Redis 集群方案及各自的优缺点
在线服务大多追求极致的响应速度,redis 作为内存型数据库,在速度上有着巨大的优势,这让它成为追求极致速度的系统中不可缺少的组件。单个 redis 实例存储量和请求处理能力受限于单机性能,随着用户量的增长和用户数据的积累,需要存储的数据越来越多,峰值请求量越来越大,构建 redis 集群成为必然选择。
redis 集群的核心思路是将所有的 key 分布到不同的 redis 实例上,如此可以由多个 redis 实例提供服务,提升存储量和请求处理能力。在实现中 redis 集群需要考虑数据的分片存储与访问、数据的持久化、容灾、集群的扩缩容、集群动态变更等问题。不同的集群方案对以上问题的解决程度不同。
曾经或现在业界主流的 redis 集群方案有:客户端分片、代理(twemproxy)、codis、redis cluster,本文将分析以上方案的实现原理和优缺点。
1. 客户端分片
最简单的集群实现方案,就是部署多个 redis 实例,每个 redis 实例只存储全部数据的一部分。数据如何划分呢?可以将全部数据划分为多个分片,每个 redis 实例负责部分分片。在 KV 存储场景下,通常基于键来划分分片。比如将数据分为 1204 个分片,可以执行 hash(key) % 1024 将 key 映射到 [0, 1023] 范围内,然后将此 key 存储在对应的 redis 服务(分片)中。
客户端分片的方案需要在客户端实现由 key 到数据分片的映射,最简单的方案是客户端记录所有分片的地址,所有客户端使用相同的哈希算法将 key 映射到对应的分片。
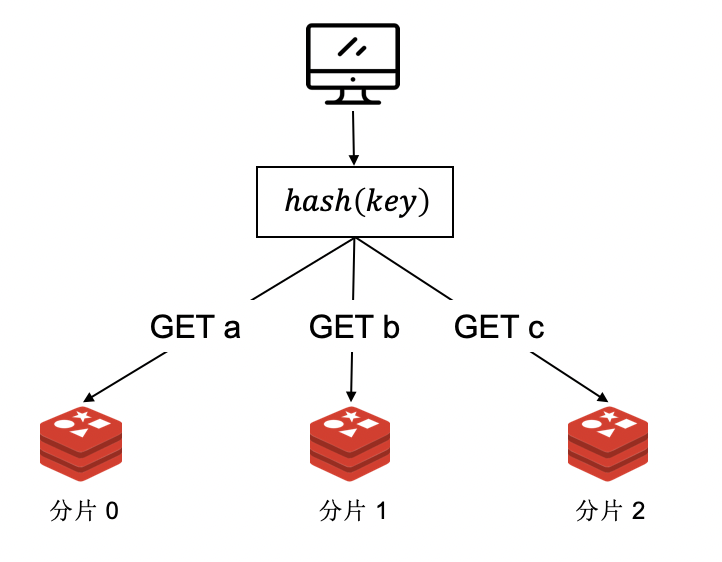
客户端分片是很直观的思路,实现起来很容易,只需要启动多个 Reids 实例,至于该访问那一个 redis 实例,这交给客户端来处理。一般策略是使用一致性哈希算法来实现 key 到分片的映射。
该方案的缺点很明显,首先客户端需要知道所有分片的信息,分片信息变更后,还需要有办法通知客户端,客户端需要更新一致性哈希的哈希环的状态。另外,可能还行需要在不同分片间搬移数据。总之,在客户端执行分片需要客户端做不少工作,维护的难度较大。
一致性哈希算法
为了避免增删节点后导致映射大幅度变化,一般采用一致性哈希算法,比较典型的一致性哈希算法是 ketama。
考虑存在 3 个分片,可以将这 3 个分片映射到 120 个虚拟槽上。每个分片负责 40 个虚拟槽,此时如果增加了分片,只需要匀一份虚拟槽给新增的节点即可。通过增加 slot 这个抽象,可以解耦 key 和 redis 节点的映射关系。
key -> slot -> redis node实际做法是将 server 的地址做哈希,映射到 0~120 上,一个地址可以增加后缀映射多次:
hash("127.0.0.1:6379_1") % 120 = 12
hash("127.0.0.1:6379_2") % 120 = 55
...将这些数字放到一个环上,这样环每一个数字都映射到一个 server:
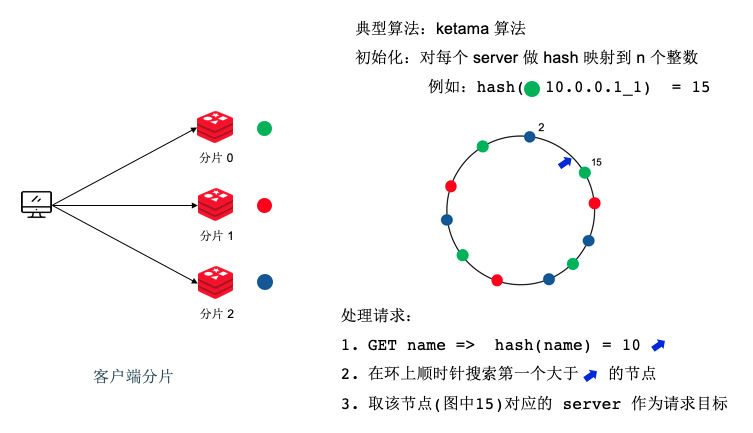
之后来一个请求 GET name 后,可以将 name 使用哈希算法映射到一个 0~120 的数字上:
hash(name) % 120 = 7然后在环上寻找第一个大于 7 的数字,即 15。这个 15 对应 server 就是该存储 key 的 server。
