MIT 6.828 - Lab - Networking
课程主页:https://pdos.csail.mit.edu/6.828/2023/index.html
本次的实验是实现网卡的驱动程序,完成数据的发送和接收。大部分程序都已经写好了,只需要补全 transmit 和 send 两个函数即可。通过本次实验可以了解到网卡是如何将数据从内存发送出去,以及数据是如何从网卡接收到内存中的,能够对 DMA 有大致的了解。
本次实验中使用的是 E1000 网卡,在实验开始之前需要大致了解它是如何工作的,可以看 Intel E1000 Software Developer's Manual 了解其原理,但一上来就看这个容易把人弄糊涂,如果对硬件不熟悉,很难看明白。我结合源码和文档,大致了解了一些工作原理,但也仅仅够我完成本次实验。
E1000
在内存中有两个环形队列,分别是发送队列和接收队列,队列中均存放的是发送和接收的描述信息,操作系统会通过网卡提供的结构(寄存器)将这两个队列的地址和长度等信息告诉网卡。
接收队列:
+------------+------------+------------+------------+------------+------------+
| Descriptor | Descriptor | Descriptor | Descriptor | Descriptor | Descriptor |
+------------+------------+------------+------------+------------+------------+
发送队列:
+------------+------------+------------+------------+------------+------------+
| Descriptor | Descriptor | Descriptor | Descriptor | Descriptor | Descriptor |
+------------+------------+------------+------------+------------+------------+发送流程:
在未发送任何数据时,队列是空的:
+---+---+---+---+---+---+---+---+---+---+
| | | | | | | | | | |
+---+---+---+---+---+---+---+---+---+---+
^
TDH (Transmit Descriptor Head register )
TDT (Transmit Descriptor Tail register)网卡在内存中映射了两个寄存器,TDH 和 TDT 指向待发送的范围。要想发送数据,就在队列中加入待发送数据的描述信息:
+---+---+---+---+---+---+---+---+---+---+
|///|///|///|///| | | | | | |
+---+---+---+---+---+---+---+---+---+---+
^ ^
TDH TDT之后再更新 TDT,将其指向最后一个待发送的描述符的尾部,如此网卡就知道有数据可以发送了,就会根据描述信息读取数据执行发送。
因此想要发送数据,只需要读取出 TDT 的值,并往队列中这个位置写入待发送信息,比如将待发送数据设置到 tx_desc->addr 上,将数据长度设置到 tx_desc->length 上,以及根据需要设置其他各字段即可。之后然后更新 TDT 的值,此时网卡就知道有数据需要发送了。
如果像下面这种情况,数据写满了怎么办呢?
+---+---+---+---+---+---+---+---+---+---+
|///|///|///|///|///|///|///|///|///|///|
+---+---+---+---+---+---+---+---+---+---+
^
TDH
TDT这就要看看发送描述信息的具体构成了:

上图中的结构,写成 C 结构体如下:
struct tx_desc {
uint64 addr;
uint16 length;
uint8 cso;
uint8 cmd;
uint8 status;
uint8 css;
uint16 special;
};其中 status 中可以携带多个信息:
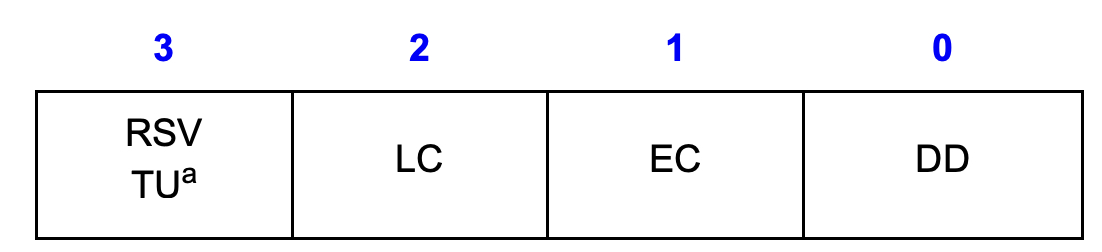
其中 DD (Descriptor Done) 表示当前 Descriptor 是否发送完成,因此可以基于这个字段判断 TDT 指向的 Descriptor 是否已经发送出去。
接收流程:
相似地,内存中也有一个接收队列,在没有接收到任何数据时,队列中整个范围都可以存放数据:
+---+---+---+---+---+---+---+---+---+---+
| | | | | | | | | | |
+---+---+---+---+---+---+---+---+---+---+
^ ^
RDH RDT
RDH: Receive Descriptor Head register
RDT: Receive Descriptor Tail register当收到部分数据后,RDH 后向后移动:
+---+---+---+---+---+---+---+---+---+---+
|///|///|///| | | | | | | |
+---+---+---+---+---+---+---+---+---+---+
^ ^
RDH RDT因此,最早被接收到的数据放在存放在 queue[(RDT + 1) % RING_SIZE] 处。接收队列中的描述信息格式如下:

也可以通过 status 字段判断这个 descriptor 是空的还是已经有接收到的数据。
实现
本次实验代码中,已经 tx_ring 和 rx_ring 两个队列,用来存放待发送和待接收的信息。因为数据都是通过 mbuf 来存储的,而要发送和接收的数据并是存储在 mbuf 内部的,所以提供了 tx_mbufs 和 rx_mbufs 两个数组来存放 mbuf。mbufs 和 ring 在相同位置上是对应的。
#define TX_RING_SIZE 16
static struct tx_desc tx_ring[TX_RING_SIZE] __attribute__((aligned(16)));
static struct mbuf *tx_mbufs[TX_RING_SIZE];
#define RX_RING_SIZE 16
static struct rx_desc rx_ring[RX_RING_SIZE] __attribute__((aligned(16)));
static struct mbuf *rx_mbufs[RX_RING_SIZE];为了应对并发读写的场景,需要对发送和接收队列加锁:
struct spinlock e1000_transmit_lock;
struct spinlock e1000_recv_lock;并且在 e1000_init 中对锁做初始化:
initlock(&e1000_transmit_lock, "e1000_transmit");
initlock(&e1000_recv_lock, "e1000_recv_lock");下面看发送数据的实现:
int
e1000_transmit(struct mbuf *m)
{
//
// Your code here.
