Redis 的部署模式
Redis 有 4 种常见的部署模式,分别是:单点(Standalone)、主从(Master-Slave)、哨兵(Sentinel)、集群(Cluster),本文将描述这 4 种模式,并分析其优缺点。
1. 单点模式
单点模式,即只有一个 Redis 实例,这是最简单的部署方式,Redis 的容量受限与宿主机,无法做到高可用,无法实现读写分离,能够承受的流量有限。
2. 主从模式
主从模式下,一个 Redis 作为主节点,另外一个或多个 Redis 作为从节点。写入主节点中数据的会源源不断地同步到从节点中,如此以来,从节点上有主节点数据的副本。主节点上可以进行读写操作,从节点只能进行读操作。为了避免给主节点操作太大压力,常常让主节点只处理写请求,从节点上处理读请求。
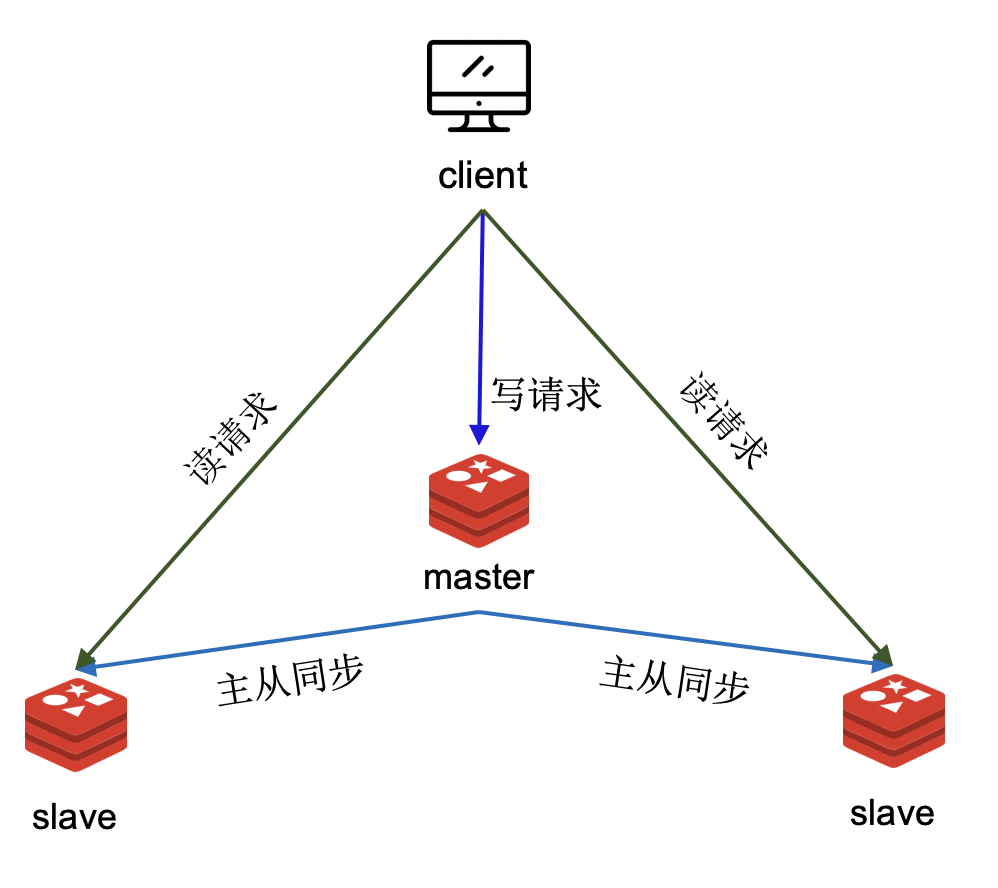
使用主从模式,可以实现读写分离,提高读写吞吐量。但是因为写入主节点中的数据需要一定的时间才能同步到从节点,因此可能会在从节点上读到旧数据,存在数据不一致的问题。另外,如果主节点宕机了,那么整个 Redis 服务还是不可用了,因此主从模式不能保证高可用。
优点:
- 增加了数据的安全性,主节点宕机后,数据依然在从节点上存有备份。
- 读写分离,提高读性能,读取操作可以在从节点上进行,但要注意从节点中的数据和主节点不一定一致(因为主从同步存在延迟)。
- 可以提高主节点的性能,主节点只执行写操作,另外因为数据有备份,可以考虑关闭主节点上的持久化。
缺点:
- 没有提供高可用,主节点宕机后,整个 Redis 服务就不可用了。
- 客户端需要知道晓拓扑信息,并基于命令的读写熟悉来访问主从节点,以实现读写分离。
3. 哨兵模式
在主从模式中,既然从节点中包含主节点数据的副本,那么当主节点故障后,可以将从节点提升为主节点接着提供服务,以保证可用性。从节点切换为主节点后,它就需要切换到主节点的工作模式下,可以开始接收读写两类操作,并向其他从节点同步新写入的数据。要实现这种切换,就需要有一个组件来监控这些 Redis 实例,在出现故障的时候完成切换工作。
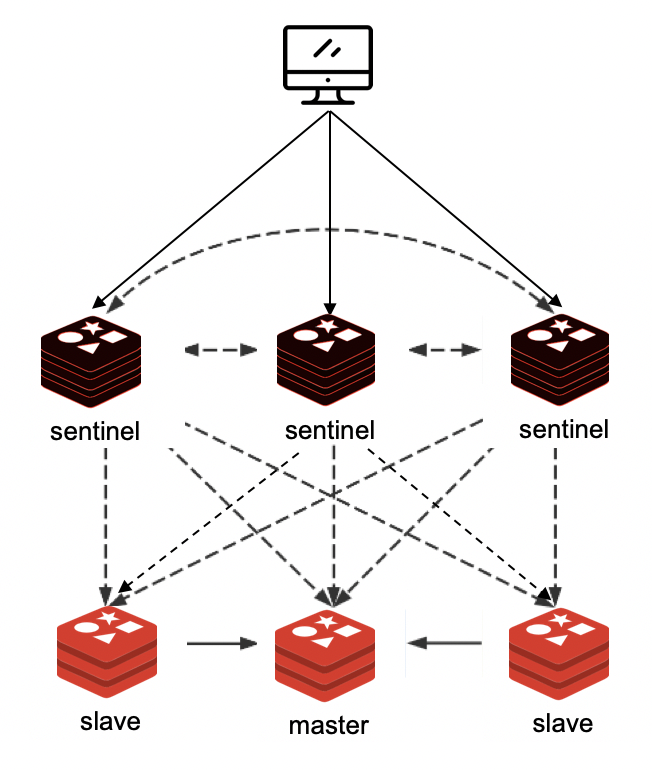
