glibc malloc 实现原理
近期我负责的组件出现故障,线上内存使用量暴增,排查问题的过程中发现想要弄清原因,需要深入了解内存分配器的实现原理。malloc 和 free 平时写 C 程序时很常用的函数,但它们是如何实现的呢,内存是如何管理的呢。我发现自己对这其中的原理还不甚清楚,经过一段时间的学习,略有一些心得,本文将对 glibc 中内存分配器的实现原理粗浅地剖析一二。
背景知识
学习操作系统时,我们了解了虚拟内存的概念,在应用程序的视角中,它看到的是虚拟地址空间,程序中使用的指针也都是虚拟地址,使用的内存块可以看做是虚拟地址空间中的一块。虚拟地址空间只是操作系统提供给应用程序的一层抽象,我们访问的虚拟地址会经过转换,最终转为物理地址,你写入的数据最终也会落在内存条中。
内存分配器工作在应用层,它和我们平时写的 C 语言代码一样,它并没有什么特权,它也是通过系统调用来和内核交互。因此不要觉得内存分配器有什么神秘之处。
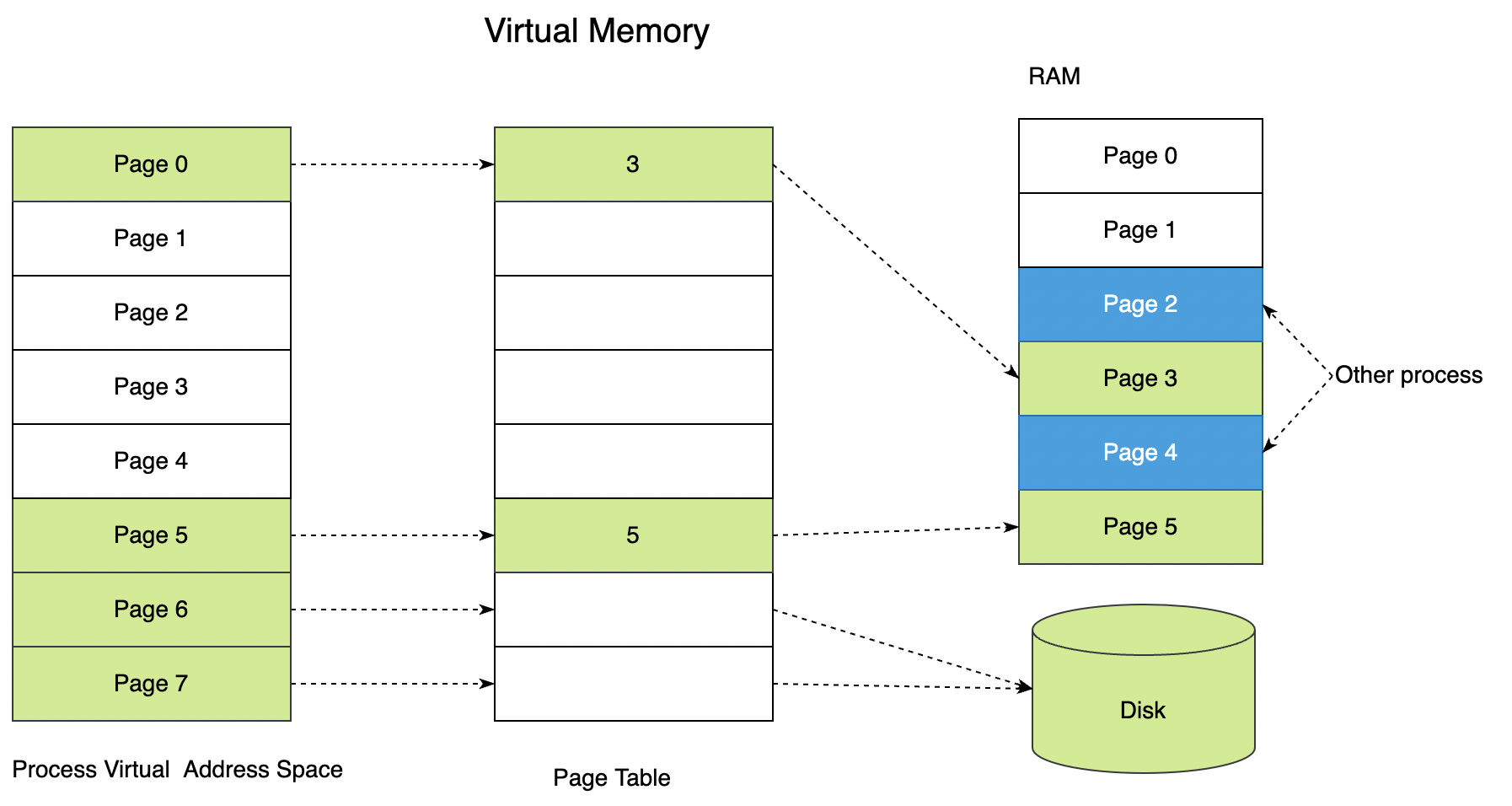
内存分配器先从操作系统哪里获取内存,然后在将这些内存分配给应用程序。那么内存分配器分配的内存来自哪里呢?下图为简化后的 Linux 进程的虚拟地址空间。其中 heap 部分就是我们熟知的堆,stack 则是程序运行时栈。
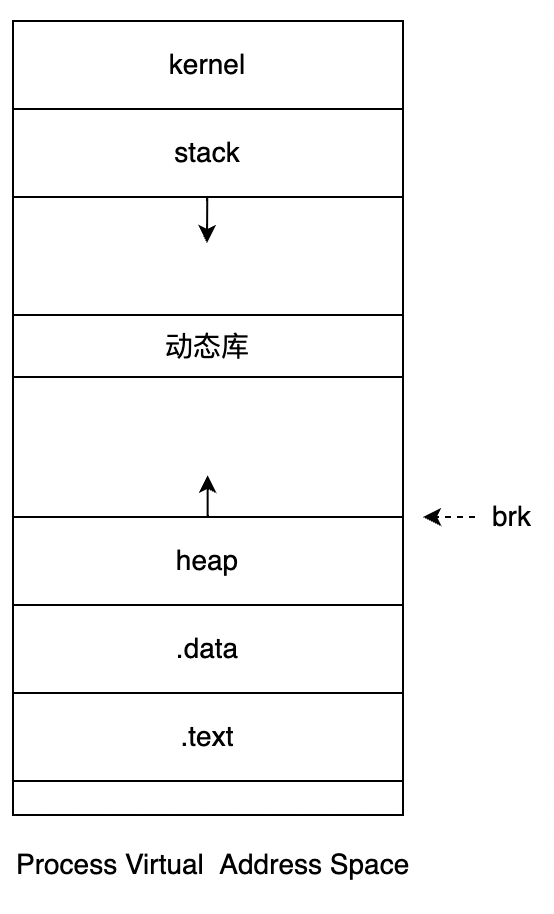
linux 内核中,使用 mm_struct 结构来描述进程的地址空间,此结构中的字段大致可以和上图对应。
struct mm_struct {
struct vm_area_struct *mmap; /* list of memory areas */
···
unsigned long start_code; /* start address of code */
unsigned long end_code; /* final address of code */
unsigned long start_data; /* start address of data */
unsigned long end_data; /* final address of data */
unsigned long start_brk; /* start address of heap */