使用一致性哈希算法,可以有效避免增删节点后影响其他节点,每次增加删除节点后,受影响的只会是部分 slot,这样缓存失效的面积不会很大。
2. 代理
为了对客户端隐藏数据分片的事实,让客户端感觉是在和单个 redis 实例进行通信,一种做法是引入代理层。代理层位于客户端和 redis 集群之间,客户端的请求发送到 Proxy 上,Proxy 根据 key 来选择分片。客户端就像是和单个 redis 实例通信一样,对集群的存在无感,这样业务层用起来就很方便。
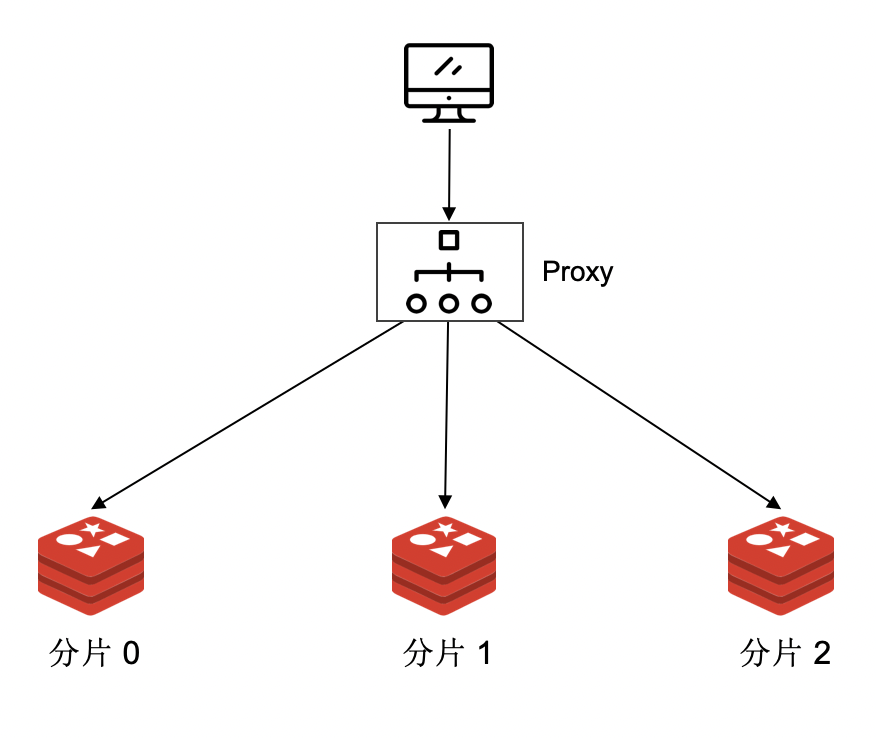
基于代理的集群实现方案对客户端屏蔽了数据分片的事实,让客户端更加简单。在维护上,代理层通常和 redis 集群由一个团队维护,升级与更新都更加灵活(让用户升级客户端是代价很高的事情),同时可以在代理层做很多事情,比如过滤掉不安全的命令,做身份认证,做流量统计等等,做热 key 访问优化等等。
代理会降低集群性能吗?
如果让一个代理负责所有的分片,这会导致 Proxy 成为瓶颈。但因为 Proxy 是无状态的,可以部署多个 Proxy 来提供服务。
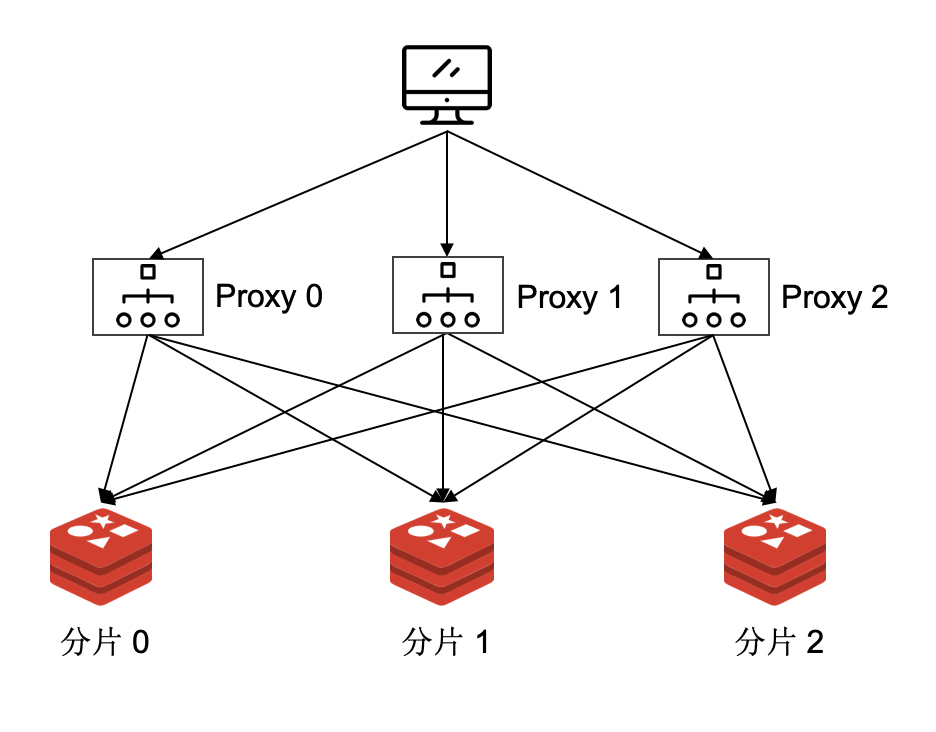
增加一层代理会导致请求链路变长,与直连 redis 相比,客户端的请求耗时必然增加。这是否意味着引入代理后,集群的性能会降低呢?答案是否定的。引入代理后,只有 Proxy 与 redis 连接,redis 上的连接数大幅度降低,而且通常是长连接。多个客户端的请求会在 Proxy 层汇总,通过少量的连接批量发送给 redis。Proxy 发送给 redis 的这些命令会批量发送到 redis,redis 在 Pipeline 模式下性能会大幅度提升。
为什么批量发送会提升 redis 的性能呢?考虑有 1000 个客户端直连到 redis 上,并各自发送一条命令,redis 需要在 1000 个连接上各执行一次 socket 读操作来读取这 1000 条命令,执行得到结果后,需要再执行 1000 次 socket 写操作,将结果发送给 1000 个客户端,以上过程共执行了 2000 次 IO 操作。再考虑另一种情况,通过一条连接发送 1000 条命令的情况,redis 一次 IO 操作就能读取到 1000 条命令,执行完 1000 条命令后,再执行一次 IO 操作就能将结果写回,以上过程只进行了两次 IO 操作。批量发送命令之所以能够提升 redis 的性能,其原因是减少了系统调用的次数,redis 仅需要执行少量的 IO 操作。关于 Pipeline 的详情介绍请参阅 Using pipelining to speedup redis queries。
redis 端的 IO 操作减少了,但是 Proxy 端却没有减少,这意味着之前由 redis 负担的 IO 读写操作转移到了 Proxy 端。但可以部署多个 Proxy 将此消耗分摊。可见,引入 Proxy 后在单个用户的视角中,响应时间降低了,但得益于 redis 批量处理的高效性,对于整个集群而言,吞吐量不见得会下降。
开源实现
由 Twitter 开源的 Twemproxy 是一个 redis 和 memcached 的代理,它应用的很广,性能很好。但是 twemproxy 有很多功能不支持,比如阻塞命令、发布订阅、事务。
twemproxy
twenproxy 提供了 distribution 选项,这个选项配置了 key 的分布模式。它有以下几种取值:
ketama:使用一致性哈希算法,来将 key 映射到 redis 实例。当节点出现故障的时候,可以自动屏蔽失效节点,基于一致性哈希的特性可以实现高可用,通常用在缓存场景下。modula:对 key 的哈希值取余映射到 redis 实例。无法实现高可用,如果有节点出现故障就无法工作。可以进行双倍的扩缩容,因为双倍扩散后,新旧映射关系之间存在关系,可以进行数据的迁移。但迁移数据需要依赖额外的工具,数据迁移完成后需要重启 twemproxy 才能生效。slot:将 key 映射到 16384 个 slot 上,每个 slot 又会映射到一个 redis 实例上。通过key => slot => server间接的方式实现 key 到 server 的映射。使用这种方案,在扩缩容的时候比较容易,只需要增加或减少实例,并迁移 slot,更新映射表即可。
twemproxy 实现了代理功能,但对于可靠的集群这还远远不够。一个可靠的集群方案还需要包含更多其他的组件,比如配置管理组件、数据迁移组件、扩缩容组件等等。
代理的优点
- 可以水平扩缩容,增加或者删除节点后,只需要先进行数据迁移,然后变更拓扑,用户无感。
- 客户端无需做改造,仅仅需要处理负载均衡。
代理的限制
采用集群后数据被分散在多个分片上,虽然 proxy 可以给客户端提供一种像是操作单个 redis 的感觉,但毕竟不是单机版 redis,在使用上存在一些限制:
多 key 命令的限制
有的 redis 命令包含多个 key,这些 key 可能分布在多个数据分片上,比如 del a b、rename key newkey。对于前者 Proxy 可以将其拆分成 del a 和 del b 两条命令并将其发送到 a 和 b 所在的分片上,最后将汇总结果汇总起来。但对于后者 rename key newkey 命令,如果两个 key 不在同一个数据分片上,那就需要将原 key 删除,并将其 value 使用新的键名插入到另一个数据分片,这代价就比较大了。因此,在基于 proxy 实现的集群中,使用此类命令时要求两个 key 处于同一个 slot 中。
让多个 key 被映射到同一个分片上,这难道要根据 Proxy 采用的 hash 算法反向寻找满足要求的 key 吗?这也太不科学了。为了让多个 key 被映射到同一个数据分片,Proxy 层提供了一种解法,那就是 hash tag。在传入 key 的时候,给 key 关联一个 hash tag,如 set key{tag} 1 ,这里 {tag} 是 Proxy 定义的一种语法,使用这种方式传递 key,Proxy 会使用 tag 来计算 hash。比如这两条命令 set name{t} jack、set age{t} 23 ,使用了相同的 hash tag,那么这两个 key 必然被存在同一个数据分片上。
阻塞命令的限制
如 blpop 这样的阻塞命令会独占一条连接,在使用 Proxy 的集群模式下,因为 Proxy 到 redis 之间的连接会被很多客户端复用,因此要想支持如 blpop 这样的阻塞命令,需要在 proxy 和 redis 之间单独创建一条连接。
3. codis
codis 是基于代理实现的一种 redis 集群化方案,在 redis cluster 出现之前它就被广泛应用,因为它处理代理以外,还提供了一揽子的工具,可以搭建一个功能比较完善集群。
整体架构
下面是 codis 的整体架构图,来自于 codis 的代码库。
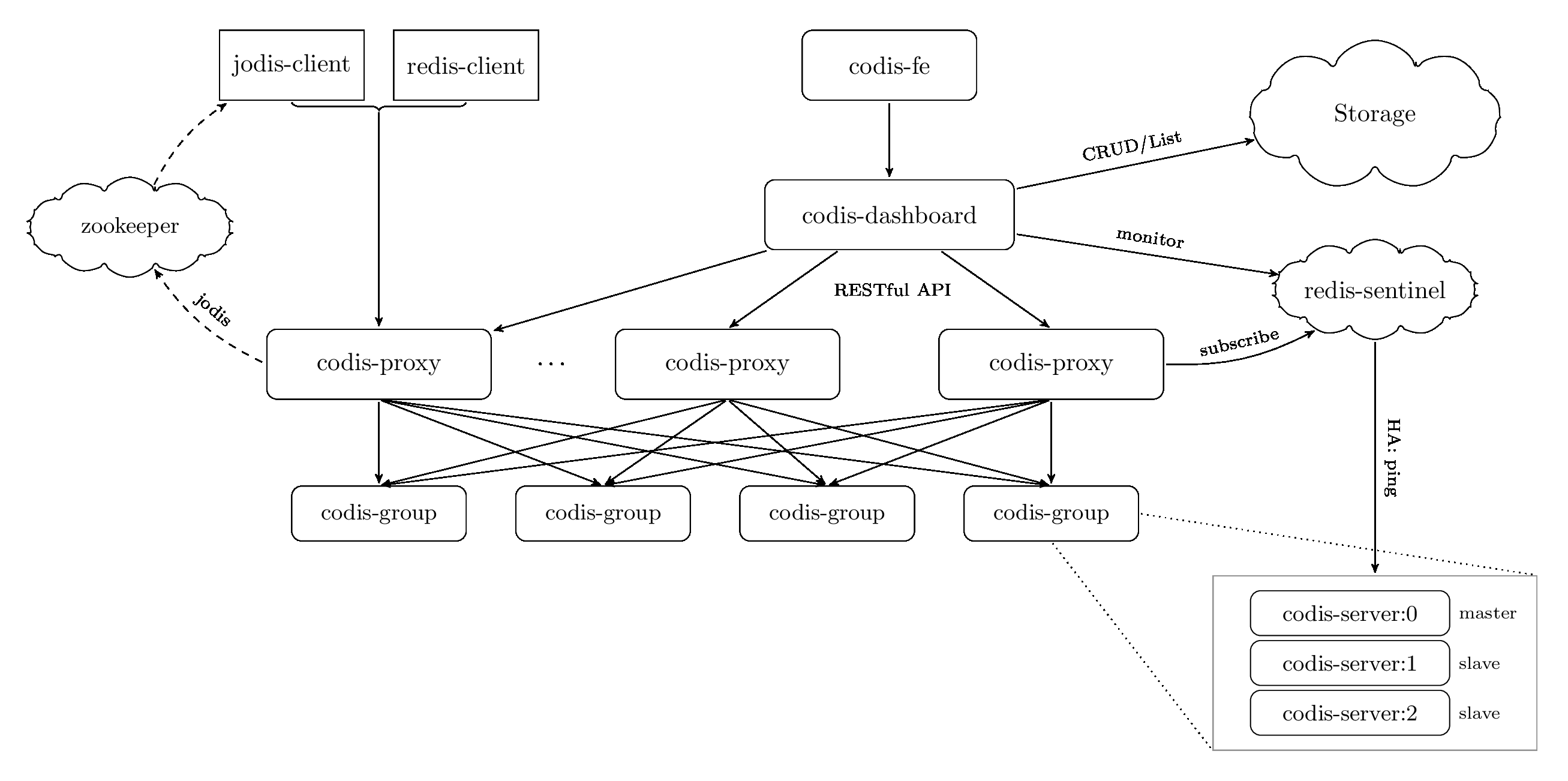
