机器学习 - 逻辑回归
Logistics Regression
本文要讨论一个分类模型,Logistics Regression,中文名通常为逻辑回归,名字中虽然包含回归,但却实实在在是个分类模型。
模型定义
逻辑回归的模型可以很自然地从线性回归中引入,在二分类任务中,可以把样本分为正负两类,我们可以根据样本的特征来预测它为正例的概率。设样本为正的概率为 $P(x)$,可以得出以下模型:
$$ P(x) = w·x + b $$
这里整个模型还是线性回归模型,只不过线性回归模型的目标是样本为正例的概率。有了这个模型后,对于所有正例样本,可以设为正例的概率为 1,否则为 0,然后使用线性模型来训练。
事实证明这个模型也是可以工作的,但不够好,线性回归模型的输出可以是任意实数,但概率很显然只能是 0~1 之间的数。
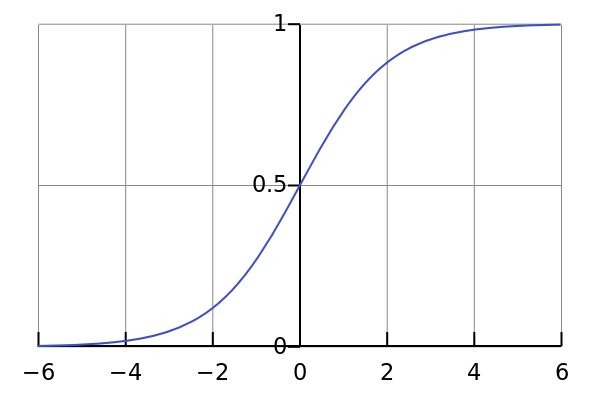
上图中的函数名叫 sigmoid 函数,它的特点是对任意输入,输出都在 0~1 之间。因此,可以将前面式子中线性回归的输出在传入 sigmoid 函数,得到最终的输出。
sigmoid 函数的定义为:
$$ S(z)=\frac{1}{1+e^{-z}} $$
因此整个模型的定义如下:
$$ P(x)=\frac{1}{1+e^{-(wx+b)}} $$
上面就是逻辑回归的模型定义了。
模型求解
设正样本的 label 为 1,负样本的 label 为 0,则预测样本为 1 或 0 的概率为:
$$ P(y=1|x) = P(x) $$
$$ P(y=0|x) = 1-P(x) $$
两者结合:
$$ P(y|x) = P(x)^y(1-P(x))^{1-y} $$
对于所有样本 $(x_i, y_i)$ 可以写出似然函数:
$$ L(w,b) = \prod\limits_{i=1}^{n}(P(x^{(i)}))^{y^{(i)}}(1-P(x^{(i)}))^{1-y^{(i)}} $$
记损失函数为:
$$ J(w, b) = -lnL(w, b) $$
模型参数 $w$ 和 $b$ 的可以使用梯度下降法求解。
再谈模型定义
前面我将逻辑回归和线性回归差不多,只不过逻辑回归中拟合的是样本为正的概率。但并不能说明逻辑回归为啥叫逻辑回归。这里将揭示逻辑回归真正的由来。
一件事情的几率(odds)是该事件发生与不发生的概率的比值,如果事件发生的概率为 $p$,那么事件的几率(odds)为:
$$ odds = \frac{p}{1-p} $$
几率(odds)的对数被称为对数几率,记为:
$$ logit(p) = log \frac{p}{1-p} $$
几率(odds)的值域为 $[0, \infty]$,logit 的值域为 $[-\infty, \infty]$,当 logit 无穷小时,说明样本为正的概率为 0,当 logit 为无穷大时,说明样本为正的概率为 1。
所有逻辑回归模型定义如下:
$$ log \frac{p}{1-p} = w·x + b $$
解出 p(x) 为:
$$ p(x) = \frac{1}{1+e^{-(wx+b)}} $$
逻辑回归,是对 logit 函数进行回归,因此成为 logistics regression。
逻辑回归实践
"""
生成样本
"""
from sklearn.datasets import make_classification
from sklearn.linear_model import LinearRegression
X, y = make_classification(n_samples=10000, n_features=10, n_informative=5)"""
划分训练集和测试集
"""
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)"""
使用逻辑回归模型
"""
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression(solver='sag')
lr.fit(X_train, y_train)LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='warn',
n_jobs=None, penalty='l2', random_state=None, solver='sag',
tol=0.0001, verbose=0, warm_start=False)"""
在测试集上评估
"""
from sklearn.metrics import accuracy_score
y_pred = lr.predict(X_test)
accuracy_score(y_test, y_pred)0.8795
推荐阅读
- 李宏毅老师关于分类的课程 Classification: Logistic Regression
- Hands-on Machine Learning with Scikit-Learn, Keras, and TensorFlow 第三章和第四章