unsigned long brk; /* final address of heap */
unsigned long start_stack; /* start address of stack */
unsigned long arg_start; /* start of arguments */
unsigned long arg_end; /* end of arguments */
unsigned long env_start; /* start of environment */
unsigned long env_end; /* end of environment */
···
};其中 start_brk 和 brk 这两个字段则划定了 heap 的范围。因此可以将 brk 增大,这样 heap 就变大了,就有多余的内存可以使用了。另外一个来源是结构体中的 mmap 字段,这里存放的是使用 mmap 内存映射的信息。使用 mmap 可以将文件、块设备映射到内存中,但也可以使用 mmap 做一个匿名映射,即不映射任何内容到内存中,如此就有了一块内存可供使用了。内存分配器向操作系统申请内存的方式就是使用 brk 来扩大 heap,或者使用 mmap 在 heap 和 stack 之间的空间中创建匿名内存映射。
可以查看下面这几个函数的功能,以了解详情。
void * brk(const void *addr);
void * sbrk(int incr);
void * mmap(void *addr, size_t len, int prot, int flags, int fd, off_t offset);ptmalloc2
ptmalloc2 是 glibc (GNU C library) 中自带的内存分配器,这是一个历史很悠久的内存分配器。它源自由 Doug Lea 实现的 dlmalloc,后来经过修改,加入了针对多线程的优化,改名为 ptmalloc2,并加入 glibc。
前面废话了很多,现在开始将 ptmalloc2 的实现原理。首先给出整体的结构图,并从宏观层面描述实现原理,后文再对细节进行描述。

arena
arena 是内存管理的主体,负责记录当前的内存分配信息,其定义如下:
struct malloc_state
{