codis 本质上还是基于代理的一种集群实现,不过它做了更多事情。包含许多组件:
- codis-group:这是一主两从的 redis 实例组,右下角有它放大的图。这里叫 codis-server 而不是 redis-server 是因为这里为了适配 codis 的架构,codis 的开发者对 redis 做了部分修改。
- codis-proxy:它就像 Twemproxy 一样,对请求和响应进行转发,不过它做了更多事情,比如提供 HTTP 接口反馈 proxy 的状态,供 codis-dashboard 查询。
- codis-dashboard:这个 codis-dashboard 是集群管理工具,它支持在线扩缩容、数据迁移,以及对 redis 实例组的监控等。上图右侧的 Storage 是dashboard 中需要持久化存储的数据。
- codis-sentinel:是 codis-group 的哨兵,当它发现 codis-group 状态变化后,比如主从切换了,这个时候会通知代理,并自动更新配置。。
- codis-fe:这是 codis 的前端控制面板,通过它可以操作 dashboard。
- Jodis-client: 是适配 codis 的 redis 客户端,可以看到 client 在监听一个 zookeeper。当 proxy 状态改变了,比如新增或者删除了 proxy,就会往 zookeeper 的某个节点上写数据通知所有客户端,这样客户端就能拿到最新的 proxy 信息了。
codis 在代理架构的基础之上增加了不少设施,让整个 codis 集群支持了扩缩容、数据迁移、高可用等功能。
数据分片方案
在 codis 集群中将所以数据分为 1024 个 slot,每个 codis-group 负责一个或多个 slot。路由的时候,先将 key 散列到 slot,然后在找到负责该 slot 的 codis-group,而不是直接将 key 映射到 codis-group 上。这样做的好处是不会因为新增和删除了 codis-group 导致全部映射都失效。想一想,如果某个 codis-group 需要回收,那就将这个 codis-group 负责的 slot 分配给其他 codis-group 负责。如果增加了,那就从别的 codis-group 里面拿一些 slot 分配给这个新添加的 codis-group。
假如现在有 9 个 slot,划分为 3 个分片,每个分片负责 3 个 slot.
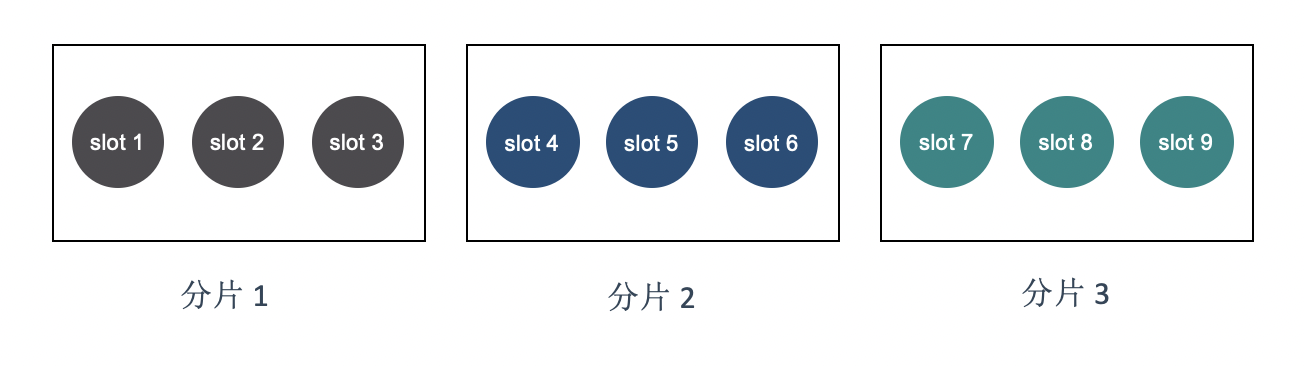
现在增加了一个 分片 4,此时可以移动两个 slot 给分片 4,比如将 slot 6 和 slot 9 移动到分片 4 上面。
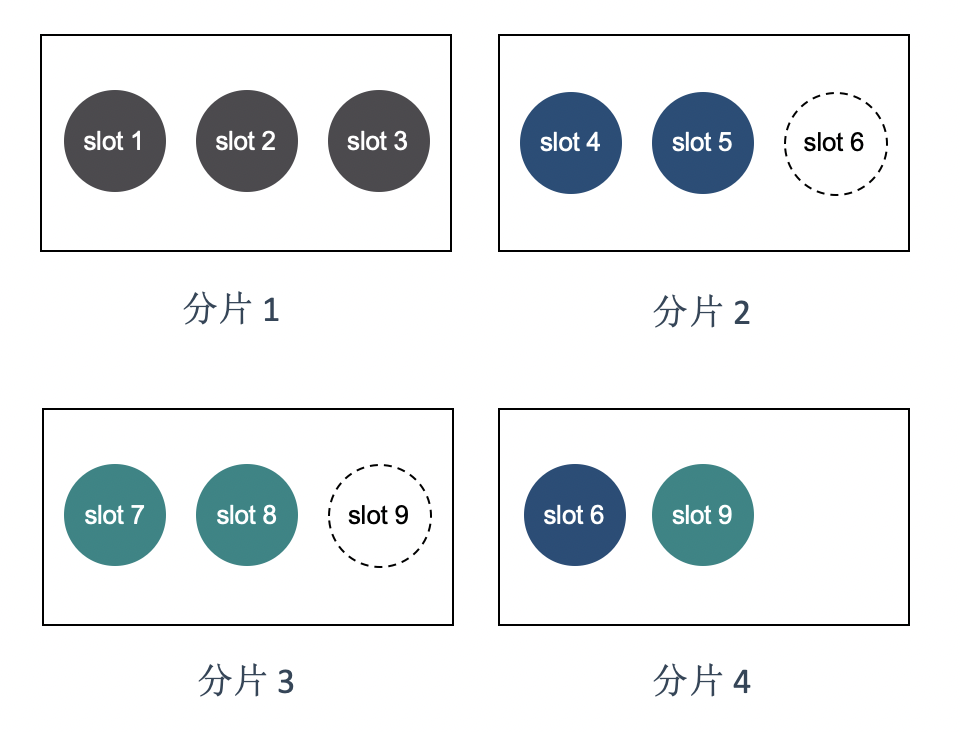
假如后来缩容去掉了分片 1,只需要将分片 1 负责的 slot 分配给其他分片即可:
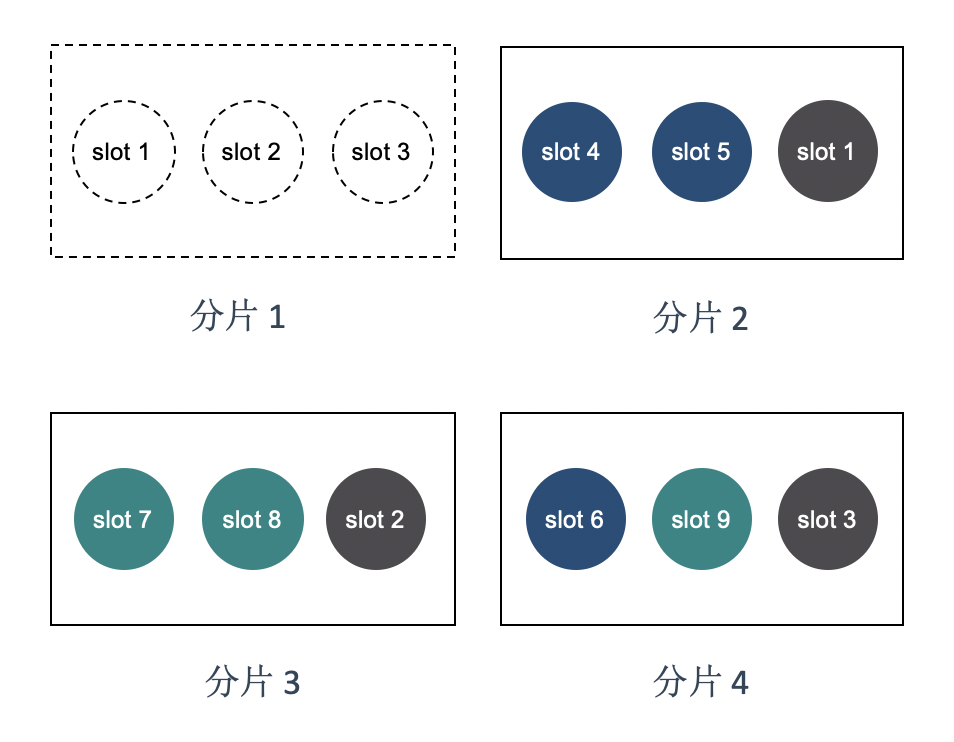
可以看到每次增加或者删除 server,需要移动的数据都是比较少的。这就是使用 slot 的好处。如果直接将 key 映射到 server 上,新加入一个 server 都不知道怎么移动数据,因为 hash 算法的基础(redis 服务的数量)已经被破坏了。
扩缩容
codis 可以在线扩容,扩容的过程不需要停机,不影响客户端的访问。在线扩缩容非常有用,比如快到某个节日了,流量会激增,集群性能无法满足需求,这时可以动态增加节点提升集群性能,节日过去后,流量下来了,可以减少节点,避免浪费。这扩容和缩容对业务没有任何影响。
