MIT 6.828 - File system
本文为学习 MIT 6.828 - 文件系统章节时记录的笔记。
课程主页:https://pdos.csail.mit.edu/6.828/2023/index.html
文件系统
整个文件系统提供了 7 层抽象:
+--------------------+
| file descriptor | 将文件、socket、pipe 等资源抽象为文件,可以使用文件系统接口(open/read/write)来访问
+--------------------+
| path name | 提供层级目录
+--------------------+
| directory | 将文件目录抽象为特殊的文件,其内容是目录中的包含的文件
+--------------------+
| inode | 文件的内部表示
+--------------------+
| logging | 将对文件的操作封装为事务
+--------------------+
| buffer cache | 缓存磁盘上的块,支持对磁盘上数据的同步访问
+--------------------+
| disk | 读写数据块
+--------------------+磁盘结构
磁盘上的数据按如下结构保存:
[ boot block | super block | log | inode blocks | free bit map | data blocks ]
boot block - 用于保存启动引导代码
super block - 保存文件系统的元信息
log - 保存日志
inode blocks - 存 inode
free bit map - 用于记录数据块是否空闲,便于快速分配空闲块
data blocks - 保存数据的块超级块的作用是记录各个块的位置和大小,超级块固定存放在第一个块上,通过超级块可以找到其他块,下面是超级块的定义:
struct superblock {
uint magic; // Must be FSMAGIC