/* Serialize access. */
__libc_lock_define (, mutex);
···
/* Fastbins */
mfastbinptr fastbinsY[NFASTBINS];
/* Base of the topmost chunk -- not otherwise kept in a bin */
mchunkptr top;
/* Normal bins packed as described above */
/* 这里之所以乘以 2,是因为一个 bin 要保存 prev 和 next 两个指针 */
mchunkptr bins[NBINS * 2 - 2]; // NBINS = 128
···
};
typedef struct malloc_state *mstate;ptmalloc2 将内存块按大小划分为 127 个 bins。每个 bin 为一个双链表,存储空闲的内存块。调用 malloc(size) 申请内存的时候,首先基于 size 计算出 bins 的下标,然后去对应的链表中拿空闲的内存块即可。
在初次申请内存时,ptmalloc2 会调整 brk 来从堆上申请内存,默认 132KB,然后从中划分出一个 chunk 返回给用户。
#define _GNU_SOURCE
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main() {
void *p1 = sbrk(0);
char *buffer = malloc(10);
void *p2 = sbrk(0);
printf("%ld\n", p2 - p1);
return 0;
}
$ ./a.out
135168其中还包含一个 TOP chunk,这个 chunk 是尚未切分完的剩余空间。用户申请内存时,如果链表中没有合适 chunk 可以提供给用户,就从 TOP chunk 中切分出一个 chunk 返回给用户。
heap info
ptmalloc2 中的 pt 是 per thread 的意思,在多线程环境下,每个线程都有一个 arena,这样每个线程申请和释放内存就可以尽可能少地互相干扰,很多操作就可以无锁地进行了。