扩缩容的时候由 dashboard 得出新的 slot 信息,然后通过 Proxy 进行数据的搬移,搬移完成后,变更 slot 的映射信息。
codis 存在的问题
codis 提供了一整套的集群解决方案,在 redis cluster 出现之前,是很理想的 redis 集群方案,且得到了广泛的应用。但为了适应 codis 的设计,codis 需要对 redis 进行了改造,因此想要使用 codis 就需要使用其内置经改造后的 redis 版本。为了能够使用 redis 的最新功能,就需要 codis 及时跟进 redis 的更新,实际上 codis 使用了 redis 3.2 版本,并且后期没有再升级。因此使用 codis 就只能使用较低版本的 redis。
目前,codis 已经不再维护了,已经不再推荐使用它了。这里提 codis 是为了考古,为了了解 codis 集群方案中的好的设计。
4. redis cluster
redis 从 3.0 版本后提出了不依赖其他组件的集群方案,叫做 redis cluster。它不需要使用代理,客户端直接和 redis 通信,可以构建包含高达 1000 节点的 redis 集群。该方案由 redis 社区众多开发者共同维护。经过多年的迭代,目前已经趋于稳定,使用该方案的用户越来越多。
集群结构
redis cluster 集群架构中,数据被划分为 16384 个 slot。相比于 codis,redis cluster 划分的 slot 更多,这可以让数据更加均匀地分布在多个分片上。集群中的多个 redis 实例利用 gossip 协议相互通信,传达自身的信息给对方。这样集群中的每一个 redis 实例都知道其他节点负责的 slot 的信息。另外每个节点还可以有一个从节点,集群中的其他节点可以充当哨兵的角色,在某个节点出故障后,执行主从切换。
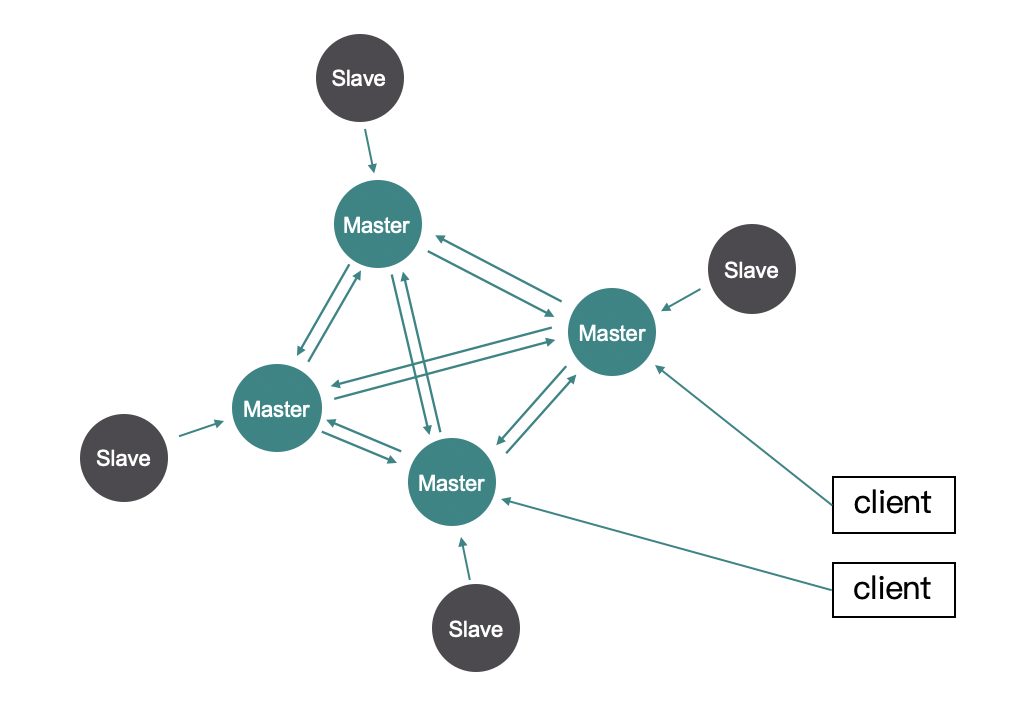
客户端如何使用集群
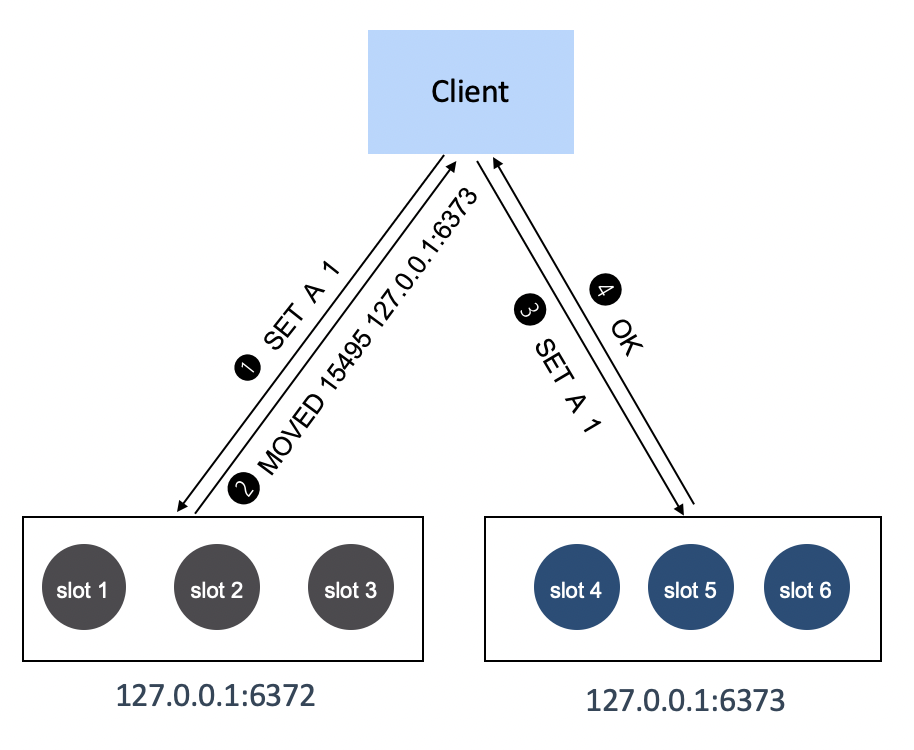
当客户端需要访问 redis 的时候,它可以使用同 redis 端相同的哈希算法把 key 映射到 16384 个 slot 中的一个,但是它不知道对应的 slot 该由哪个 redis 负责。客户端干脆随便找一个节点发送命令,如果这个 key 对应的 slot 不由这个节点负责,那么该节点会查一下这个 slot 由谁负责,并返回一个 MOVED 错误消息给客户端,错误消息中包含了目标节点的地址:
127.0.0.1:6372> GET A
(error) MOVED 15495 127.0.0.1:6373
# 错误消息的意思是 A 所属的 slot 是 15495 对应的 server 地址是 127.0.0.1:6373客户端收到消息后,会根据重定向信息重新发起连接,这个时候就能访问到正确的节点了。另外客户端可以通过 cluster slots 命令主动从服务端拉取 slot 到 server 的映射关系,所以重定向其实不会经常发生,只有当客户端没有及时更新最新的 slot 信息时候才会发生重定向。
如下是发送 cluster slots 后的结果,其中给出的信息是: [slot_start, slot_end] => node
127.0.0.1:6372> cluster slots
1) 1) (integer) 0 <-- 起始 slot