uint size; // Size of file system image (blocks)
uint nblocks; // Number of data blocks
uint ninodes; // Number of inodes.
uint nlog; // Number of log blocks
uint logstart; // Block number of first log block
uint inodestart; // Block number of first inode block
uint bmapstart; // Block number of first free map block
};buffer cache
读写磁盘是比较慢的,为了加速读写,在内存中维护了一个缓存。每个缓存块,对应磁盘上的一个数据块,其定义如下:
struct buf {
int valid; // has data been read from disk?
int disk; // does disk "own" buf?
uint dev;
uint blockno;
struct sleeplock lock;
uint refcnt;
struct buf *prev; // LRU cache list
struct buf *next;
uchar data[BSIZE];
};缓存有很多好处,比如可以避免对同一个磁盘块的多次读取;对磁盘块的写入,可以先写入缓存,对磁盘同一位置的多次写入,可以只写最后的内容。
logging
往磁盘上写数据的时候,机器可能突然断电,这可能导致磁盘数据被破坏,为此希望对磁盘的写操作保持原子性,要么能写成功,要么写失败。为此文件系统中引入了事务,而日志则是实现事务采用的手段。引入日志后,数据写入分为 4 个步骤:
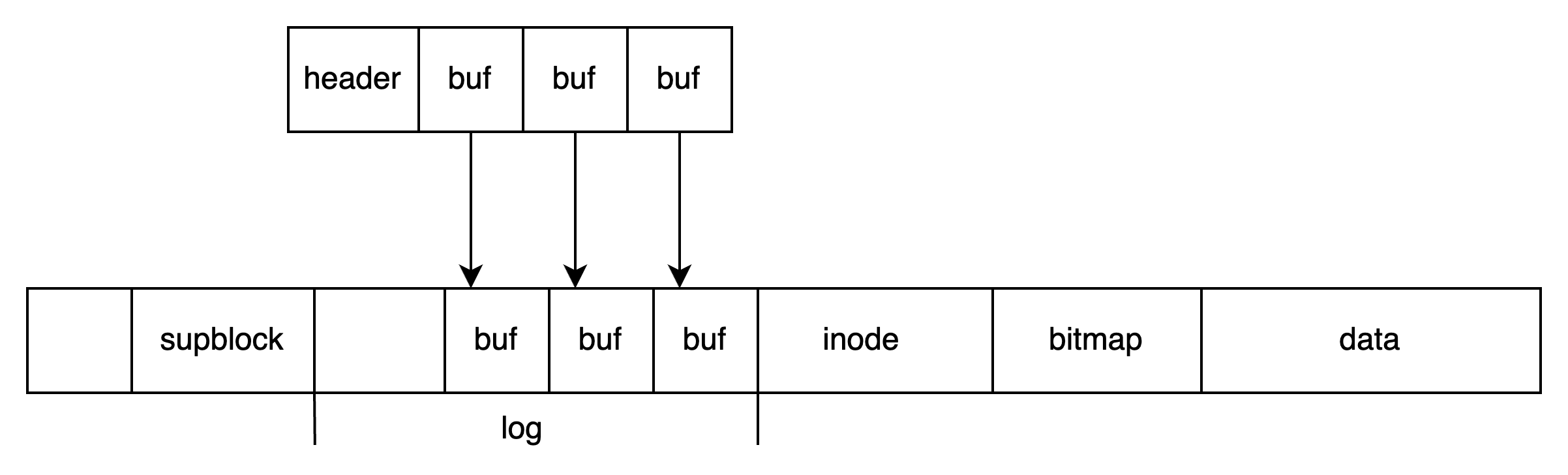
第一步:将待写入的 buf 写入 log 中
这些 buf 可能要写到 data 或者 inode 中,但先将其写入到 log 中:
第二步:写 log header