在 ptmalloc2 中,主线程中的 arena 叫做 main_arena,它使用 brk 来申请内存。其他线程中的 arena 使用 mmap 来申请内存,mmap 返回的内存使用 heap info 结构来管理。
typedef struct _heap_info {
mstate ar_ptr; /* Arena for this heap. */
struct _heap_info *prev; /* Previous heap. */
size_t size; /* Current size in bytes. */
...
} heap_info;heap_info 管理 mmap 返回的一个内存,默认 mmap 会申请 132 KB 的空间。heap_info 这个结构放置在 mmap 返回的内存块的头部,并且对齐到 1MB。
在 heap_info 中存有 arena 的指针。不同于 main_arena 使用移动 brk 得到的内存,这里 arena 使用 mmap 得到的内存。所以 arena 中的 TOP 指向当前有内存。多个 heap_info 使用单链表串起来。
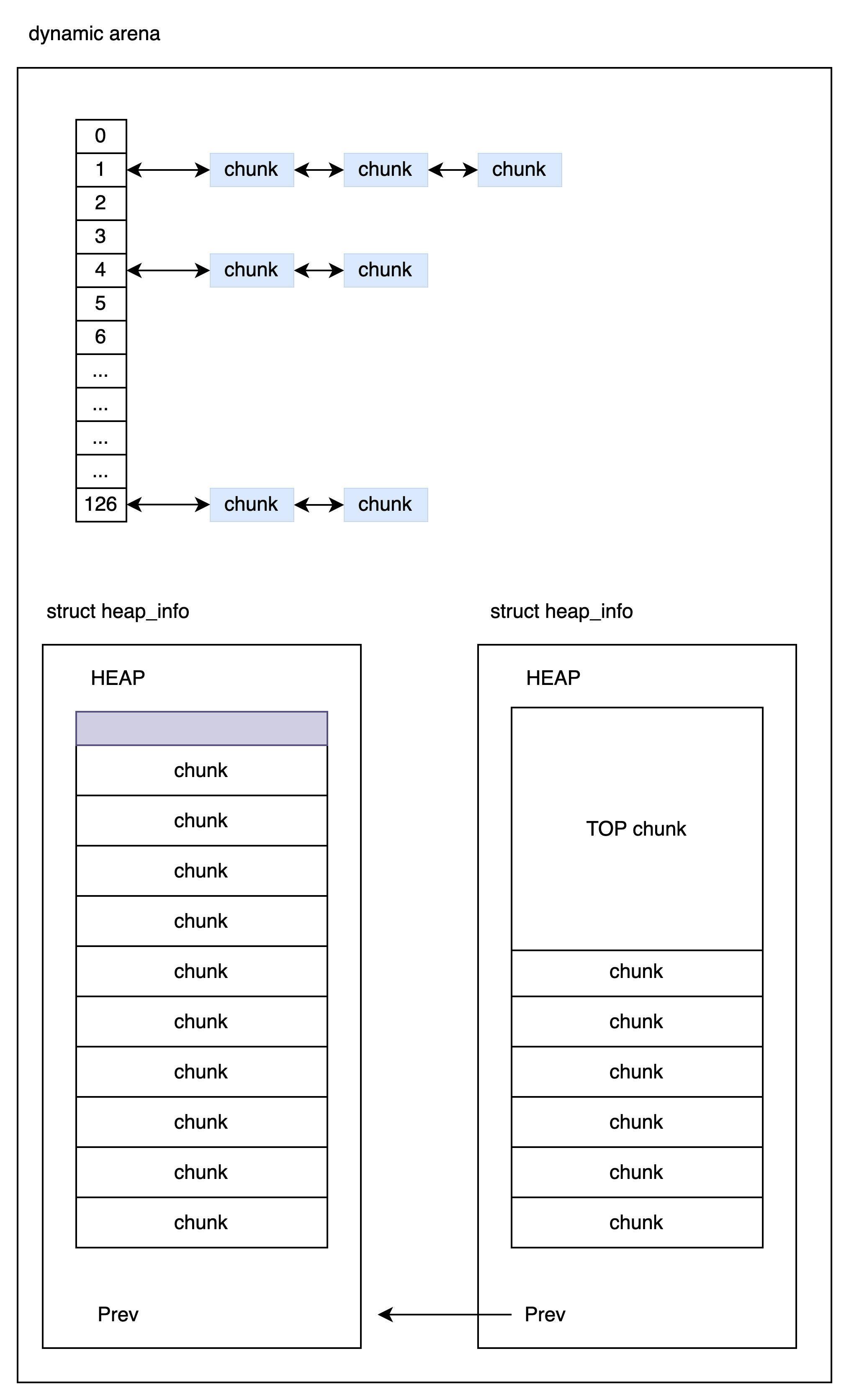
chunk
chunk 是内存分配的基本单元,用户调用 malloc 返回的内存就是一个 chunk。内存分配器需要做的就是管理、切分、合并 chunk。
chunk 是从一块较大的内存块中切分出的小内存块,因此一个个 chunk 是彼此相邻的。
用户申请 chunk 的时候,可以从大内存块中顺序地切出小 chunk。但用户释放这些 chunk 的顺序与申请的顺序可是不一致的。为了管理这些 chunk,最常规的做法就是使用链表将这些 chunk 串起来。然后将不同大小的 chunk 的链表头尾保存到 bins 中。
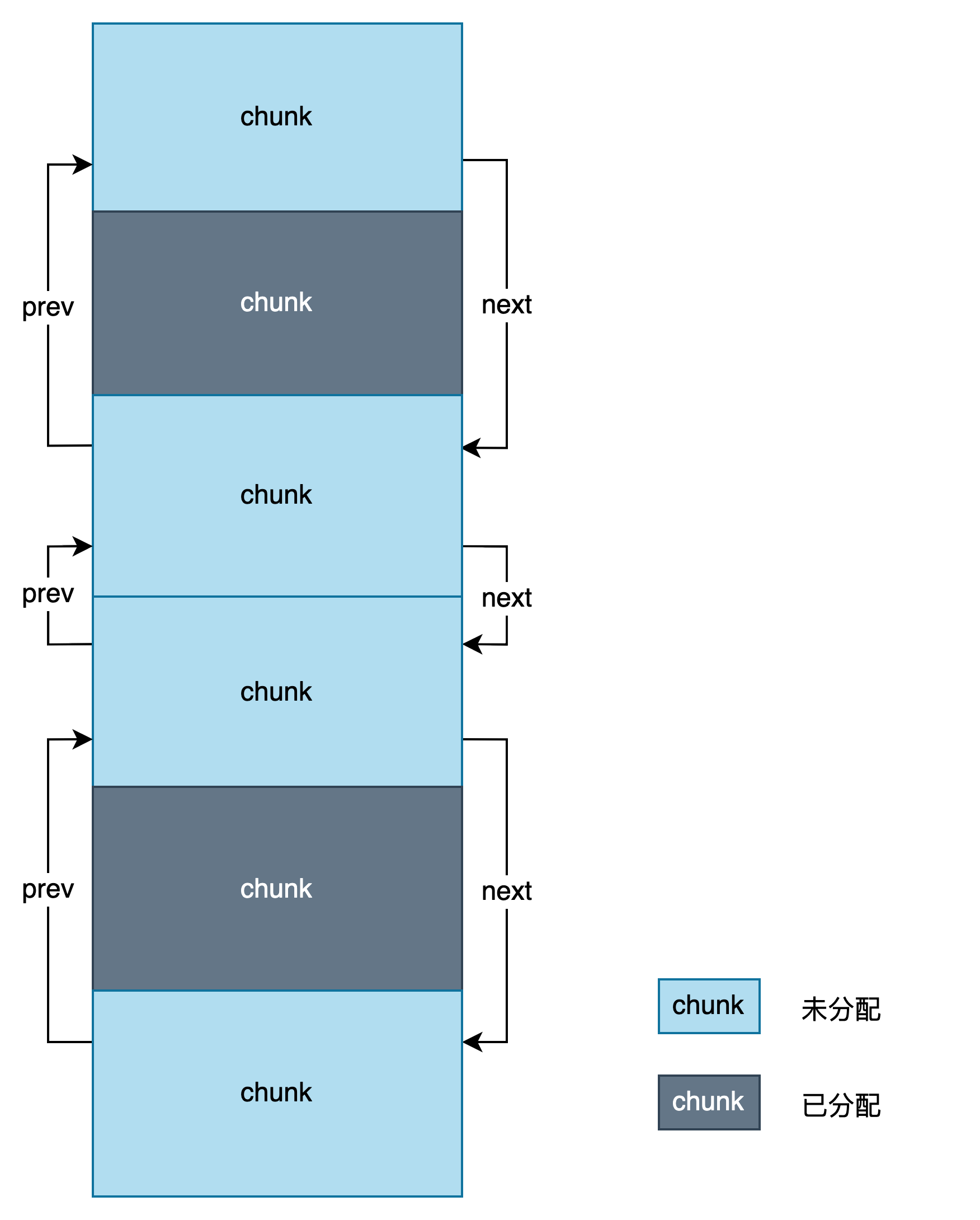
chunk 结构体定义如下:
struct malloc_chunk {
INTERNAL_SIZE_T mchunk_prev_size; /* Size of previous chunk (if free). */
INTERNAL_SIZE_T mchunk_size; /* Size in bytes, including overhead. */