2) (integer) 5460 <-- 结束 slot
3) 1) "127.0.0.1" <-- IP
2) (integer) 6371 <-- PORT
3) "efdd33889f1c9414a779cb05ae90f22b8815c0d1" <-- node id
2) 1) (integer) 5461
2) (integer) 10922
3) 1) "127.0.0.1"
2) (integer) 6372
3) "9a50a10f4fca2ac6231753cdbed33cf70ca9a3e5"
3) 1) (integer) 10923
2) (integer) 16383
3) 1) "127.0.0.1"
2) (integer) 6373
3) "d32aa03782f5512f149b24b57d924c0c61dc2065"就算客户端上的映射信息和实际信息不一致了,那也只会触发一个重定向,最终依然会访问到正确的节点。
redis cluster 把集群方案和存储揉在了一起,导致 redis 代码复杂程度激增。另外,使用 redis cluster 需要客户端支持 MOVE/ASK 等语义,这需要升级客户端。因为让业务方升级客户端比较困难,所以 redis labs 实现了 redis cluster Proxy ,它也是一个 redis 的 代理,它屏蔽了 redis cluster 的实现细节,让客户端感觉自己是在和单机版 redis 通信,这样客户端无需升级即可使用 redis cluster。
slot 迁移
如果新增和删除了分片,就涉及到数据的迁移,数据迁移的单位是 slot。在 redis cluster 中,slot 移动可以在线进行,不会对服务有什么影响。redis cluster 中 slot 迁移是通过 cluster setslot 和 migrate 系列命令完成的。前者用来修改 slot 的映射信息,后者用来在 redis 节点之间搬移键值对。
关于迁移的细节 redis 的文档 cluster setslot 中已经做了说明,宏观来看就是先通知迁移双方迁移详细信息(包含待迁移的 slot 信息,迁移对端的节点编号),然后对 slot 中的所有键值对逐个迁移。
=> 迁移详细步骤(不关心细节的可跳过)
假如要将 source 节点中的一个 slot 迁移到 target 节点,下面是详细的过程。
第一步:给 source 节点和 target 节点发消息,告知迁移的双方的信息。下面 source> 表示使用 redis-cli 连接上 source 节点,向其发送命令。
target> cluster setslot <slot> importing <source_id>
source> cluster setslot <slot> migrating <target_id>以上两个命令的顺序不能交换,必须先设置目标节点再设置源节点。如果反过来,在这两个命令执行的间隙,有对应该 slot 的命令发送到源节点上去,源节点将这条命令重定向到目标节点,但目标节点因为尚未设置该 slot 的 importing 状态,又会将这条命令重定向到源节点。(见后文在 slot 迁移的过程中保证服务可用)。
第二步:从 source 节点中获取 slot 对应的多个 key:
source> cluster getkeysinslot <slot> <count>第三步:将获取的 key 移动到 target 节点中:
source> migrate <target_ip> <target_port> <key> <db> <timeout>migrate 命令将 key 从原节点迁移到目标节点,且能够保证原子性,迁移完成后会从源节点中删除迁移完成的 key。这里的原子,就是在没有迁移完 key 之前该节点不执行其他命令。
第四步:重复前面第二步和第三步,直到 slot 中的所有 key 都已经迁移完成。
第五步:迁移工具向集群中其他节点发送 slot 更新的消息,因为各节点之间会交换信息,因此其他节点很快就也会得到了更新后的 slot 分布状态。
target> cluster setslot <slot> node <target_id>
source> cluster setslot <slot> node <target_id>
other node> cluster setslot <slot> node <target_id> # 可选给多个其他主节点也发送 slot 的更新消息是为了让 slot 的更新尽快同步到整个集群,其实不发也是可以的。甚至随便给一个节点发送 slot 更新也是可以的。不过一般也是先给 target 设置,然后给 source 设置,然后其他节点设置。因为如果先给 source 设置了,但尚未给 target 设置。这个时候 key 处于这个 slot 的命令被发到 source 上,source 会发送 MOVE 错误。客户端收到 MOVE 错误后,会访问 target 节点,target 因为还没有收到更新后的 slot,有会将其重定向到 source 上。(参见后文在 slot 迁移的过程中保证服务可用)。
在 slot 迁移的过程中保证服务可用
假如在对某个 key 所在的 slot 迁移的过程中客户端读取了这个 key,这种情况如何处理呢?
首先,客户端根据自己已知的 slot 信息,从 source 节点读取该 key,假如这个时候 key 尚未迁移出去,还存在于 source 节点中,那么直接处理这个 key。如果没在 source 节点中,因为此时正在数据迁移,有可能把这个 key 迁移到目标节点了,因此 source 节点会让客户端去 target 节点试试,它会返回一条 ASK 错误,其内容大致如下:
127.0.0.1:6379> GET name
(error) ASK 143 127.0.0.1:6379 这个错误信息中 143 是该 key 的 slot 号,后面则 target 节点的 IP 和 端口。如果客户端向这个 target 节点发起请求,因为这个时候数据还没有迁完,143 号 slot 还没有分配给 target 节点,target 节点会认为这个 slot 不属于自己负责,因此返回 MOVED 错误,让客户端再去访问负责 143 号 slot 的节点,即 source 节点,这不就死循环了。
为了破解这个循环,在收到 ASK 错误后,客户端需要先给 target 节点发一个 ASKING 命令,然后在发起请求。target 节点收到 ASKING 后,会检查当前是否正在把 143 号 slot 迁移到自己这里(回忆下,在数据迁移之前有通过 cluster setslot 设置 source 和 target 正在迁入和迁出的 slot,见前一节slot 迁移的第一步 ),如果是,那么该客户端的下一次请求无论如何不会重定向。
为什么要加一个 ASKING 命令,为什么不直接看看这个 key 对应的 slot 是不是正在迁入呢?如果是,直接查一下存不存在不就好了?
