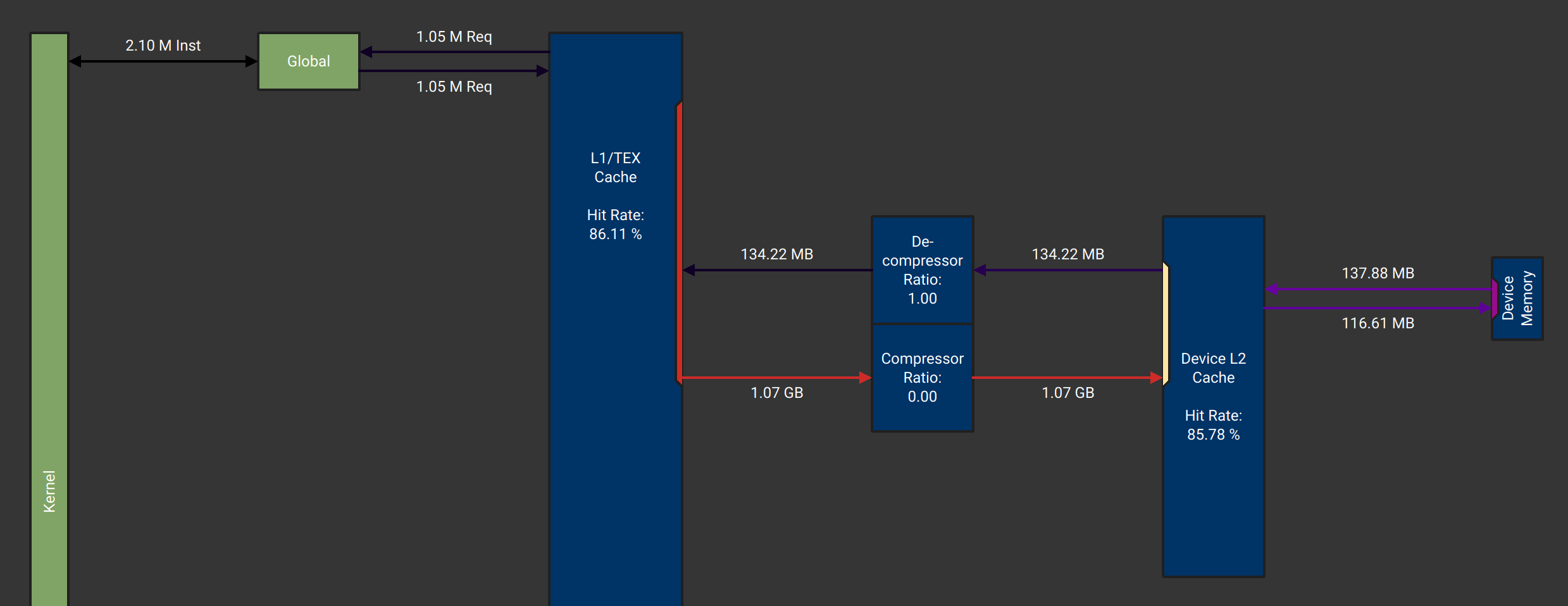
If we set the thread block width as 8, with size 32x8 or 64x8, each warp will have 4 rows and 8 columns. When reading from in, 8 threads in a row will read consequtive addresses and issue a 32-byte memory transaction. When writing to out, 4 threads in a row will write consequtive addresses and issue a 32-byte memory transaction(only 16 bytes are useful).
dim3 block(8, 64);
dim3 grid((WIDTH + block.x - 1) / block.x, (HEIGHT + block.y - 1) / block.y);
transpose_naive<<<grid, block>>>(d_in, d_out, HEIGHT, WIDTH);![]()
In this way, we can improve the writing performance by 4 times. Now, 1/2 of writing data is useful, but still not efficient enough.
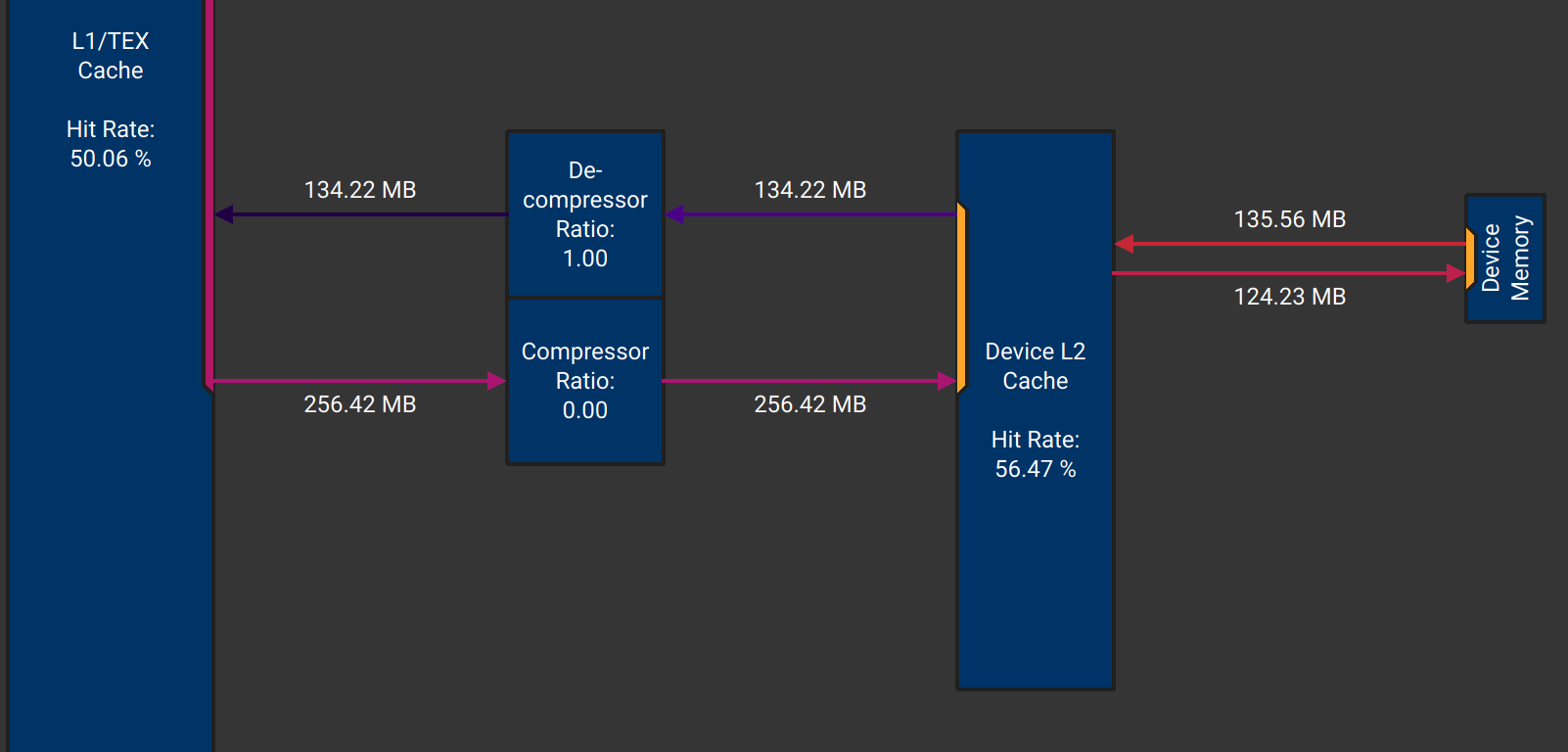
Here is the statistics of the kernel for different block sizes:
| Block Size | Read (MB) | Write (MB) | Duraion (ms) |
|---|---|---|---|
| 32x32 | 134.22 | 1095.68 | 1.45 |
| 16x16 | 134.22 | 480.80 | 0.49 |
| 32x8 | 134.22 | 253.73 | 0.49 |
Transpose with Coalesced Memory Access
The issue of the naive transpose kernel is that it can not perform both reading and writing efficiently at the same time. When reading from in, threads in a warp read consequtive addresses, but when writing to out, threads in a warp write discontiguous addresses.
If we can read multiple lines in a thread, then we can write multiple columns in a thread. In this way, both reading and writing can be coalesced. So here comes an idea can efficiently transpose a matrix with coalesced memory access.
If we can set the thread block width as 16, the warp's size is 2x16, the first row of threads can read 4x16 elements, and the second row of threads can read another 4x16 elements. After transposing, the one row of threads have 16x4 elements to write. The whole warp has 16x8 elements to write. In this way, both reading and writing are coalesced.
Here is the figure to illustrate how a warp can read 8x16 elements and write 16x8 elements:
![]()
Here is the code for this kernel (the out of boundary issue is not considered):
__global__ void transpose_with_coalesced_memory(const float* in, float* out, int m, int n) {
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
y *= 4;
float4 a;
a.x = in[y * n + x];
a.y = in[(y+1) * n + x];
a.z = in[(y+2) * n + x];
a.w = in[(y+3) * n + x];
*reinterpret_cast<float4 *>(&out[x * m + y]) = a;
}When launching the kernel, we can set the block size as 16x16, since each thread reads 4 elements through the y direction, the block size in the y direction should be divided by 4 when calculating the grid size.
dim3 block(16, 16);
dim3 grid((WIDTH + block.x - 1) / block.x, (HEIGHT + block.y - 1) / block.y / 4);
transpose_with_coalesced_memory<<<grid, block>>>(d_in, d_out, HEIGHT, WIDTH);Now, both the data read from L2 Cache and written to L2 Cache are 134.22 MB, no bandwidth waste anymore. I think this is nearly the best kernel for matrix transpose. If we want further optimization, we can try to handle more elements in a single thread.
Here is some metrics from Nsight Compute:
| L2 Cache Read (MB) | L2 Cache Write (MB) | Duraion (ms) |
|---|---|---|
| 134.22 | 134.22 | 0.47 |
Transpose with Shared Memory
Another commonly mentioned method to transpose a matrix is using shared memory. Shared memory is a fast scratchpad memory, and we can read a tile of data from global memory into shared memory, then write the tile to global memory, both with coalesced memory access. The foillowing figrue shows how we can use shared memory to achive efiicient matrix transpose.
![]()
The follwoing code perfroms matrix transpose with shared memory.
template<int TILE_DIM>
__global__ void transpose_tiling(const float* in, float* out, int m, int n) {
__shared__ float tile[TILE_DIM][TILE_DIM];
int x = blockIdx.x * TILE_DIM + threadIdx.x;
int y = blockIdx.y * TILE_DIM + threadIdx.y;
tile[threadIdx.y][threadIdx.x] = in[y * n + x];
__syncthreads();
x = blockIdx.y * TILE_DIM + threadIdx.x;
y = blockIdx.x * TILE_DIM + threadIdx.y;
out[y * m + x] = tile[threadIdx.x][threadIdx.y];
}Threads in a block read a tile of data from global memory into shared memory. Group of threads in a warp read consequtive addresses from global memory, so the read operations are coalesced. After all threads finish reading, we use __syncthreads() to synchronize all threads in the block. Then, threads in a warp read column from shared memory and write to a row of matrix out, and the write operations are also coalesced.
You should take care of the coordinates when reading and writing data. Here is a figure to illustrate how to get x, y coordinates from blockIdx and threadIdx:
![]()
bank confilict
When using shared memory, we need to consider bank conflict. Shared memory is divided into 32 banks and each thread can access one of the banks. If multiple threads in a warp try to access different banks, there will be no conflict.

If multiple threads in a warp try to access to the same bank at the same time, there will be a bank conflict. When baank conflict happens, the memory access will be serialized. If all 32 threads in a warp try to access the same bank, all 32 memory accesses will be serialized. The performance will be degraded to 1/32.

There is one exception worth noting: If mulitple threads access the exact same address in the same bank, the hardware will broadcast the value to all threads in a single cycle. This avoids the bank conflict.
Back to transpose kernel above, we write data to shared memory by using the following code:
tile[threadIdx.x][threadIdx.y] = in[y * n + x];Threads in a warp will write data to a column of the shared memory. If we set TILE_DIM to 32, each element in the column has stride of 4*32 = 128 bytes, this means all threads in a warp will access the same bank and a 32-way bank conflict will happen.
avoid bank conflict
To avoid bank conflict, we can make the elements in a column loacated in different banks. Here is the bank mapping for a 4x32 tile:

the number in a ceil is the bank index, each column located in a same bank
How about 4x33 tile? Here is the bank mapping:

You have noticed that each column is maped to a different bank. This is a common tecnique to avoid bank conflict by adding one extra padding column. After padding, each row hase 33 elements, this extra 1-element offset make every row starts at address with 1-bank shift.
We can modify the kernel to avoid bank conflict by adding one extra column:
__shared__ float tile[TILE_DIM][TILE_DIM+1];After solving the bank conflict, we can see a significant performance improvement:
| Duraion (ms) | |
|---|---|
| before | 0.94 |
| after | 0.69 |
Multi Elements per Thread
In the former kernel, the block size is same as the tile size, 32x32 threads process a 32x32 tile, each thread process one element. In order to improve the instruction-level parallelism and hide memory latency, we can make each thread process multiple elements.
In the following kernel, the tile is TILE_DIM x TILE_DIM, and the thread block size is less than the tile size, one thread has to process multiple elements.
template<int TILE_DIM, int BLOCK_SIZE>
__global__ void transpose_tiling_multi_elements(const float* in, float* out, int m, int n) {
__shared__ float tile[TILE_DIM][TILE_DIM + 1];
int tx = blockIdx.x * TILE_DIM;
int ty = blockIdx.y * TILE_DIM;
const int tid = threadIdx.y * blockDim.x + threadIdx.x;
#pragma unroll
for (int i = 0; i < TILE_DIM * TILE_DIM; i += BLOCK_SIZE) {
int idx = i + tid;
int x = idx % TILE_DIM; // index in tile
int y = idx / TILE_DIM;
int gx = tx + x; // global index in matrix `in`
int gy = ty + y;
if (gx < n && gy < m) {
tile[y][x] = in[gy * n + gx];
}
}
__syncthreads();
tx = blockIdx.y * TILE_DIM; // tile index in matrix `out`
ty = blockIdx.x * TILE_DIM;
#pragma unroll
for (int i = 0; i < TILE_DIM * TILE_DIM; i += BLOCK_SIZE) {
int idx = i + tid;
int x = idx % TILE_DIM;
int y = idx / TILE_DIM;
int gx = tx + x;
int gy = ty + y;
if (gx < m && gy < n) {
out[gy * m + gx] = tile[x][y];
}
}
}firstly, all threads read data from matrix in into shared memory in a loop with stride of BLOCK_SIZE, then synchronize all threads. After that, all threads read data from shared memory tile and write them to matrix out in another loop with stride of BLOCK_SIZE.
Performance
Here is the performance statistics of different transpose kernels:
| Kernel | Duration (ms) |
|---|---|
| Naïve (32x32 block) | 1.45 |
| Naïve (16x16 block) | 0.49 |
| Naïve (32x8 block) | 0.49 |
| Coalesced Memory Access | 0.45 |
| Tiling (32x32 block) | 0.94 |
| Tiling + Padding (32x32 block) | 0.69 |
| Tiling + Padding + 16 elements/thread (64x64 tile, 16x16 block) | 0.43 |
| Tiling + Padding + 4 elements/thread (32x32 tile, 16x16 block) | 0.45 |
| cuBLAS | 0.43 |
Summary
In this post I prensented two kernels to transpose a matrix: one is naive and the other is using shared memory. The naive kernel shows the importance of memory coalescing. The shared memory kernel shows how to use shared memory to coalesce global memory access and how to avoid bank conflict by padding. Looking at the relative performance gains, we can see that oalescing global memory access and avoiding bank conflict are very critical factors of achieving high performance.
Appendix
matrix transpose with cuBLAS
#include <cublas_v2.h>
// in: m x n (m rows, n columns)
void transpose_cublas(const float* in, float* out, int m, int n) {
cublasHandle_t handle;
cublasCreate_v2(&handle);
float alpha = 1.0f;
float beta = 0.0f;
cublasSgeam(handle, CUBLAS_OP_T, CUBLAS_OP_N, m, n, &alpha, in, n, &beta, nullptr, m, out, m);
cublasDestroy(handle);
}You can find the code in this post on Github.