struct malloc_chunk* fd; /* double links -- used only if free. */
struct malloc_chunk* bk;
/* Only used for large blocks: pointer to next larger size. */
struct malloc_chunk* fd_nextsize; /* double links -- used only if free. */
struct malloc_chunk* bk_nextsize;
};观察这个结构体,可以看出 chunk 会以双链表的方式存储,而且看上去还存在两个链表。
下面是 chunk 的内存结构:
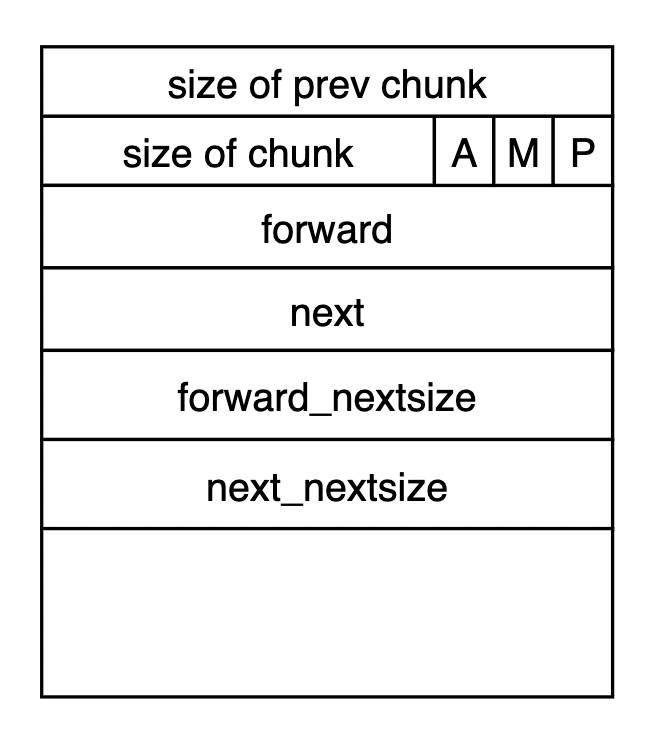
chunk 中,使用 prev size 来记录前一个 chunk 的大小,这样就可以得到前一个 chunk 的大小了,进而得到前一个 chunk 的 head 部分。另外可以使用本 chunk 的 size,得到后面的一个 chunk。这样可以很方便地实现内存上相邻的 chunk 的合并。
因为 chunk 的大小至少是按照 16 字节对齐的,因此存储 size 信息的字段 mchunk_size 中低 4 位一定是 0,既然这些 bit 没被用到,不如拿来做其他用途,上图中 AMP 三个 bin 的含义如下:
- A (NON_MAIN_ARENA): 是否在主 arena 中分配。
- M (IS_MMAPPED): 是否使用 mmap 申请。
- P (PREV_INUSE): 标记前一个 chunk 是否已经被分配,这里的前一个是指内存上相邻的前一个 chunk,而不是链表的前一个。
下图中共画了 3 个 chunk,其中前两个是已经分配出去的 chunk 最后一个尚未分配。

其中 mem 部分中存储着链表指针信息,但这些信息仅仅在这个 chunk 尚未分配时有用。当这个 chunk 分配给用户时,mem 就是返回给用户的指针。
chunk 中有实现双链表的 prev 和 next 指针,当 chunk 分配给用户后,prev 和 next 指针是没用的,而内存回收后,chunk 中 payload 部分也是不会被用到的。因此指针和 payload 实际共享同一块内存。