哨兵模式中,存在一些实例充当监控的角色,哨兵和 Redis 主从节点连接并持续探测其可用性。当主节点故障后,哨兵可以将其中一个从节点提成为主节点继续提供服务。
有了哨兵,可以实现自动主从切换,可用性得到了增强。但是哨兵本身也存在单点问题,哨兵本身可能会出故障,导致自动主从切换失效。另外,如果哨兵和 Redis 主节点网络隔离了,它会误认为主节点故障了,此时会将其中一个从节点提升为主节点,这样就出了问题。
为了解决以上问题,可以将多个哨兵构成集群,哨兵之间使用共识算法交互信息,集群中所有哨兵都和 Redis 主从节点连接,并探测可用性。这样个别哨兵故障后,还有其他哨兵可以继续工作。而且之后当一半以上的哨兵认为某个节点出现了故障,才认为这个节点出现故障,这样可以有效解决网络隔离引发的问题。
在使用的时候客户端首先和哨兵建立连接,然后通过哨兵得到主从节点的地址,并订阅主节点变化的通知,如此客户端就可以在主节点变更后得知新的 Redis 主从信息。
优点:
- 哨兵模式实现了高可用,基于 Redis 的主从结构,在故障时候自动提升从节点为主节点。
缺点:
- 复杂性较高,即使是最简单的模型,也包含一个主节点、一个从节点、三个哨兵节点。
- 需要客户端支持哨兵模式,提高了客户端的复杂性。不过主流的库提供了实现。
- Redis 服务的存储容量依然受限于机器的内存。
4. 集群模式
哨兵模式一定程度上解决了可用性问题,通过配置多个 Redis 实例构成主从架构,并使用哨兵监控 Redis 实例的状态,在主节点故障时候进行主从切换。如果从节点出现故障,可以将其屏蔽。如果某个节点恢复了,可以恢复对它的访问。
不过在哨兵模式中,Redis 服务的存储容量依然受限于机器的内存。当需要存储大量的数据时,就必须对数据进行分片。常见的做法是将数据按照 KEY 散列到多个 Redis 实例中。比如将数据分为 1204 个分片,那就可以执行 hash(key) % 1024 得到存储此 key 的 Redis 实例,并访问之。为了保证可靠性,可以继续沿用前面的哨兵模式,不过这里是每一个分片都采用哨兵模式。然后在上面根据 key 来选择分片。
这就引入了一个问题:用户如何知道自己要访问的 key 在那一个分片上?