在 log header 中,描述了此前写入的 buf 真正应该写入的位置,第二步是将这些描述信息写入 log 中:
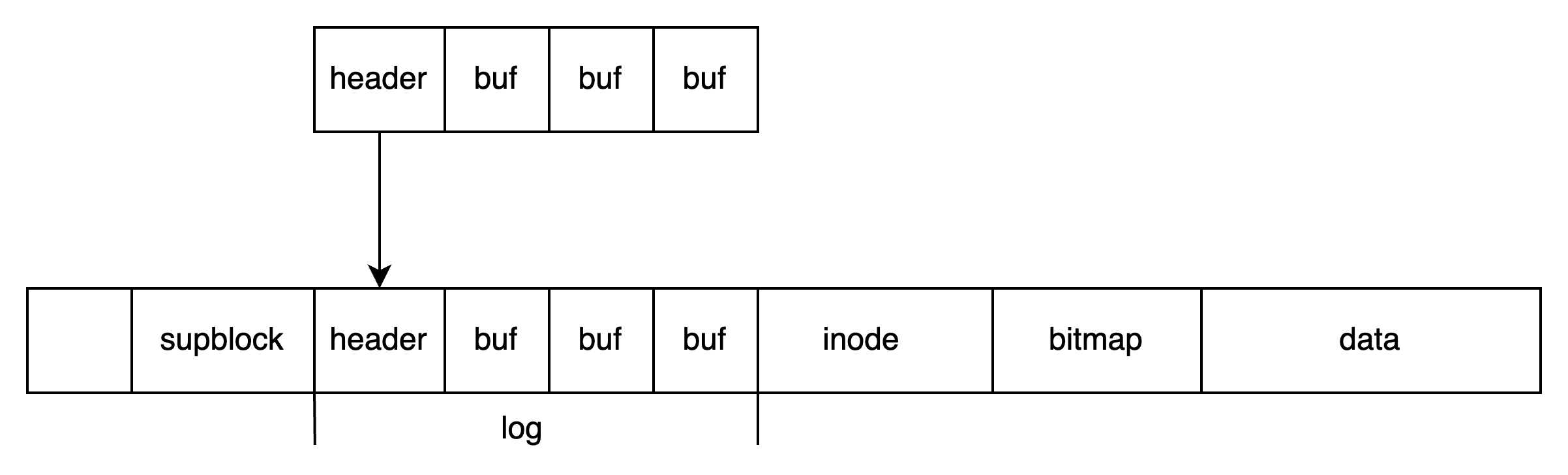
第三步:实际写数据
数据写入到 log 中之后,将数据写入实际要写入的位置:
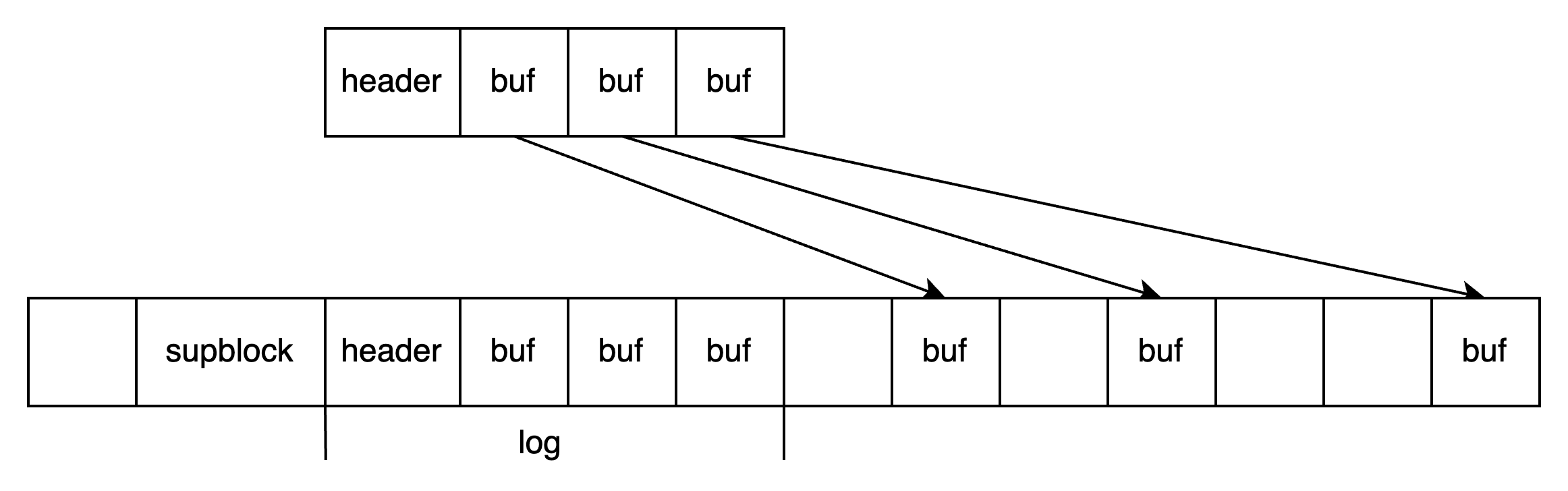
第四步:清除日志
数据写完后,清除日志,清除日志只需要删除 log header 即可:
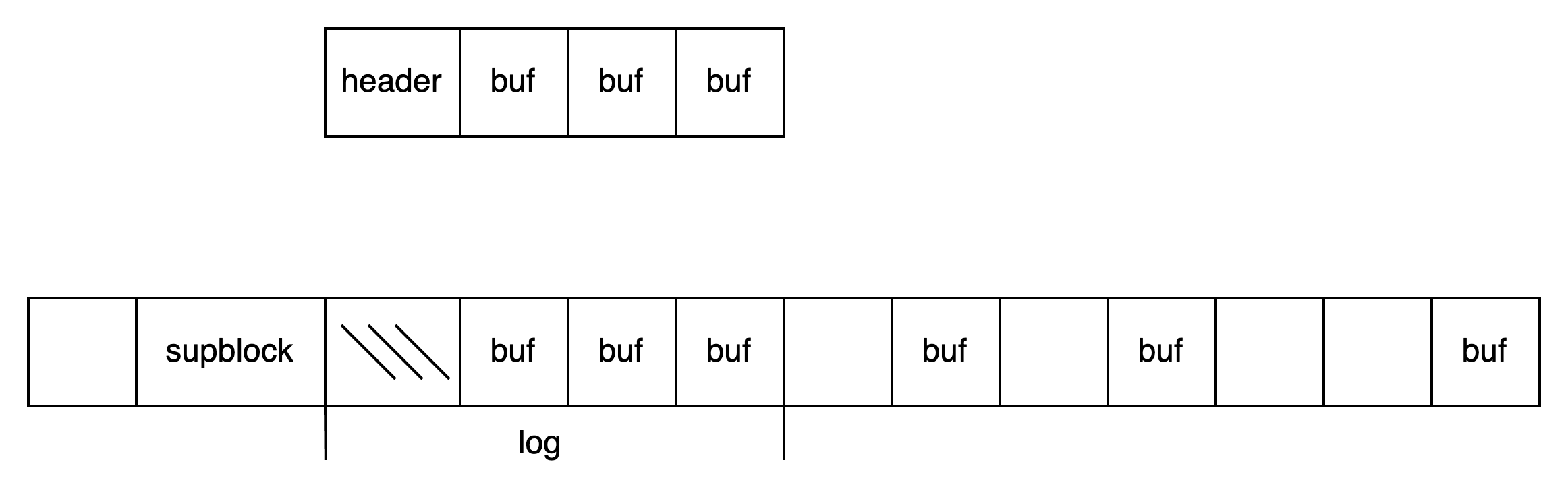
安装上面这四个步骤来写数据,就可以保证数据不会出错。下面分别描述,上述四个步骤执行时,任意时刻宕机的场景。
- 第一步:后续步骤不会执行,数据写入失败
- 第二步:数据写入失败
- 第三步:因为第一二步已经成功写入了日志,下次启动时,会根据日志的内容重新执行第三步和第四步
- 第四步:同第三步一样
引入日志后,在宕机后,可以根据日志的内容执行数据的恢复。恢复过程很简单,就是读出 log header,然后根据 log header 的描述将 log 中的数据复制到指定的位置。
log header 的结构很简单:
struct logheader {
int n;
int block[LOGSIZE];
};这里 n 表示有多少条日志,block 中则记录了每一条日志应该写入到那个 block 中。所有当系统启动后,只需要读出
logheader,并判断 n 是否为 0,如果不为 0,则读出后续的日志,并按照 block 的指示将这些日志写入对应的 block 中。
inode
inode 表示一个文件或目录,它存储在磁盘上的 inode blocks 中,每一个 block 中可以存储多个 inode。使用 inode 的编号,可以定位到某个 inode 存储在第几个 block 中,以及在该 block 中的偏移量。

下面是 inode 在磁盘上的表示:
// On-disk inode structure
struct dinode {
short type; // File type
short major; // Major device number (T_DEVICE only)
short minor; // Minor device number (T_DEVICE only)
short nlink; // Number of links to inode in file system
uint size; // Size of file (bytes)
uint addrs[NDIRECT+1]; // Data block addresses
};其中包含文件类型、设备号、文件大小、链接数,文件的内容保存在 data block 中,在 inode 中包含一个数组指向 data block,表示该 inode 的数据:
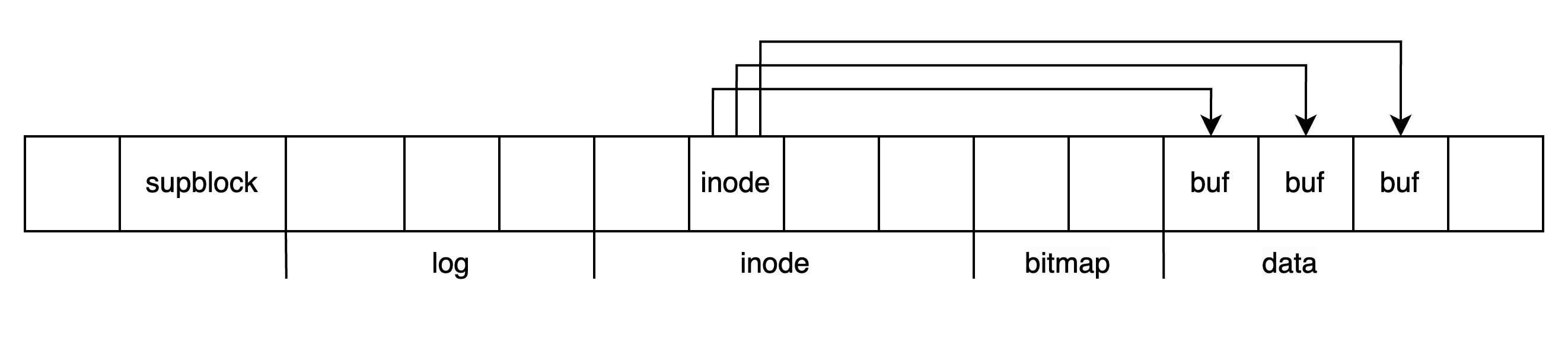
在内存中 inode 使用如下结构表示:
struct inode {
uint dev; // Device number
uint inum; // Inode number
int ref; // Reference count
struct sleeplock lock; // protects everything below here
int valid; // inode has been read from disk?
short type; // copy of disk inode
short major;
short minor;
short nlink;
uint size;
uint addrs[NDIRECT+1];
};inode 可以表示文件、目录、设备等,使用 type 字段做区分:
#define T_DIR 1 // Directory
#define T_FILE 2 // File
#define T_DEVICE 3 // Device目录
文件使用 inode 表示,但是上层应用是按照路径来查找文件的。给定一个路径 /usr/bin/grep 需要能找到 grep 这个可执行文件对应的 inode,并从磁盘读取出其内容,这是如何实现的呢?
如果 inode 对应的是文件,inode 中 addrs 中记录的 data block 则为文件的内容。如果 inode 对应的是目录,该 inode 中存储的是目录中的文件条目,这些文件条目使用如下数据结构表示:
struct dirent {
ushort inum;
char name[DIRSIZ];
};每个 inode 都有一个编号,根目录 / 对应的 inode 编号为 0,在读取文件 /usr/bin/grep 时,会先读取根目录的 inode,然后从中查找 usr 项,得到 usr 的 inode 编号,依次直到读取到 grep 文件。
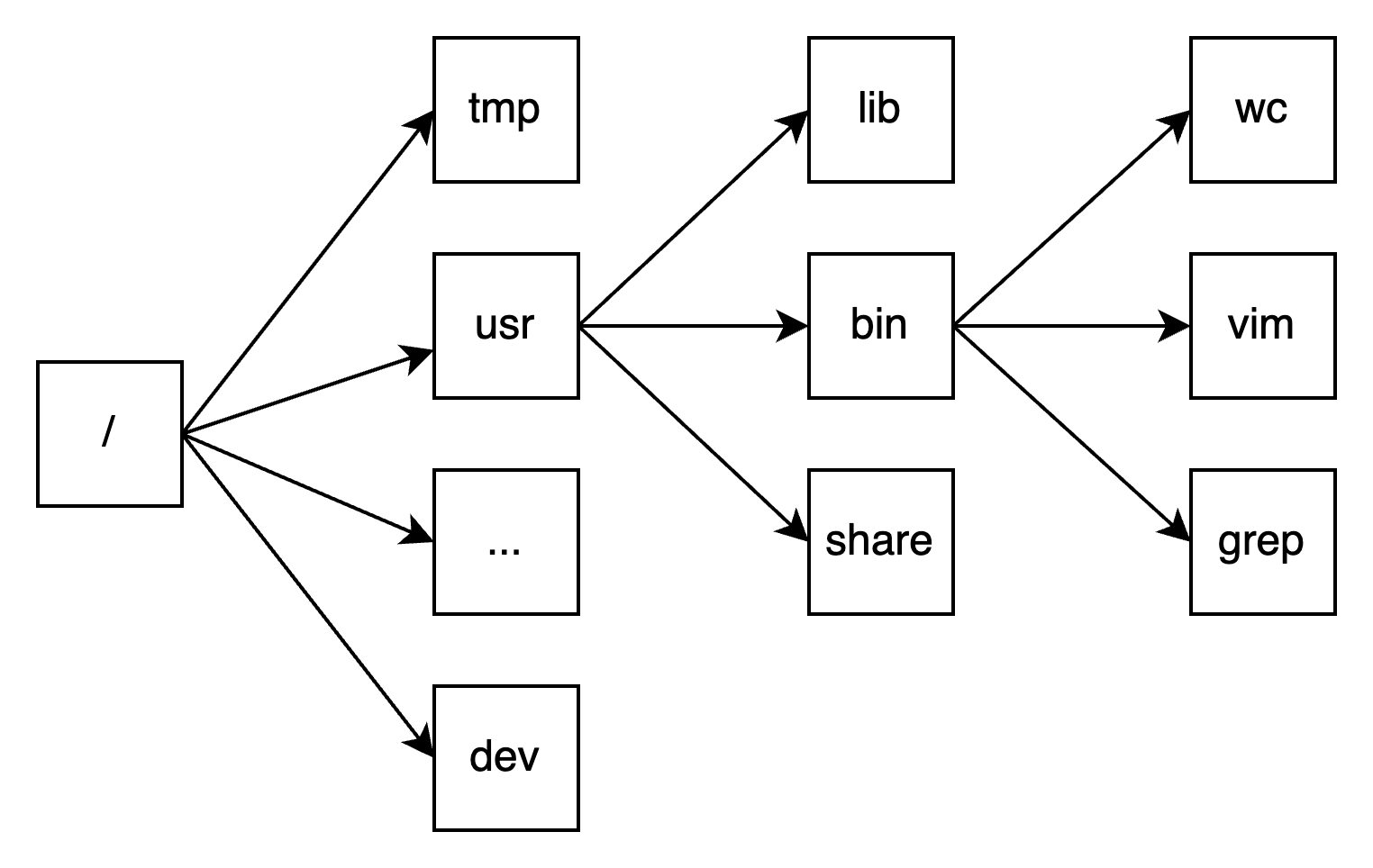
文件描述符
文件描述符为一个打开的文件、socket、pipe 等资源,可以使用 read、write、open 等来使用相同的操作处理这些资源。
在进程的结构体中有一个 ofile 字段,记录了当前进程已经打开的文件:
struct proc {
// ...
struct file *ofile[NOFILE]; // Open files
// ...
};file 的定义如下:
struct file {
enum { FD_NONE, FD_PIPE, FD_INODE, FD_DEVICE } type;
int ref; // reference count
char readable;
char writable;
struct pipe *pipe; // FD_PIPE
struct inode *ip; // FD_INODE and FD_DEVICE
uint off; // FD_INODE
short major; // FD_DEVICE
};在读写文件描述符的时候,会根据描述符查找到对应的 file 结构体,根据其类型,读写操作需要做工作是不同的。如果是文件,就是读写底层的 inode,如果是 socket 那就是操作网卡驱动来发送和接收数据。