另外对于 nextsize 的两个指针,只有 large chunk 才会用到。所以对于最小的 chunk,必须包含的是 prev 和 next 加上 size 和 prev size 两个字段,这需要 4 个 8 字节,即 32 个字节。因此最小的 chunk 就是 32 个字节。
在分配内存时,即使只申请一个字节,也会消耗 32 个字节,我们可以使用 malloc_usable_size 来获取到真正可以使用的内存大小。
#include <stdio.h>
#include <stdlib.h>
#include <malloc.h>
int main() {
char *buf = malloc(1);
int n = malloc_usable_size(buf);
printf("%ld\n", n);
return 0;
}
$ gcc ./test_malloc.c
$ ./a.out
24从上面的例子可以看出,即使申请一个字节的内存,在 chunk 的 payload 区域也有 24 个字节可用。前面提到最小的 chunk 是 32 个字节,当 chunk 分配出去后,prev 和 next 指针的空间是可以被用户使用的,这意味着 payload 应该是 16 字节才对。这 24 字节的可用空间,岂不是越界到下一个 chunk 中了?
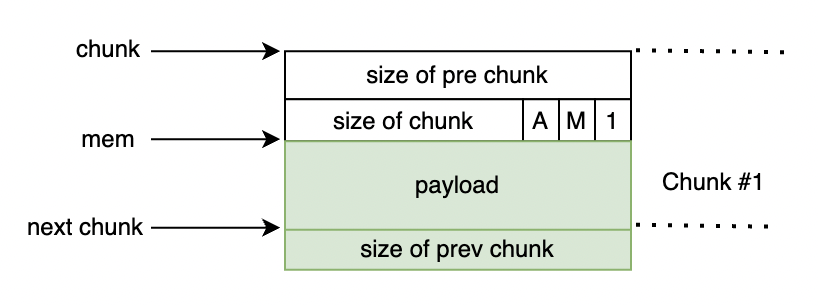
确实是这样,上图中绿色部分是用户可用的空间。因为 prev size 只会在前一个 chunk 是空闲的时候才有效。因此当 chunk 分配出去后,该 chunk 后面的 chunk 中 prev size 字段就没用了,这部分空间可以拿来使用。
bins
存放不同大小的 chunk 的空闲链表,可以使用 size 通过计算定位到对应的 bin,然后在对应的双链表中尝试获取内存。

bins 可以分为三类: small bins、large bins、unsorted bins
small bins
small bins 共有 64 个,其中存放的 chunk 都是相同大小的。
bin[2]: [32] <-> [32] <-> [32]
bin[3]: [48] <-> [48]
bin[3]: [64] <-> [64] <-> [64] <-> [64]
...