4.1 客户端分片
客户端分片是指把由 key 得到对应 Redis 分片的操作放在客户端,客户端只需要记录所有分片的地址,并且所有客户端都使用同样的哈希算法,那就可以通过 key 得到对应的分片。
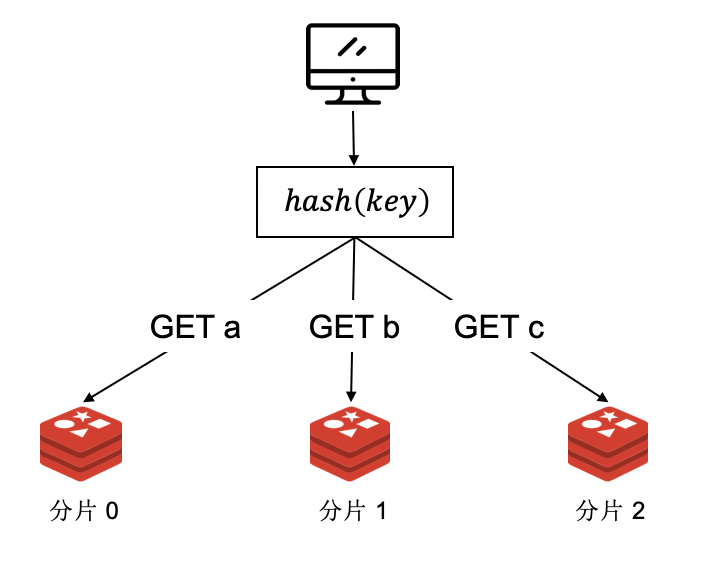
客户端分片是很直观的思路,但存在很多缺点。首先客户端需要知道所有分片的信息,分片信息变更后,还需要有办法通知客户端。如果增加或减少了分片,那么之前建立的映射就会错乱。
4.2 代理
为了对客户端隐藏数据分片的事实,让客户端感觉是在和单个 Redis 实例进行通信,一种做法是引入代理层。代理层位于客户端和 Redis 集群之间,客户端的请求由 Proxy 发送到不同 Redis 分片。分片状态变化后,只需要调整 Proxy 的路由策略,客户端无需做任何操作。这样的方式让客户端更简单,整个 集群的灵活性大大增加。
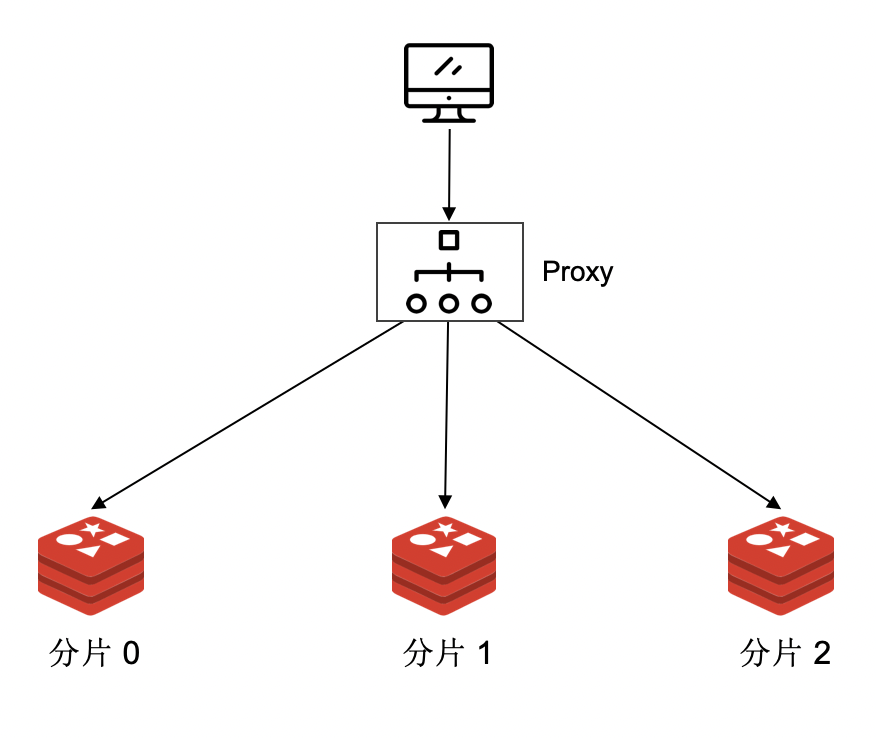
基于代理的集群实现方案对客户端屏蔽了数据分片的事实,让客户端更加简单。在维护上,代理层通常和 Redis 集群由一个团队维护,升级与更新都更加灵活(让用户升级客户端是代价很高的事情),同时可以在代理层做很多事情,比如过滤掉不安全的命令,做身份认证,做流量统计等等。
4.3 Redis Cluster
Redis 从 3.0 版本后提出了不依赖其他组件的集群方案,叫做 Redis Cluster。它不需要使用代理,客户端直接和 Redis 通信,可以构建包含高达 1000 节点的 Redis 集群。
Redis Cluster 集群架构中,数据被划分为 16384 个 slot,集群中每个 Redis 负责部分 slot。集群中的多个 Redis 相互通信,传达自身的信息给对方。这样集群中的每一个 Redis 实例都知道其他节点负责的 slot 的信息。每个节点还可以有从节点,集群中的其他节点还可以充当哨兵的角色,在某个节点出故障后,执行主从切换。
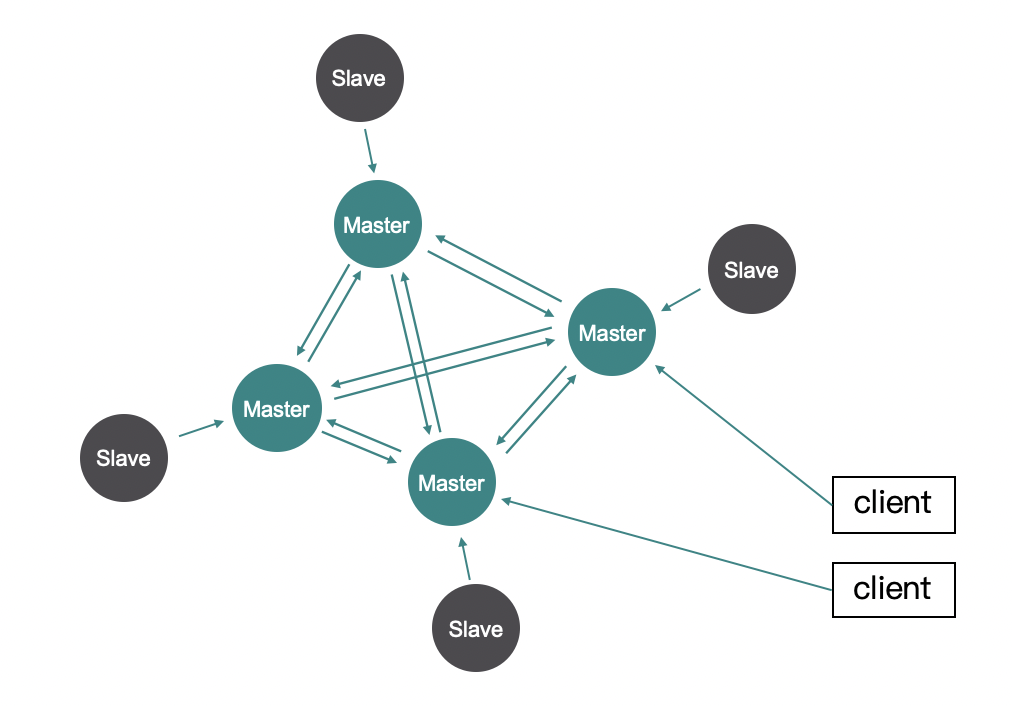
当客户端需要访问 Redis 的时候,它可以使用相同的哈希算法把 key 映射到 16384 个 slot 中的一个。但是它不知道对应的 slot 该由哪个 Redis 负责。客户端可以从已知的某个节点获取,如果这个 key 对应的 slot 不由这个 Redis 节点负责,那么这节点可以查一下这个 slot 由谁负责,并返回重定向消息给客户端。客户端收到消息后,会根据重定向信息重新发起连接。另外客户端会从服务端拉取 slot 到 server 的映射关系,所以重定向不会经常发生。另外,就算客户端上的映射信息和实际信息不一致了,那也只会触发一个重定向,最终会访问到正确的节点。
优点:
- 部署简单,开箱即用,可以水平扩容。
- 客户端直接和 Redis 连接不需要经过一层 Proxy,性能较好。
缺点:
- Redis Cluster 把集群方案和存储揉在了一起,导致 Redis 代码复杂程度激增。
- Redis 节点之间需要传递消息,导致整个集群节点间关系复杂,出问题不易排查容易。
- 需要客户端的支持,业务方需要升级客户端。