redis cluster 的优缺点
redis cluster 由 redis 社区共同维护,从 redis 3.0 起,经过了多年的发展和完善,已经在很对生产环境得到应用,具有较高的可用性,而且出现问题后容易寻找解决方案。使用 redis 提供了 redis-cli 工具,可以让集群的部署变得简单,还可以比较容易地管理集群。另外,不同于 proxy 方案,redis cluster 打包了数据迁移高可用等方案,整个集群方案需要的组件更少,部署更加容易。
其缺点是普通的 redis 客户端不支持 redis cluster 模式,支持 redis cluster 的客户端需要可以识别 MOVED、ASK 等错误消息。要切换到 redis cluster 上, 需要升级客户端,这在某些场景下可能不是很容易。为了让用户在不升级客户端的情况下也可以使用 redis cluster,redis labs 开发了一个代理 redis-cluster-proxy,屏蔽了 redis cluster 的实现细节,现有的 redis 客户端可以通过 proxy 来使用 redis cluster。
部署 redis cluster 集群
下面描述创建 redis cluster 的过程:
第一步:新建目录
新建多个目录,放置集群的配置文件、AOF、RDB 等等
$ mkdir {7001,7002,7003}
$ cp redis.conf 7001/redis.conf
$ cp redis.conf 7002/redis.conf
$ cp redis.conf 7003/redis.conf 第二步:修改配置项
更改 7001/redis.conf 中的下列配置项,其他保持不变,其他配置文件也做相应的修改。
bind 0.0.0.0
port 7001
cluster-enabled yes
cluster-config-file nodes-7001.conf
appendonly yes
daemonize yes
logfile /home/wy/redis/7001/redis-server-7001.log # 根据实际情况修改第三步:启动服务
使用配置文件启动 redis Server,此时各 redis Server 还感受不到其他 redis 的存在。
$ redis-server 7001/redis.conf
$ redis-server 7002/redis.conf
$ redis-server 7003/redis.conf第四步:构建集群
使用 redis-cli 将三个 redis Server 连接成集群,输入命令后首先会打印出 slot 的分布情况,如果接受 redis 给出的分片策略,输入 yes。之后,redis-cli 就会自动发送 cluster meet 命令来建立多个 redis Server 之间的联系,最后检查是否所有 slot 都被覆盖到,最终完成集群的搭建。
$ redis-cli --cluster create 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003
>>> Performing hash slots allocation on 3 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
M: fec616ad274f8a6b66fd9ad0449cffd588b0ebc5 127.0.0.1:7001
slots:[0-5460],[7365] (5461 slots) master
M: 7688da4e21cdde06191bd01d0331aaee487a4453 127.0.0.1:7002
slots:[5461-10922] (5462 slots) master
M: ecffc589f69622e43dde38f51b684e36edc79d7d 127.0.0.1:7003
slots:[7365],[10923-16383] (5461 slots) master
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending cluster MEET messages to join the cluster
Waiting for the cluster to join
.
>>> Performing cluster Check (using node 127.0.0.1:7001)
M: 9977385890dacaabd17f6f7fb0fd52fd14716bea 127.0.0.1:7001
slots:[0-5460] (5461 slots) master
M: 759dd758501c1a951689c03535398f3b39df62fc 127.0.0.1:7003
slots:[10923-16383] (5461 slots) master
M: 5623148ad0b27f012774256b9012d13f4e52cde2 127.0.0.1:7002
slots:[5461-10922] (5462 slots) master
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.redis cluster 中,任何一个主节点宕机后,整个集群就处于不可用的状态了。因此,可以给每个节点加上几个从节点。
$ redis-cli --cluster create 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 \
127.0.0.1:7004 127.0.0.1:7005 127.0.0.1:7006 --cluster-replicas 1
>>> Performing hash slots allocation on 6 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 127.0.0.1:7005 to 127.0.0.1:7001
Adding replica 127.0.0.1:7006 to 127.0.0.1:7002
Adding replica 127.0.0.1:7004 to 127.0.0.1:7003
>>> Trying to optimize slaves allocation for anti-affinity
[WARNING] Some slaves are in the same host as their master
M: c72c29e03384ab0f9626a3527d35eb123b5ed375 127.0.0.1:7001
slots:[0-5460] (5461 slots) master
M: fb6f0d547be0afd4b3ae563e612e1fe5581644df 127.0.0.1:7002
slots:[5461-10922] (5462 slots) master
M: 59f7079f18de9c9f6525bcc62cad282c32d657f0 127.0.0.1:7003
slots:[10923-16383] (5461 slots) master
S: 71c671e9324b62b8e60dec15712c8ba5523a36ef 127.0.0.1:7004
replicates fb6f0d547be0afd4b3ae563e612e1fe5581644df
S: d2f79498801c2182b00f8fdb34b2a450d13ce65b 127.0.0.1:7005
replicates 59f7079f18de9c9f6525bcc62cad282c32d657f0
S: d5604afcf3a66db211707d7ce69610eea4ae4ecb 127.0.0.1:7006
replicates c72c29e03384ab0f9626a3527d35eb123b5ed375
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending cluster MEET messages to join the cluster
Waiting for the cluster to join
>>> Performing cluster Check (using node 127.0.0.1:7001)
M: c72c29e03384ab0f9626a3527d35eb123b5ed375 127.0.0.1:7001
slots:[0-5460] (5461 slots) master
1 additional replica(s)
M: 59f7079f18de9c9f6525bcc62cad282c32d657f0 127.0.0.1:7003
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
S: d5604afcf3a66db211707d7ce69610eea4ae4ecb 127.0.0.1:7006
slots: (0 slots) slave
replicates c72c29e03384ab0f9626a3527d35eb123b5ed375
S: d2f79498801c2182b00f8fdb34b2a450d13ce65b 127.0.0.1:7005
slots: (0 slots) slave
replicates 59f7079f18de9c9f6525bcc62cad282c32d657f0
S: 71c671e9324b62b8e60dec15712c8ba5523a36ef 127.0.0.1:7004
slots: (0 slots) slave
replicates fb6f0d547be0afd4b3ae563e612e1fe5581644df
M: fb6f0d547be0afd4b3ae563e612e1fe5581644df 127.0.0.1:7002
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.从上面的日志中可以看出,现在没有主节点都有一个从节点,此时 kill 掉一个主节点,整个集群依然可用。