bin[65]: [1088] <-> [1088] <-> [1088]large bins
large bins 有 63 个,每个 bin 中存放的 chunk 大小不是全部相同的,一个 bin 中的 chunk 大小落在某个范围中。这些 chunk 在链表中按升序排列。因此往 large bins 中插入 chunk 不是简单地将其插入链表头部即可,而是需要遍历整个链表,将其插入合适的位置。
为了加快顺序查找的速度,对于 large chunk,在实现的时候额外加了两个指向 nextsize 的指针,实现了类似于两层 skiplist 的设计,以加快查找速度。

因为 largin bins 中的 chunk 一般不会很多,而且有类似 skiplist 的设计,顺序插入其实不会消耗太多时间。
large bins: chunks are sorted by size
bin[66]: [1152] <-> [1152+16] <-> [1152+32] <-> [1152+48]
bin[67]: [1216] <-> [1216+16] <-> [1216+32] <-> [1152+48]
...
bin[126]: [512K] <-> [512K+1K] <-> [512K+2K]unsorted bin
unsorted bin 中的 chunk 可以是任意大小的 chunk,这些 chunk 可能属于 small bins 也可能属于 largin bins。这些 chunk 在 unsorted bin 中随意地存放着。
unsorted bin: chunks in different size in unsorted order
bin[1]: [32] <-> [1024] <-> [64] <-> [4096] ... [1216]为什么需要 unsorted bin 呢?这是为了加快 free 的速度,在 free 的时候,只是把 chunk 插入到 unsorted bin 中,而不是插入到该 size 对应的 bin 中。在调用 malloc 的时候,才尝试整理 unsorted bin 中的 chunk。
fast bins
fast bins 也是一组链表,fast bins 可以看做是 bins 的缓存,chunk 回收到 bins 中,需要将其插入 bins 对应的双链表中,同时修改 chunk 的使用情况为未使用。而加入 fast bins 中时,只需要将 chunk 插入到单链表中即可,并不修改 chunk 中的标记。下次用户再次申请的时候,可以直接从 fast bins 中找到合适的返回给用户。
fast bins:
+---+---+---+---+---+---+---+---+
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
+---+---+---+---+---+---+---+---+
fastbin[0] = [32] -> [32] -> [32]
fastbin[1] = [48] -> [48]
fastbin[2] = [64] -> [64] -> [64]
fastbin[3] = [80] -> [80]
fastbin[4] = [96] -> [96] -> [96]
fastbin[5] = [112]
fastbin[6] = [128] -> [128] -> [144]
fastbin[7] = [144] -> [144]
fastbin[8] = [160]thread cache bins
无论是 fast bins 还是 bins,在访问时,都需要加锁,即使 ptmalloc 使用了多 arena 避免竞争,但加锁不可少。thread cache bins 是存在在线程局部存储空间中的一组链表,对其进行读写完全不需要加锁。
tbins: thread cache bins
+---+---+---+--------+----+----+----+
| 0 | 1 | 2 | ...... | 77 | 78 | 79 |
+---+---+---+--------+----+----+----+
tbins[0] = [32] -> [32] -> [32]
tbins[1] = [48] -> [48]
tbins[2] = [64] -> [64]
tbins[3] = [80]
tbins[4] = [96] -> [96]
tbins[5] = [112]
...
