论文阅读 - Item-Based Collaborative Filtering Recommendation Algorithms
本文是我在阅读推荐系统经典论文 Item-Based Collaborative Filtering Recommendation Algorithms 时候记录的笔记。
协同过滤算法
协同过滤算法(collaborative filtering algorithm, CF)基于当前用户先前的行为(评分、购买记录等),以及与该用户相似的用户的行为,来给当前用户推荐其可能喜欢的物品(item),或者预测该用户对某物品的喜欢程度。
问题设定是有一组用户 和一组物品 ,每个用户 有一组购买、评价过的物品 。
这里的用户和物品信息可以构成 user-item 矩阵,用户对物品的交互信息,构成矩阵中的值。矩阵可以是二值的(买过 0、未买过 1),也可以是多值或连续值(用户对物品的评分)。利用这个矩阵,可以用来预测用户对其未交互过的物品的评价值或喜欢的概率,进而可以基于此为用户产生一组推荐。
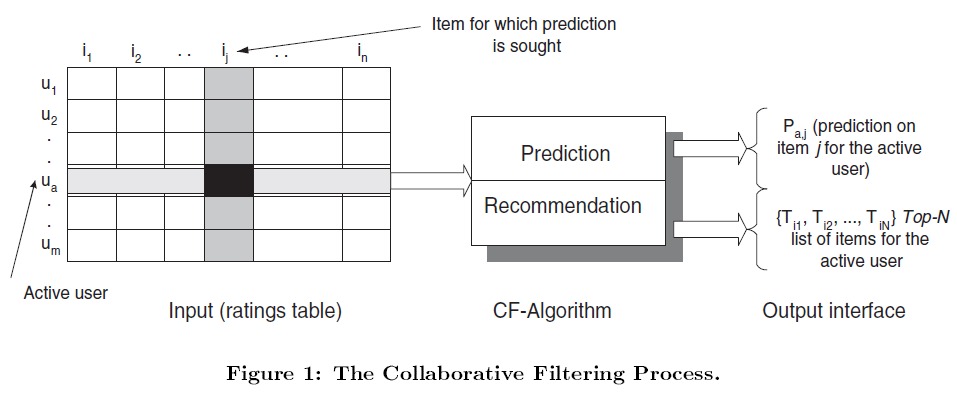
传统的协同过滤算法会从不同角度进行细分。根据是否需要保存 user-item 矩阵,可以分为 Memory-based CF 和 Model-based CF。基于计算用户相似度还是物品相似度可以分为 Item-based CF 和 User-based CF。
Memory-based CF 和 Model-based CF
协同过滤的思想,无非是找到与当前户相似的其他用户,推荐这些相似用户喜欢的物品给当前用户。或者找到与当前用户喜欢过的物品相似的物品,推荐这些相似的物品给该用户。
早期的 CF 系统,基于 User-Item 评分矩阵来计算用户或者物品之间的相似度,并依此来产生推荐。这些评分数据要放在内存中,便于计算相似度并生成推荐,因此被称为 memory-based CF。但是因为 memory-based CF 方法中计算相似度依赖于用户对物品的评分,因此容易因为评分数据量少,而无法准确地找到相似的用户或物品。
为了克服上面提到的问题,得出更好的推荐,人们提出了 model-based CF 方法。Model-based CF 是利用用户的评分数据学习出一个模型,并用此模型产生推荐。这个模型可以是一个数据挖掘或者机器学习的方法。memory-based CF 找相似用户是利用用户的向量(即前图中矩阵中的行)来找相似用户。但 model-based CF 是通过一个机器学习模型来找相似用户。保存的数据是模型的参数。
User-based CF 和 Item-based CF
基于用户的协同过滤算法(User-based CF),从用户的兴趣相似出发,给用户推荐与其兴趣相似的其他用户喜欢的物品。基本假设是:如果用户 X 和用户 Y 对 n 个物品有相似的评价(喜欢或不喜欢、评高分或评低分),那么说明他们具有相似的品味,在未来他们对另一个物品可能依然有相似的评价。因此 User-based CF 的核心是寻找相似用户。
基于物品的协同过滤算法(Item-based CF),给用户推荐那些和他们之前喜欢的物品相似的物品。基本假设是用户的偏好不会剧烈改变,过去喜欢的类型,将来还会喜欢。因此,基于物品的协同过滤,采用的方法是找出与用户曾经喜欢的物品相似的其他物品,而后将这些物品推荐给该用户。
协同过滤算法面临的挑战
1. 数据稀疏
许多商业的推荐系统,因为涉及的用户和物品的数量非常庞大,而用户和物品的交互信息(比如购买、评分等)往往很少,这导致 user-item 矩阵非常稀疏,因为缺乏足够额数据,导致难以找到相似的用户和物品。因为没有足够多相似的行为,所以相似的用户不容易被找出。
当新用户加入系统时,由于该用户尚未消费记录,无法给他任何有效的推荐。当新物品加入系统时,因为尚未有人消费过它,它也因此不会被推荐给任何人。这类问题,被称为冷启动问题。
数据稀疏还会导致能够得到推荐的物品的比例(即覆盖率)很低。覆盖率指推荐系统可能会推荐的物品在整个物品中的占比。
为了解决数据稀疏性问题,人们提出了不少方法。降维技术,如奇异值分解(Singular Value Decomposition, SVD),移除了不具代表性和不重要的用户和物品来降低 user-item 矩阵大小。信息检索中用到的隐含语义指数(Latent Semantic Indexing, LSI)就用到了 SVD。相似的用户,通过降维后的矩阵来寻找。但是当某些用户和物品的信息经过降维后消失了,这样针对他们的推荐效果也会变差。
2. 可扩展性
随着用户和物品的数据急剧增加,传统的 CF 方法显得有些力不从心了,消耗的计算资源在实践上变得难以接受。在还有几百万乃至千万用户的系统中,即使是 O(n) 的复杂度都已经很大了。而且一些系统还要做到实时地根据用户最新行为作出响应。
Item-based CF
基于物品的协同过滤算法(Item-based CF),给用户推荐那些和他们之前喜欢的物品相似的物品。这种算法的前提是用户会喜欢与他以前购买过的物品相似类型的物品。比如电影推荐场景下,用户喜欢看《复仇者联盟》,那么他就很可能喜欢看《美国队长》。但是在应用商店的场景下,用户已经安装了高德地图后,他就鲜有可能会再安装其他地图软件。因此 User-based CF 和 Item-based CF 都要根据具体场景来决定是否适用。
物品相似度计算
Item-based CF 需要寻找与用户喜欢的物品相似的其他物品。两个物品的相似度可以从多个角度来考虑,对电影而言,电影的主题、演员阵容、类型都可以是相似的依据。但是在协同过滤里面,相似并不会考虑物品的具体属性,而是从 user-item 矩阵出发的。这是协同过滤的优势所在,它发掘出的相似关系,往往优于直接从物品的属性出发,因为它依靠的是群体的智慧。
这里物品相似度计算的基本思想是,如果两个物品同时被 N 个人评分过。而且这 N 个人对两个物品的评价(比如评分)都完全相同。这说明这用户们对两个物品的评价是一样的(要么两个物品都喜欢,要么都不喜欢)。对于这 N 个人而言,他们对这两个物品有相同的评价,评价有好有坏。这说明这两个物品在很多人眼里,有相同的地位(有相似性)。考虑如果很多人都认为两个物品很相似,那么这两个物品往往就真的很相似。这里的相似,是用户的感觉,这种相似也正是算法想要的。
用户觉得《复仇者联盟》和《美国队长》相似,但是从这两电影的属性出发,很难衡量两者的相似度。但观众对这两部电影的评价,会说明这两部电影有很大的相似性。因为很多漫威迷们看过这两部电影,而且都给出了差不多的评价。

那么对于优秀的电影,比如《阿甘正传》和《泰坦尼克号》,这两部电影的评分都很高,几乎看过的人都给 5 颗星,那么这两部电影是不是就非常相似了呢?它们的相似性是大家都认为它们是好电影。但从属性上看,他们没有很大相似度。
下面列出了基于 user-item 矩阵计算相似度的几种方法。
1. 基于向量的余弦相似度(Vector Cosine-Based Similarity)
两个向量的夹角越小,说明其方法越相似,夹角越小,其余弦值就越大。在矩阵中,每个 item 都对应一个向量,这个向量是所有用户对该 item 的评分。
要计算两个 item 间的相似度,采用如下计算公式:
其中 和 是两个 item 对应的向量。
2. 改进的余弦相似度
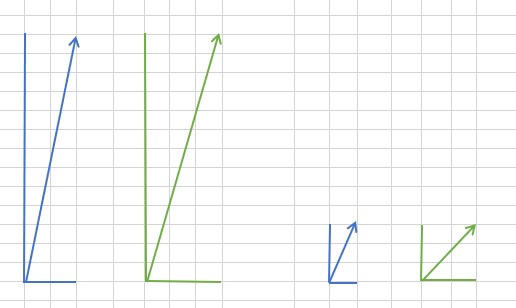
使用基本的余弦相似度存在一个缺点,没有将用户的打分尺度考虑进去。比如有的用户的打分范围在 1~5 之间,而有的用户在 2~4 之间(即不太愿意给最高分和最低分)。比如,有两个用户对两个 item 的打过分, item 的向量分别为 (10, 2),(10, 3)。但 user1 习惯打高分,他认为最差的 item 也能得到 6 分,而 user2 较严格,4 分在他看来已经是很棒的电影了。
从下图中可以看出,在计算两个向量的夹角的时候,由于一个方向的值较大,两个向量的夹角很小,user2 的评分作用被大大削弱,结果算出来的相似度会很高。
为了让要求严格、打分低的用户的数据也能起到作用,而不是被其他习惯于打高分的用户的数据盖掉,从评分中减掉平均值。可以看到,图中右边的两个向量,角度差异变大了,即不那么相似了。
计算 item i 和 item j 的相似度时,减去了各个用户的评分均值,这就消除了不同用户评分标准不同的问题:
3. Correlation-Based Similarity
这里采用 Pearson correlation 来计算两个 item 的相似度:
其中 是所有同时评价过的 item i 和 item j 的用户的集合。 是 user u 对 item i 的评价。而 是所有用户对 item i 的平均评价。
其中 U 是对两个物品同时进行过评分的用户的集合。
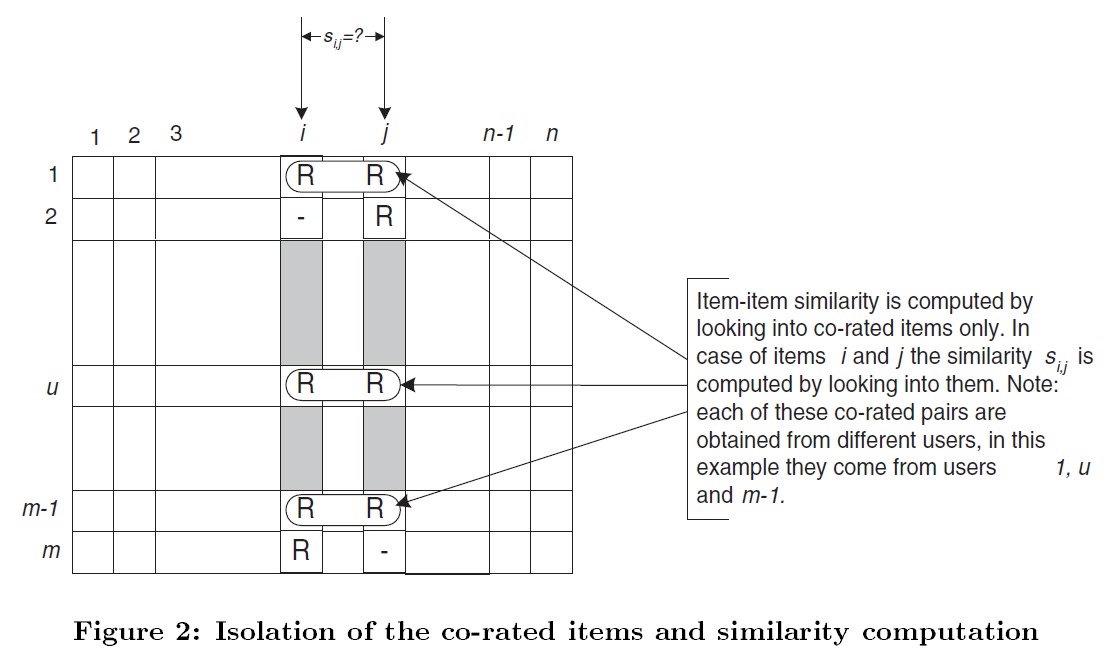
如上图中所示,计算 item i 和 item j 的相似度,采用的是虚线框中的数据,因为只有这些数据被某个用户共同评分过。
如果是计算 user 的相似度,那么减去的就是用户评分的平均值。这是为了考虑到不同用户评分时候的严格程度是不同的。如下图:
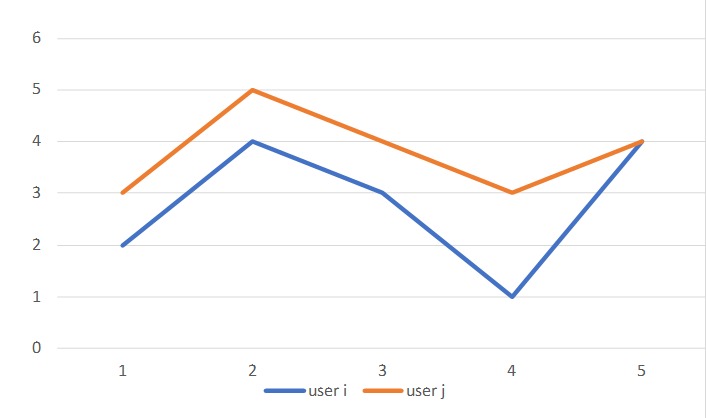