//
// the mbuf contains an ethernet frame; program it into
// the TX descriptor ring so that the e1000 sends it. Stash
// a pointer so that it can be freed after sending.
//
/**
* +---+---+---+---+---+---+---+---+---+---+
* | |///|///|///| | | | | | |
* +---+---+---+---+---+---+---+---+---+---+
* ^ ^
* TDH TDT
*
* TDT: This is the location where software writes the first new descriptor
*/
acquire(&e1000_transmit_lock);
int tx_index = regs[E1000_TDT]; // 下一个待发送数据包存放的位置
if (tx_ring[tx_index].status & E1000_TXD_STAT_DD) { // 已经被发送了
if (tx_mbufs[tx_index]) { // 这里通过下标得到已经发送的 mbuf 并释放,因为初始化的时候 tx_mbufs 中
mbuffree(tx_mbufs[tx_index]); // 元素被初始化为 0,因此这里需要判断一下
}
tx_mbufs[tx_index] = m; // 存放新的 buf
tx_ring[tx_index].addr = (uint64)m->head; // 将地址指向待发送数据
tx_ring[tx_index].length = m->len; // 设置待发送数据的长度
// 下面一行设置成 cmd 字段,可以看看前面给出的 E1000 的文档 3.3.3.1 节
tx_ring[tx_index].cmd |= E1000_TXD_CMD_RS | E1000_TXD_CMD_EOP;
tx_ring[tx_index].status = 0; // 清空 status 字段
// 更新 TDT
regs[E1000_TDT] = (tx_index + 1) % TX_RING_SIZE;
}
release(&e1000_transmit_lock);
return 0;
}这里上层应用是生产者,网卡是消费者,有新的数据包待发送时,就将其放置在 TDT 位置,然后向后移动 TDT,这里是在生产数据。
下面是接收数据的实现:
static void
e1000_recv(void)
{
//
// Your code here.
//
// Check for packets that have arrived from the e1000
// Create and deliver an mbuf for each packet (using net_rx()).
//
/**
* +---+---+---+---+---+---+---+---+---+---+
* |///| | | | | | | | | |
* +---+---+---+---+---+---+---+---+---+---+
* ^ ^
* RDH RDT
*
* RDT: the last location where hardware can store received data.
*/
acquire(&e1000_recv_lock);
int next = (regs[E1000_RDT] + 1) % TX_RING_SIZE; // 第一个已经接收完成的数据包
while (rx_ring[next].status & E1000_RXD_STAT_DD) { // 判断是否真的已经接收完成
struct mbuf *mbuf = rx_mbufs[next]; // 拿出接收完成的数据包
mbuf->len = rx_ring[next].length;
rx_mbufs[next] = mbufalloc(0); // 新创建一个接收缓冲区,并放入队列
rx_ring[next].addr = (uint64)rx_mbufs[next]->head;
rx_ring[next].length = sizeof(rx_mbufs[next]->buf);
rx_ring[next].status = 0;
net_rx(mbuf); // 将接收到的数据交给网络协议栈
regs[E1000_RDT] = next; // 更新 RDT, 告知 E1000 可以在此处存放接收到的新数据包
next = (regs[E1000_RDT] + 1) % TX_RING_SIZE; // 尝试读取下一个数据包
}
release(&e1000_recv_lock);
}这里上层应用是消费者,网卡是生产者,RDH 和 RDT 指定的范围是可以存放接收到的数据包的地方,每接收一个 RDH 就会往后移动,当 RDH 和 RDT 重合的时候,接收缓冲区就满了。而最早被接收到但尚未被上层读取的数据包就在 RDT 后面。当 e1000_recv 从队列中拿走一个数据包之后,需要更新 RDT,以扩大可存放新数据包的范围。这里增加 RDT 是在消费数据。
另外在 e1000_recv 中需要尝试读取多个数据包,而不是一次仅读取一个,这是因为即使网卡接收到多个数据包,但也只会触发一次中断。在 e1000_init 有如下配置:
regs[E1000_RDTR] = 0; // interrupt after every received packet (no timer)
regs[E1000_RADV] = 0; // interrupt after every packet (no timer)RDTR (Receive Interrupt Delay Timer / Packet Timer) 见 3.2.7.1.1 节,是说接收到数据包后,需要等待一段时间再触发中断,这可以将多个数据包汇聚起来,避免多次触发中断。RADV(Receive Interrupt Absolute Delay Timer) 见 3.2.7.1.2 节,也是相似的功能。RDTR 和 RADV 都是为了避免短时间内大量数据包到达后频繁触发中断。我看文档中有如下描述:
Setting the Packet Timer to 0b disables both the Packet Timer and the Absolute Timer (described below) and causes the Receive Timer Interrupt to be generated whenever a new packet has been stored in memory.
但我发现还是需要在 e1000_recv 中多次执行读取才行。这里我猜应该是多个 descriptor 构成一个 packet,因此一个 packet 需要读取多次。
在上面两个函数的实现中,我使用了自己定义的自旋锁,而没有使用现成的 e1000_lock。这是因为在 e1000_recv 中 net_rx 中可能会执行发送操作,这样就会调用 e1000_transmit 会引发死锁。