tbins[78] = [1280] -> [1280]
tbins[79] = [1296]内存分配过程
第一步:
先尝试在 thread cache bins 中寻找。
第二步:
在 fast bins 中找,如果能找到,则移动一些到 thread cache bins 中。
第三步:
在 small bins 中找,如果能找到,移动一些到 thread cache bins 中。
第四步:
如果请求是 large chunk,就将 fast bins 中的 chunk 全部回收到 unsorted bin 中,并合并空间上相邻的 chunk,并清除其正在使用的标记。
第五步:
整理 unsorted bin,遍历 unsorted bin 中的 chunk,将 chunk 放到合适的 bin 中,如果 unsorted bin 中存放的 chunk 太多,这一步可能消耗很长时间,因此,这里有个限制,最多清理 1 万个 chunk。
第六步:
使用 size 定位到大小满足该 size 的第一个 bin,以此 bin 开始遍历 bins,找到满足当前请求的最小 chunk。
如果找到的 chunk 有多余的空间,且值得切分(切分后余下的块足够大),则切分。
第七步:
如果还是没有找到,就去 TOP chunk 中切分一块。
第八步:
如果 TOP chunk 中也没有空间了,就向操作系统申请内存。
如果 size 大于 mmap 的阈值(文档中说是 128KB),则使用 mmap 申请内存。
否则扩大 TOP chunk 的内存空间,然后切分。
内存释放 free(ptr)
第一步:
通过 ptr 得到 chunk
#define mem2chunk(mem) ((mchunkptr)((char*)(mem) - CHUNK_HDR_SZ))
chunk = mem2chunk (ptr);根据前面描述的 chunk 的结构可知,将 ptr 减去固定的偏移量即可得到 chunk。
第二步:
如果 chunk 是基于 mmap 申请的(标记 M 被设置),就直接 munmap。
否则,需要得到管理该 chunk 的 arena,方法如下:
ar_ptr = arena_for_chunk (chunk);
static inline struct malloc_state *
arena_for_chunk (mchunkptr ptr) {
return chunk_main_arena (ptr) ? &main_arena : heap_for_ptr (ptr)->ar_ptr;
}
static inline heap_info *
heap_for_ptr (void *ptr) {
size_t max_size = heap_max_size ();
return PTR_ALIGN_DOWN (ptr, max_size);
}如果 chunk 中 A 标记被设置,说明其来自 main_arena,否则,则说明该 chunk 来自于其他线程的 arena,此时需要找到该 chunk 所属的 heap_info,因为 heap 是按照 1MB 对齐的,因此 chunk 地址低 20 位置为 0 则得到 heap info。
heap (1M aligned) ptr
| |
v v
+--------------+--------+-------+-----+-------+-------------
| heap head | chunk | chunk | ... | chunk | ... ...
+--------------+--------+-------+-----+-------+-------------
第三步:
- 如果 tcache 没满,且大小合适,则将其放到 tcache 中。
- 如大小落在 fastbin 范围中,放入 fastbin 中。
- 将前后的 chunk 合并,如果和 TOP 相邻合入 TOP,否则放到 unsorted bin 中。
- 如果 TOP chunk 大于 THRESHOLD 6MB,尝试 trim。
free 的整体顺序:
thread cache bins -> fastbins -> unsorted chunks
trim 是为了尽快释放掉目前不再使用的内存。如果是 main arena,则移动 brk 将内存还给操作系统。
main arena 使用 sbrk 申请内存,只能释放与 brk 相邻部分的内存。
如下,当前 heap 中有两块空闲的内存,但只能通过调整 brk 来释放掉和 brk 相邻的内存块。
| |
+-----------+ <-- brk
| free | | |
+-----------+ +-----------+ <-- brk
| x x x x | | x x x x |
| x x x x | | x x x x |
| x x x x | | x x x x |
+-----------+ +-----------+
| free | | free |
+-----------+ +-----------+
| x x x x | | x x x x |
| x x x x | | x x x x |
如果不是 main arena 则判断当前 heap 中的 chunk 是否完全释放了。如果是,则 munmap 掉这块内存。
主动回收内存
用户可以使用 malloc_trim 来主动清理不使用的内存,这个和上面介绍的 free 中执行的清理不同。这里的 trim 是一个比较重的操作。
malloc_trim 会先把 fast bins 中的小 chunk 还到 small bins 中,然后遍历所有 bins,尝试将 chunk 合并,如果发现某个 chunk 空闲内存大于阈值(一个页),则使用 madvise 配合 MADV_DONTNEED 释放物理页。
总结
ptmalloc2 使用多个空闲链表来管理 chunk,将 chunk 按照大小存放在 126 个链表中,这要在分配内存时可以快速找到合适大小的 chunk。对于小的 chunk,链表中的所有 chunk 大小相同,对于大的 chunk,链表中 chunk 按大小有序排列,在分配时使用 best-fit 的分配策略。
每个 chunk 包含 16 字节的元信息,用来记录当前 chunk 的大小和状态,以及空间上相邻的前一个 chunk 的大小。因为有这 16 个字节的元信息存在,chunk 越小,元信息使用的内存占比也就越大。如果你的应用中大量使用小内存块,必须动态构建数、链表都结构的节点,这会导致空间浪费严重。此时可以考虑换别的内存分配器,或者申请大块的内存自己来分配。
主线程中,在 free 时只会 trim 和 brk 相邻的空间。在子线程中只会在整个 mmap 的内存都 free 后才执行 munmap。因此如果你的程序在某个阶段申请了大量内存,而在 free 的过程中也伴随着少量的内存申请,这就很有可能因为存在少量正在使用的内存,而无法 trim,进而导致内存降不下来。
参考资料: