Flash Decoding - 基本原理
在前面的文章中,我介绍了 Flash Attention 的基本原理,在阅读本文时,我假设你对 Flash Attention 的原理已经有了基本了解,知道如何对数据分块,如何使用 online softmax 来渐进地完成 attention 的计算。如果你尚不清楚,建议先了解 Flash Attention 的原理,这是理解 Flash Decoding 的基础。
Flash Attention 在训练阶段和推理的预填充(Prefill)阶段表现出色,这两种场景下,输入的都是完整的序列,在计算 attention 时,、、 的长度相同,因为 中各个 token 之间相互独立,Flash Attention 对 进行分块并行处理,可以有效地利用 GPU 的计算资源。
但在推理的解码(Decode)阶段,decode 的输入是上一轮输出的 token,此时 Query 序列极短(通常仅一个 token),而 Key 和 Value 则包含了之前所有 token 的信息(当前 token 的 KV + KV Cache)。随着生成的 token 不断增多,K/V 的长度也会持续增长,可能达到数千甚至数万个 token。此时如果输入的 batch 较小,则会因为任务量不足,导致 GPU 的计算资源无法被充分利用。
为了解决在 decode 阶段,并行度不足的问题,Tri Dao 等人提出了 Flash Decoding,专门针对解码进行优化,通过在 KV 维度上进行分块并行计算,显著提升了解码阶段的注意力计算效率。在 Flash Attention 的源码中已经实现了 Flash Decoding 的算法。
本文将详细描述 Flash Decoding 的原理,同时给出代码实现。另外我在 mini-flash-attention中实现了 Flash Decoding 的 CUDA 版本,感兴趣的读者可以参考源码。
LLM 推理的两个阶段
在深入了解 Flash Decoding 之前,我们需要先了解大语言模型(LLM)推理的两个阶段,即预填充(Prefill)和解码阶段(Decode)。
预填充阶段(Prefill)
当用户输入一段 prompt 时,模型对输入的所有 token 做完整的前向计算。在这个阶段,、、 的序列长度都等于 prompt 的长度。例如用户输入了 1024 个 token 的 prompt,那么 、、 的行数都是 1024。此时 Flash Attention 可以在 的维度上做分块并行计算,GPU 的利用率很高。
这里复用我在 Flash Attention 的基本原理 中的图示:

在计算时可以将 分为多个块,每个分块由一个线程块(Thread Block)处理,每个 块和所有的 和 块进行注意力计算,得到该 块对应的输出。这个阶段,GPU 有较多的任务可以执行,计算资源可以被充分利用。
下面是两层循环的伪代码,GPU 可以在外层循环的分块上并行执行:
for bq in range(0, n, Bm): # 外层循环:遍历 Q 的分块,可并行
bQ = Q[bq:bq+Bm, :]
for bk in range(0, n, Bn): # 内层循环:遍历 K/V 的分块,串行
bK = K[bk:bk+Bn, :]
bV = V[bk:bk+Bn, :]
...解码阶段(Decode)
预填充完成后,会得到 prompt 中所有 token 的 K/V 缓存(KV Cache),此后模型开始逐个生成新的 token。在预填充阶段, 有很多行,外层循环可以分成很多块并行执行,GPU 的 SM(流多处理器)可以被充分利用。但在解码阶段, 只有一行(或几行),外层循环的迭代次数为 1,只有一个线程块在工作,如果输入 batch 较小,则可能有大量 SM 处于空闲状态。而这就是 Flash Decoding 需要解决的问题。
Flash Decoding 的核心思想
Flash Decoding 的解决方案很直观:既然 Q 维度没有足够的并行度,那就在 KV 维度上引入并行。具体做法是将内层循环对 KV 的遍历拆分为多个独立的并行任务:
- Split-KV 并行计算:将 KV Cache 沿序列维度切分为多个块(split),每个块由一个独立的线程块处理。每个线程块独立计算其负责的 KV 块对应的局部注意力结果。
- 归约(Reduce):所有线程块完成计算后,通过一次归约操作将各个局部结果合并为最终的全局注意力输出。
下图展示了 Flash Decoding 的计算流程:

将 K/V 切分为多个块,Q 分别与多个 KV 块进行注意力计算,最终将结果归约合并为全局输出。
下面还有一个来自 PyTorch 的博客中的动画示意:
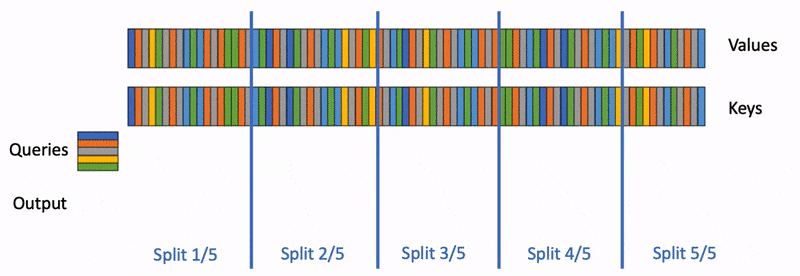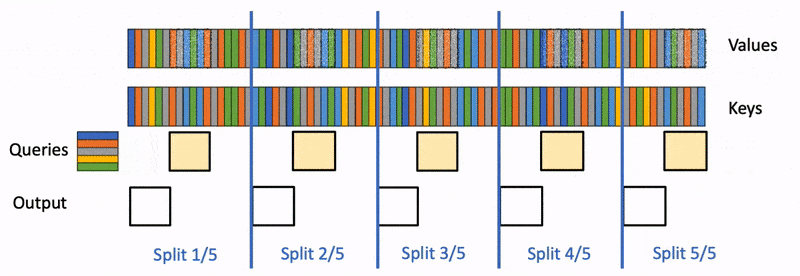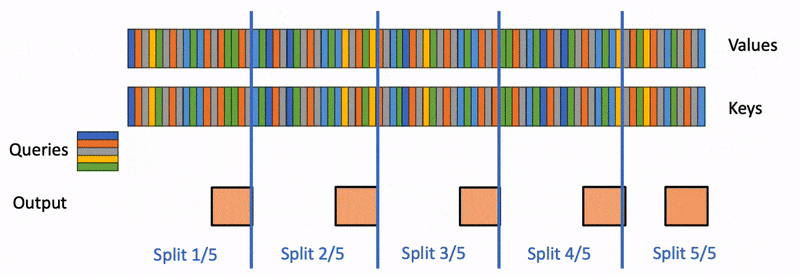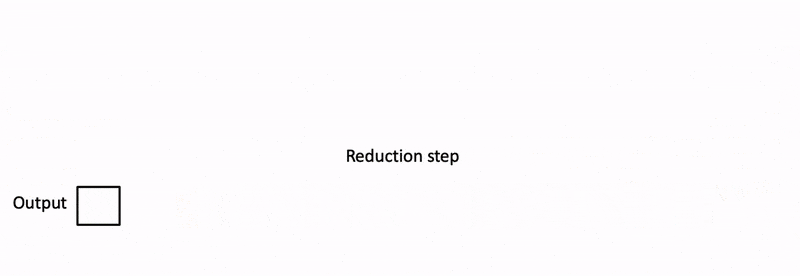
Flash Decoding 的计算过程
下面我使用公式来描述 Flash Decoding 的计算过程。
单个 KV 分块
对于第 个 KV 块,设其中包含的注意力分数为 (即 与该块中第 个 Key 的点积除以 )。
该块的注意力分数最大值为:
做了数值稳定性处理的指数和:
局部加权求和为:
在计算 时,使用了最大值 进行数值稳定化处理。但本质上 的值和下面式子的结果完全相同(分子分母同时乘以 ):
合并多个 KV 块的结果
现在考虑合并两个分块的输出,我们记分块 1 的输出为 ,其 softmax 分母中的指数和为 ,分块 2 的输出为 ,其 softmax 分母中的指数和为 。则合并过程可以分为以下几步:
第一步:计算全局指数和
全局指数和为:
第二步:修正各块的加权求和
将每个分块的输出的分母替换为全局指数和:
第三步:累加各分块的结果
合并后的输出为:
使用 LSE 优化合并逻辑
前面描述的分块结果合并算法要求每个 K/V 分块保存局部的输出 以及局部最大值 和局部指数和 。在 Flash Attention 的代码实现中,实际上对每个分块除了输出 之外,只保存一个 LSE(Log-Sum-Exp)值。
LSE 的定义
LSE 即 Log Sum Exp,它的定义为:
在编程实现时,LSE 会使用如下公式计算:
其中 。
下面是推导过程:
LSE 本质上是 softmax 归一化分母的对数形式。阅读后文你就会明白,其实每个分块只需要这一个统计量就可以完成分块的合并操作。
使用 LSE 合并分块
对于分块 k,其输出为:
其中 是第 个分块的注意力分数的最大值。这里使用了最大值进行了数值稳定化处理,这是防止在编程时出现数值溢出的问题。理论上它的值等价于:
在合并时,其原理就是将分母替换为全局的指数和,从而得到全局归一化的输出。因此可以对 进行如下变换:
这样就消除掉了原来的局部指数和,并使用全局的指数和。而这个计算过程可以使用 LSE 来表示。
假设有两个块的 LSE 分别为 和 ,对应的输出为 和 ,则最终输出 的计算如下:
初次看这个计算公式的时候,大概难以看明白,但只要稍微展开一下,就很容易看懂。
将 展开后可得:
展开后可得:
这样就使用 LSE 完成了多个分块的合并操作,但是其本质就是调整每个分块的 softmax 的分母,将局部指数和替换为全局指数和。
LSE 实际上只包含了 softmax 的分母中指数和部分的信息。虽然在编程实现的时候会使用如下公式来计算:
但这仅仅是为了防止数值溢出。虽然公式中出现了最大值 ,但实际上 LSE 中并没有包含最大值的信息,而且也不需要最大值。
下面两个式子是完全相同的:
虽然在编程实现时, 使用的是第一个式子来计算的,它使用了最大值 来防止数值溢出。但在使用 LSE 进行分块合并时, 其实被视为第二个式子。因此只需要知道每个分块的指数和就可以完全多个分块输出的合并了。
代码实现
这里我给出代码实现的示例,如果前面的公式把你弄的有点晕,那么看下面代码或许能帮助你更好地理解。
import torch
# 计算单个 K/V 分块的 attention,输出当前分块的结果和 LSE
def flash_decoding_single_block(q: torch.Tensor, k: torch.Tensor, v: torch.Tensor):
s = q @ k.T / (q.size(-1) ** 0.5)
row_max = s.max(dim=-1, keepdim=True).values
exp_s = (s - row_max).exp()
expsum = exp_s.sum(dim=-1, keepdim=True)
out = (exp_s / expsum) @ v
lse = row_max + expsum.log()
return out, lse
# 对多个分块进行合并
def flash_decoding_reduce(splits):
global_lse = torch.zeros_like(splits[0][1])
for _, lse in splits:
global_lse += lse.exp()
global_lse = torch.log(global_lse)
global_out = torch.zeros_like(splits[0][0])
for (out, lse) in splits:
global_out += out * torch.exp(lse - global_lse)
return global_out
# 执行 flash attention
def flash_decoding(q: torch.Tensor, k: torch.Tensor, v: torch.Tensor):
splits = []
for i in range(0, 1024, 256):
out, lse = flash_decoding_single_block(q, k[i:i+256], v[i:i+256])
splits.append((out, lse))
out = flash_decoding_reduce(splits)
return out
q = torch.randn(1, 128)
k = torch.randn(1024, 128)
v = torch.randn(1024, 128)
out = flash_decoding(q, k, v)
print(out)
# 简单的 attention 实现,用于结果对比
def attention(q: torch.Tensor, k: torch.Tensor, v: torch.Tensor):
s = q @ k.T / (q.size(-1) ** 0.5)
row_max = s.max(dim=-1, keepdim=True).values
exp_s = (s - row_max).exp()
expsum = exp_s.sum(dim=-1, keepdim=True)
return (exp_s / expsum) @ v
out = attention(q, k, v)
print(out)总结
Flash Decoding 解决了 LLM 解码阶段 Flash Attention 并行度不足的问题,其原理其实很好理解。在 Flash Attention 的实现中,使用了 LSE(Log-Sum-Exp)值来记录每个分块的归一化信息,最后基于 LSE 对各个分块的输出进行合并。而这个过程相对而言比较难理解,本文给出了比较详细的公式推导。最终合并的计算过程就是使用如下两个公式:
你可以将其展开,然后试着推导,就很容易明白其中的原理。在 Flash Attention 的实现中,之所以对指数和取对数,保存 LSE 而非直接保存指数和,我想这是为了避免指数和过大导致的数值溢出问题。