两个用户虽然给不同的电影评分都不同,但他们两者的趋势是一致的。
而计算 item 间相似度时,这里减去 item 的评分均值,是为了突出不同用户的评分差异。比如用户对这两部电影的评分为 10 和 9 (满分10分),看上去这用户对这部电影的评价都很高。但是如果该电影的平均评分为 9.5 分,那么这两个用户评分的差异就很大了。
推荐结果的计算
知道了如何计算 item 间的相似度,面对的其他问题是,计算那个 item 与其他 item 的响度,找到了相似 item 之后如何产生推荐结果。
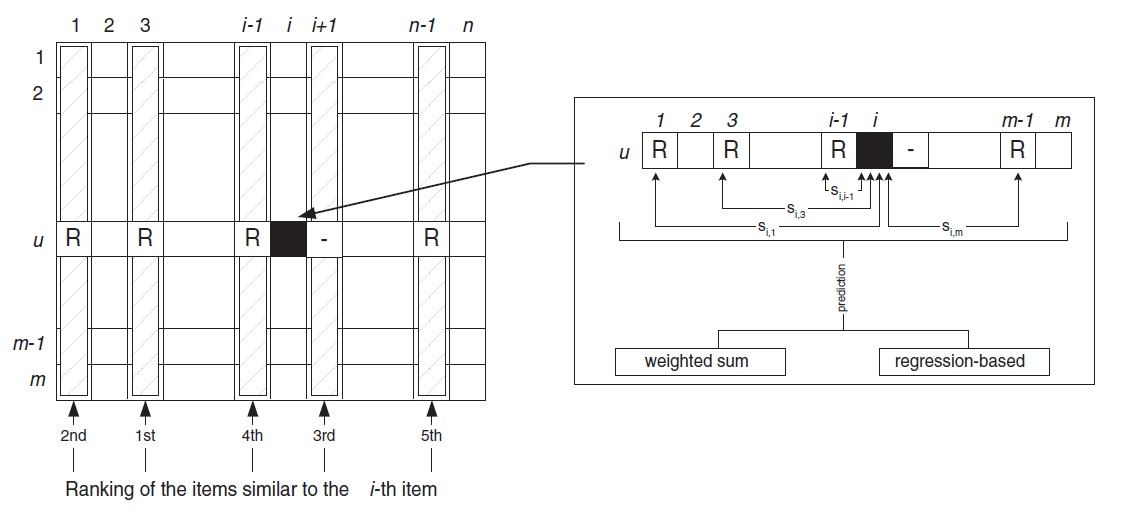
对于用户未评分过的 item i,即图中标黑色的 item,首先找出与 item i 最相似的 k 个 item(这个可以提前计算好)。然后从这 K 个 item 中找出用户评分过的物品,即图中标 R 的 item.
1. 加权和
为了生成推荐,需要找出一组他没有评价过的 item,预测出他对这些 item 的评分,然后取预测评分最高的 item 作为推荐。
用户评价过的 item 与 item i 之间存在一个相似度,计算 item i 的评分的方法是,用用户的对 item N 的评价与 item i 和 item N 之间的相似度做加权求和。
下面的式子中,N 为与 item i 相似的且用户评价过的 item,其评分为 。
分母上进行了归一化,保证计算出的评分在合适的区间内。
2. Regression
前面的方法是使用评分和相似度来加权求出对未评分物品的评分。直接使用用户 u 的评分 显得有些草率, Regression 的想法是构造两个 item 的评分之间的关系。
训练一个回归模型,让 item N 的评分,可以通过 item i 的评分计算出来。
说实在的,回归这块我没有看明白,不知道我理解的对不对
这里提到的推荐策略,是对每个 item i 找到相似 item,然后再找出用户评价过的 item,然后给每个 item 估计一个评分。在实际推荐的时候,显然可以从用户已经评分过的 item 出发。
系统性能
Item 相对 User 而言更加稳定,User 可能在一天内就会产生很多与 item 的交互行为,这会大大影响 User 的相似度计算,而 Item 则没有这个问题。因此 Item 的相似度可以预先离线计算好,然后使用很长一段时间。而 User 的相似度则需要更加频繁地离线计算,或者实时计算。
计算 item 的相似 item 需要的时间复杂度为 ,然后给每个 item 保留最相似的 K 个 item。
总结
本文讲述了经典的基于物品的协同过滤算法的基本过程,这是我学习推荐系统时阅读的第一篇论文。第一次阅读是 2018 年 5 月份,那时候很多地方理解的不到位,今天重新读了一遍,并将当时以及之后记录的笔记进行了整理。
本文对 item-based CF 的推荐结果具体产生过程描述的不是特别清楚,应该在补充阅读 2003 年亚马逊发布的那篇论文 - Item-to-Item Collaborative Filtering。